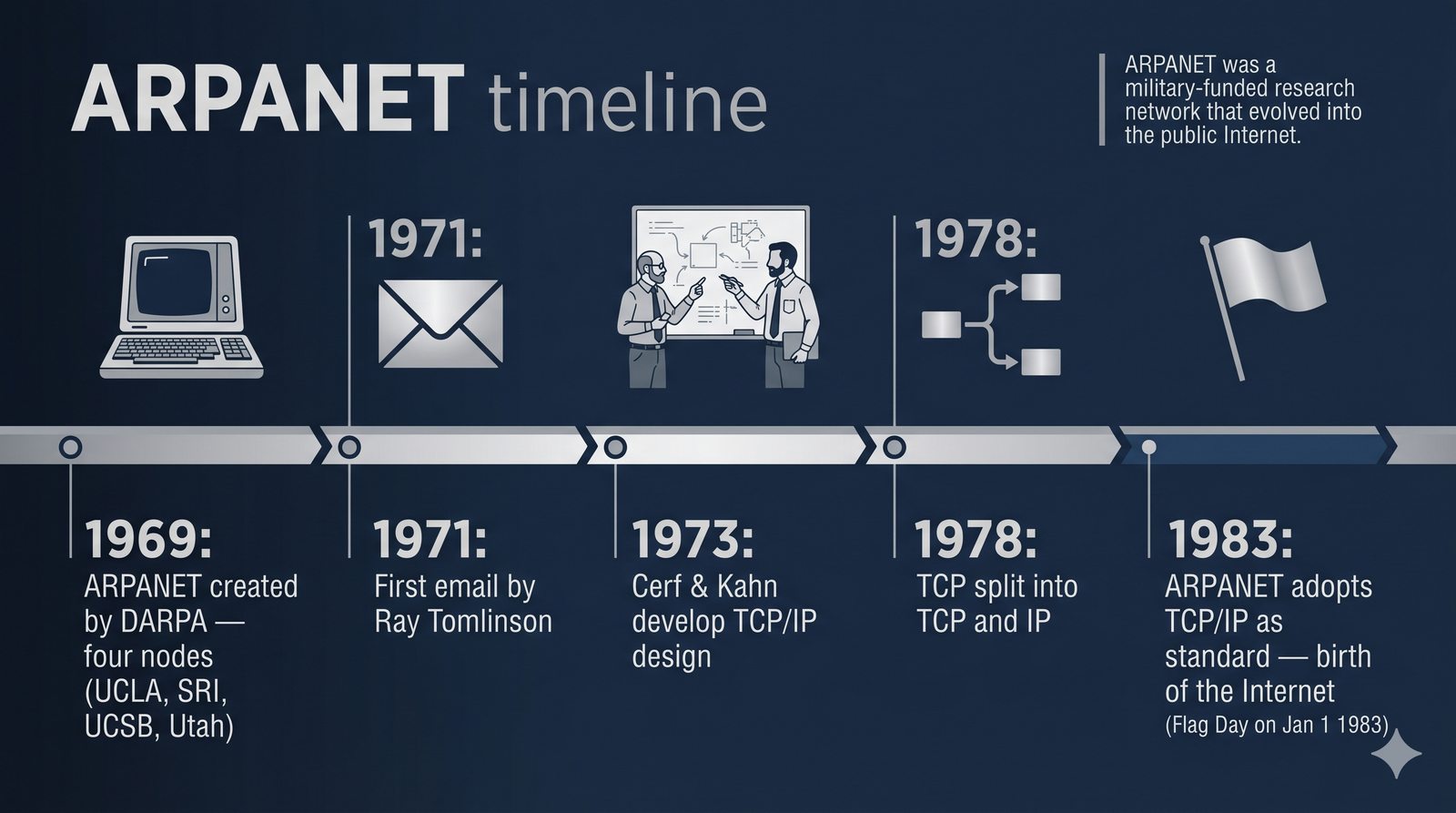
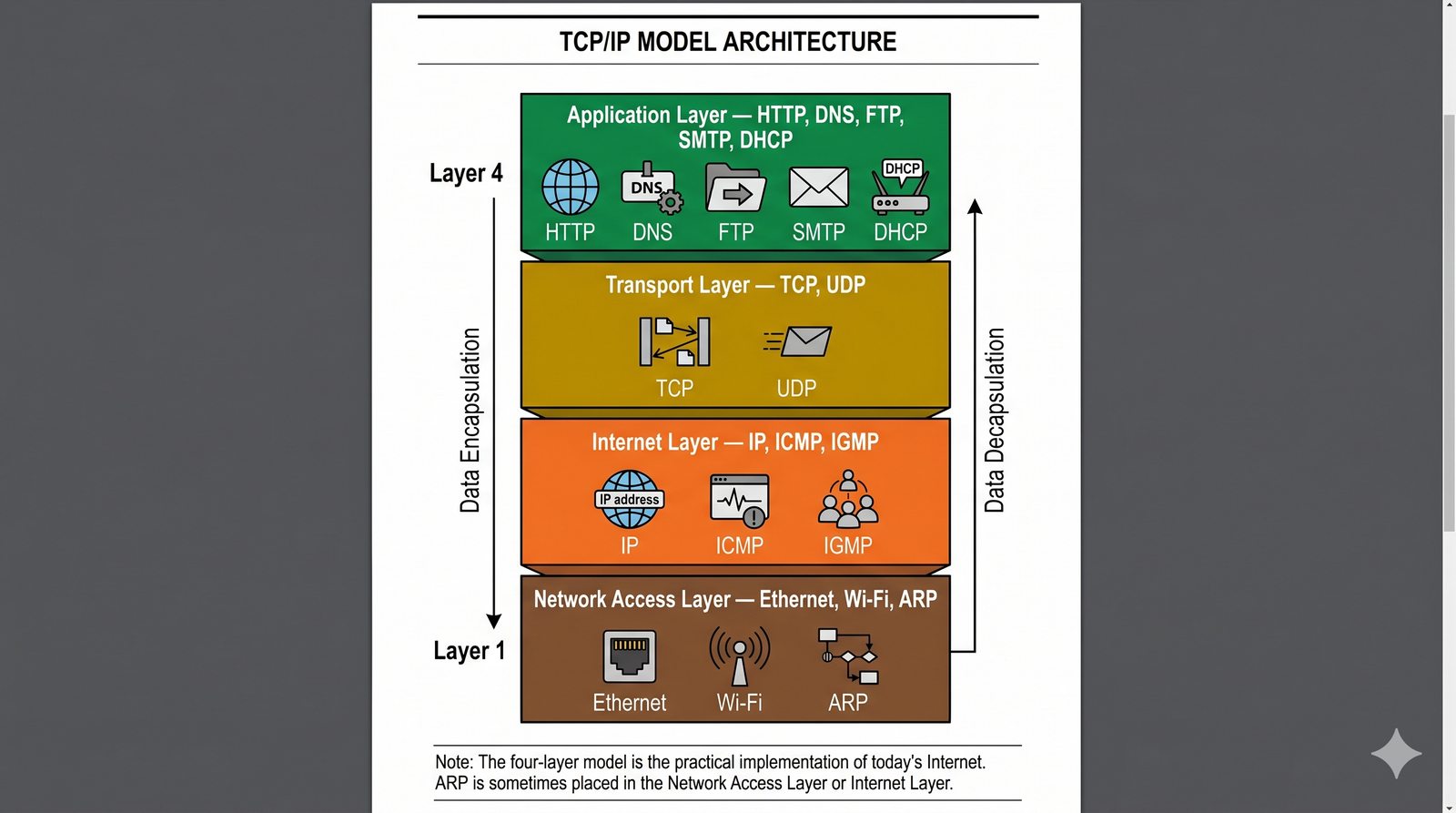
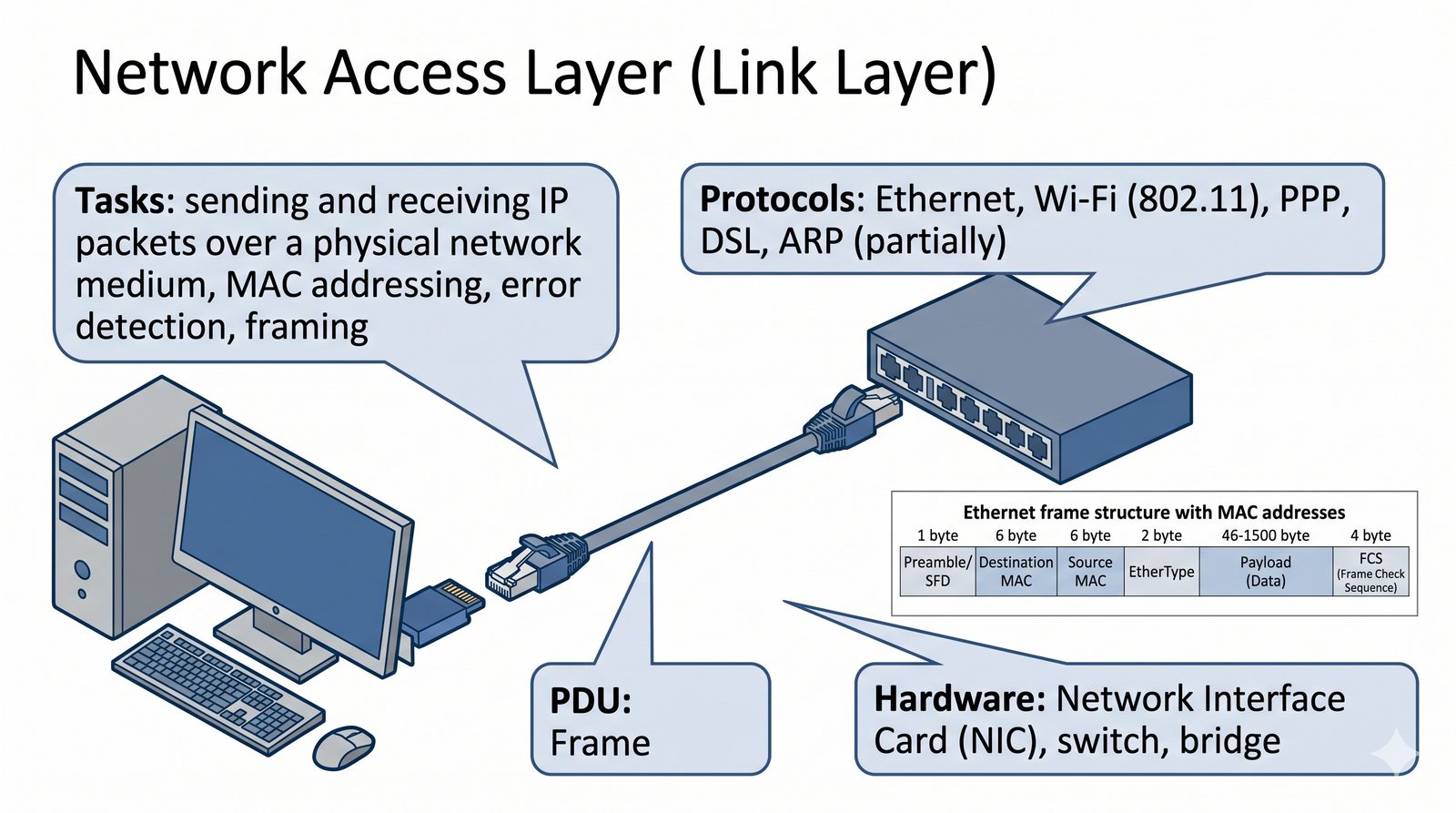
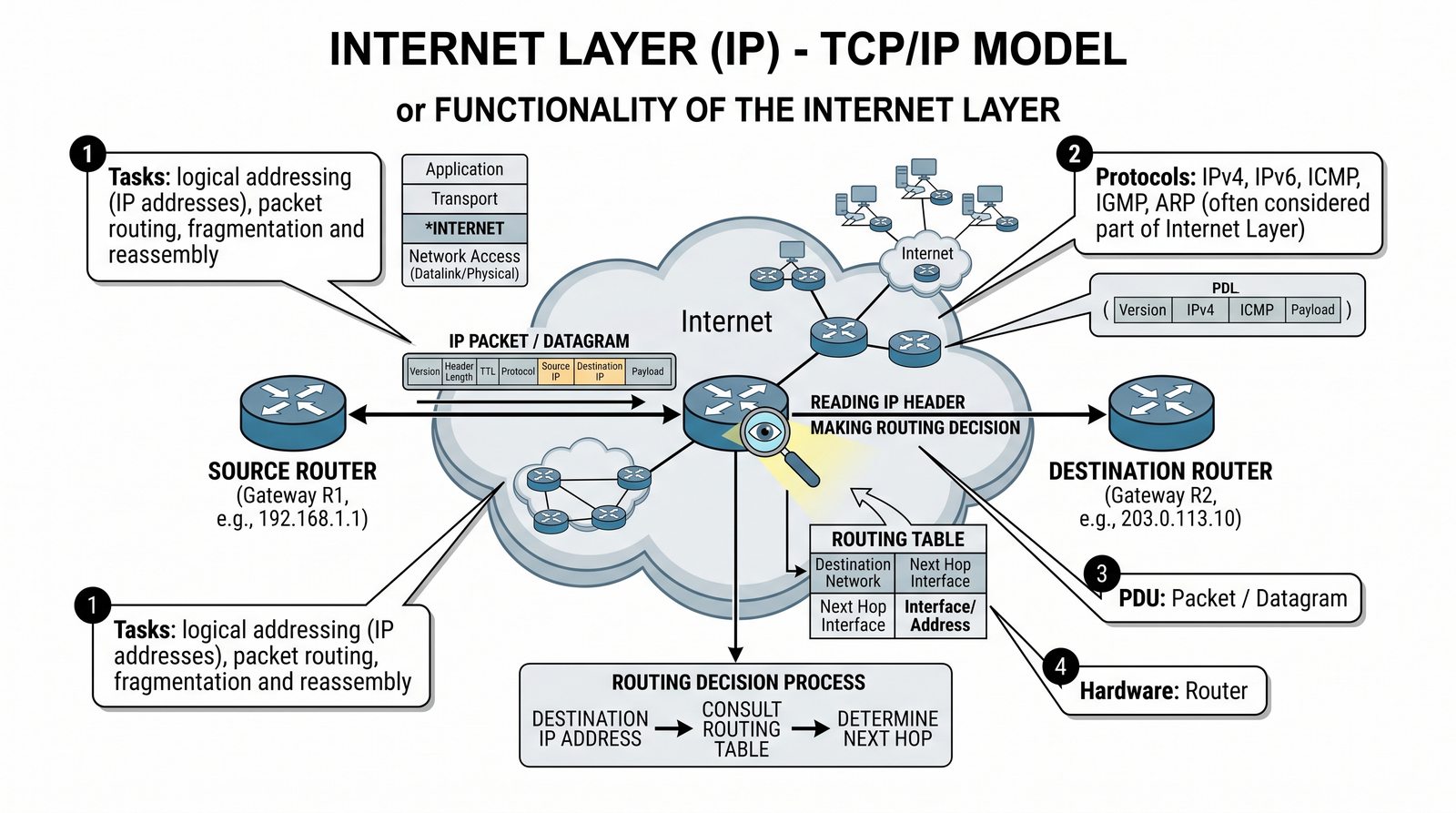
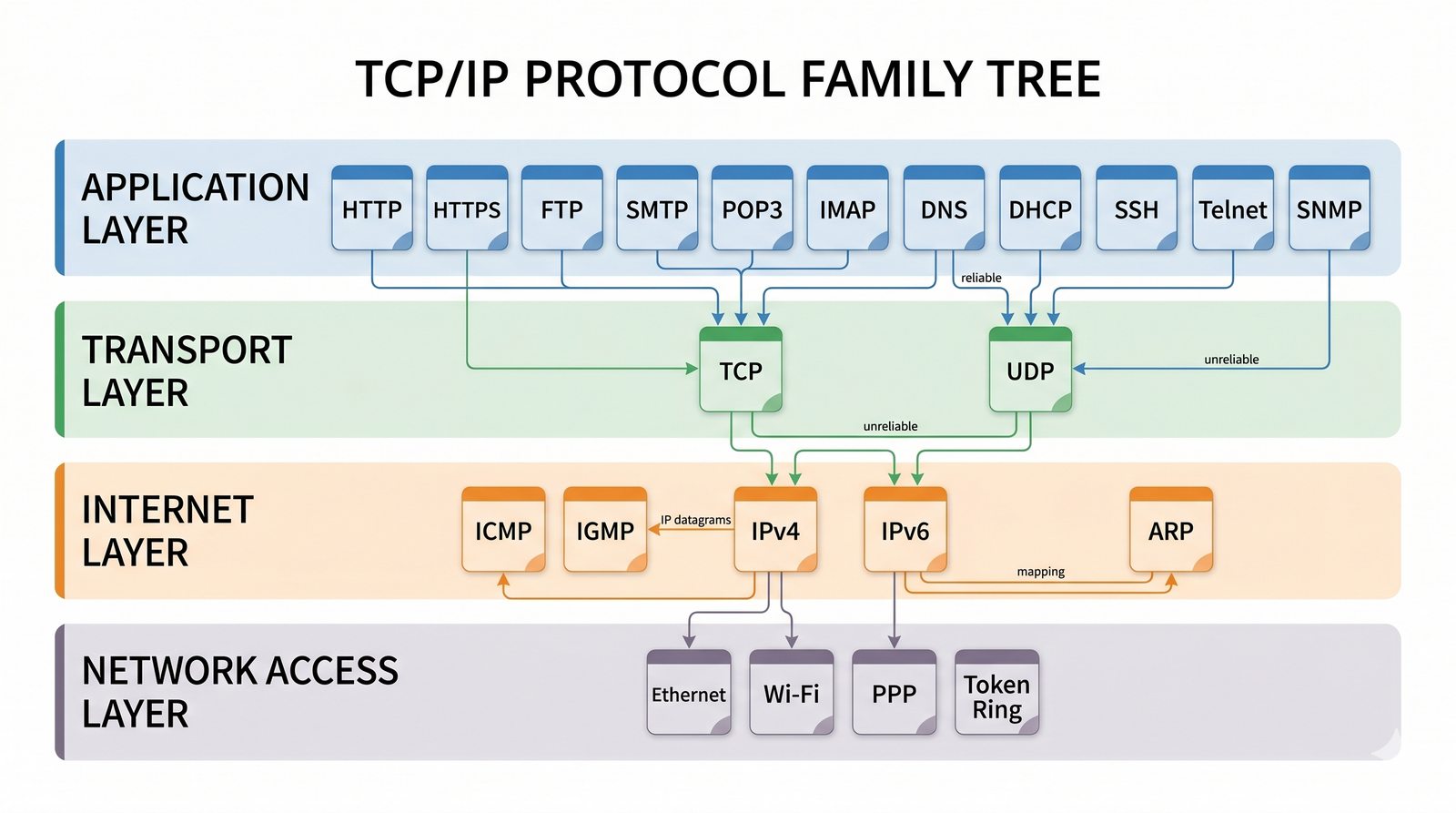
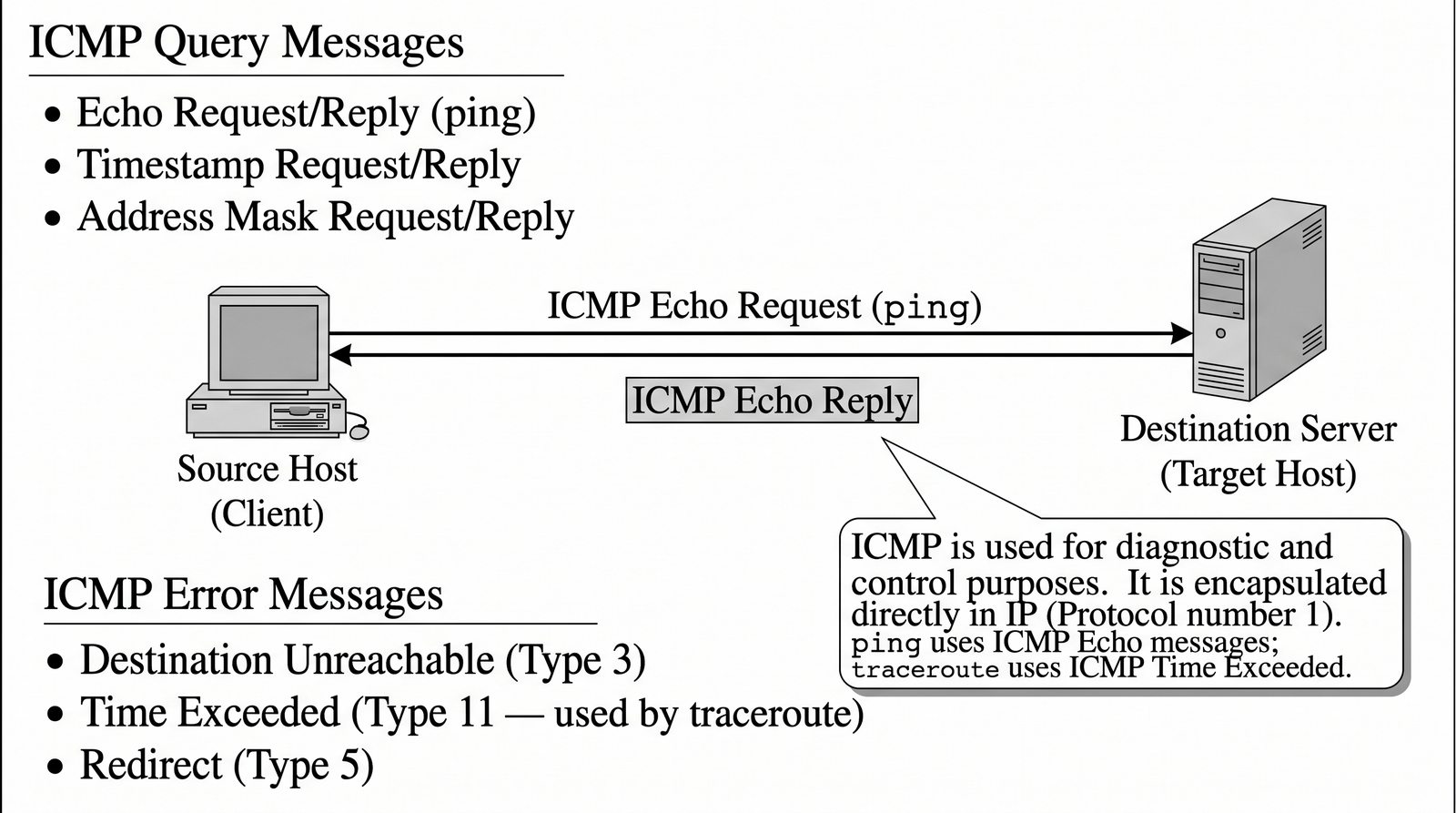
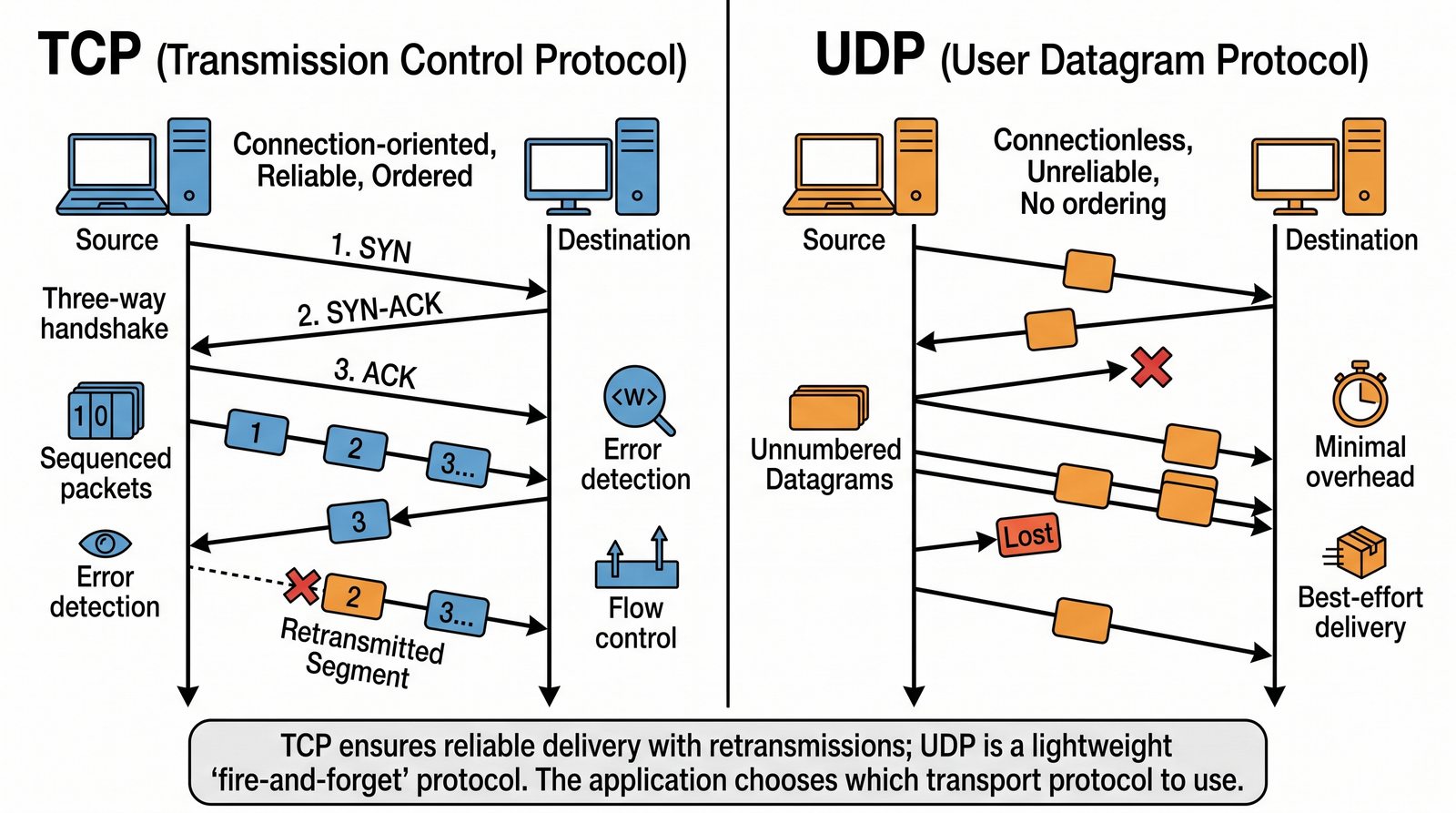
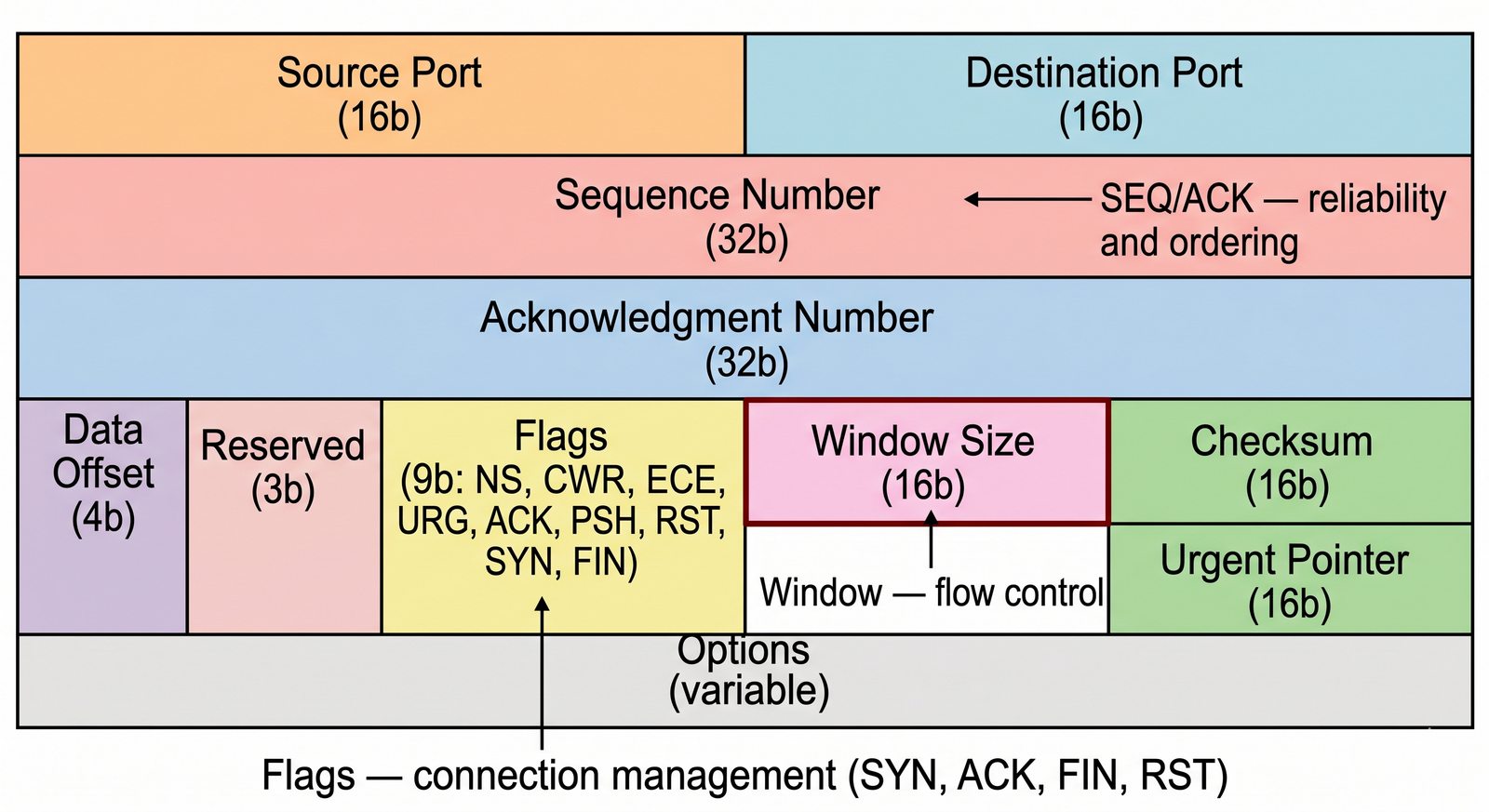
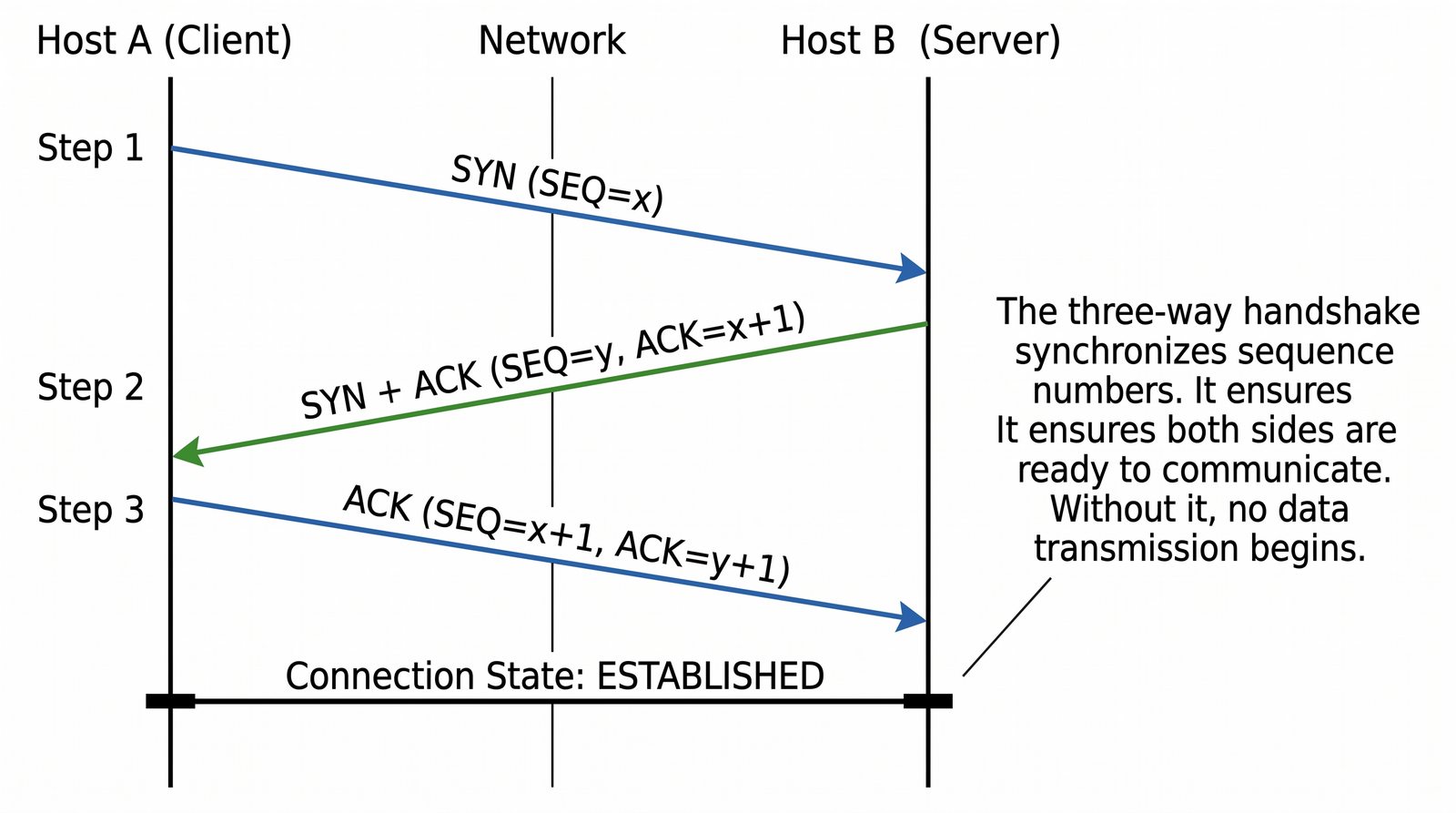
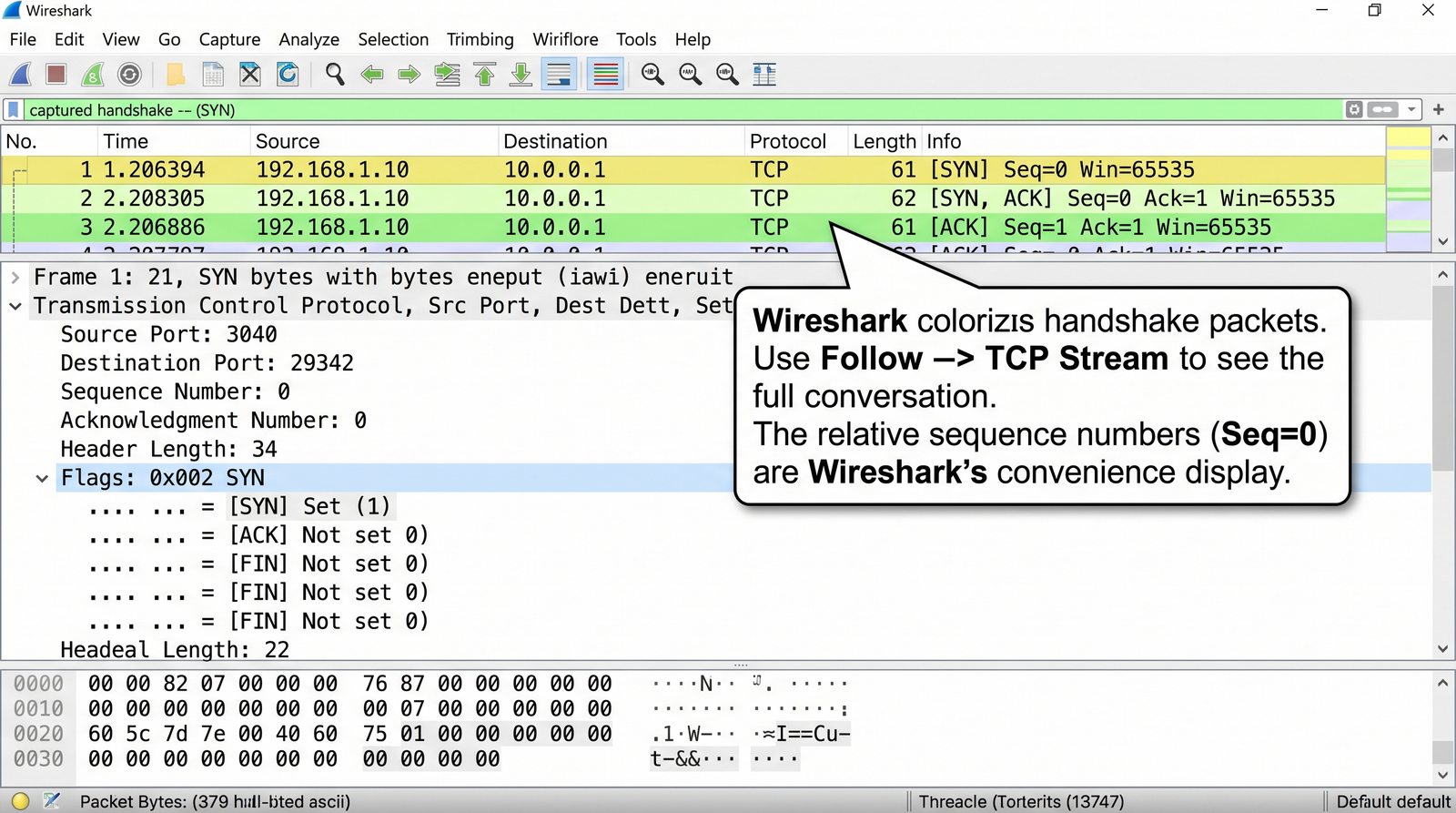
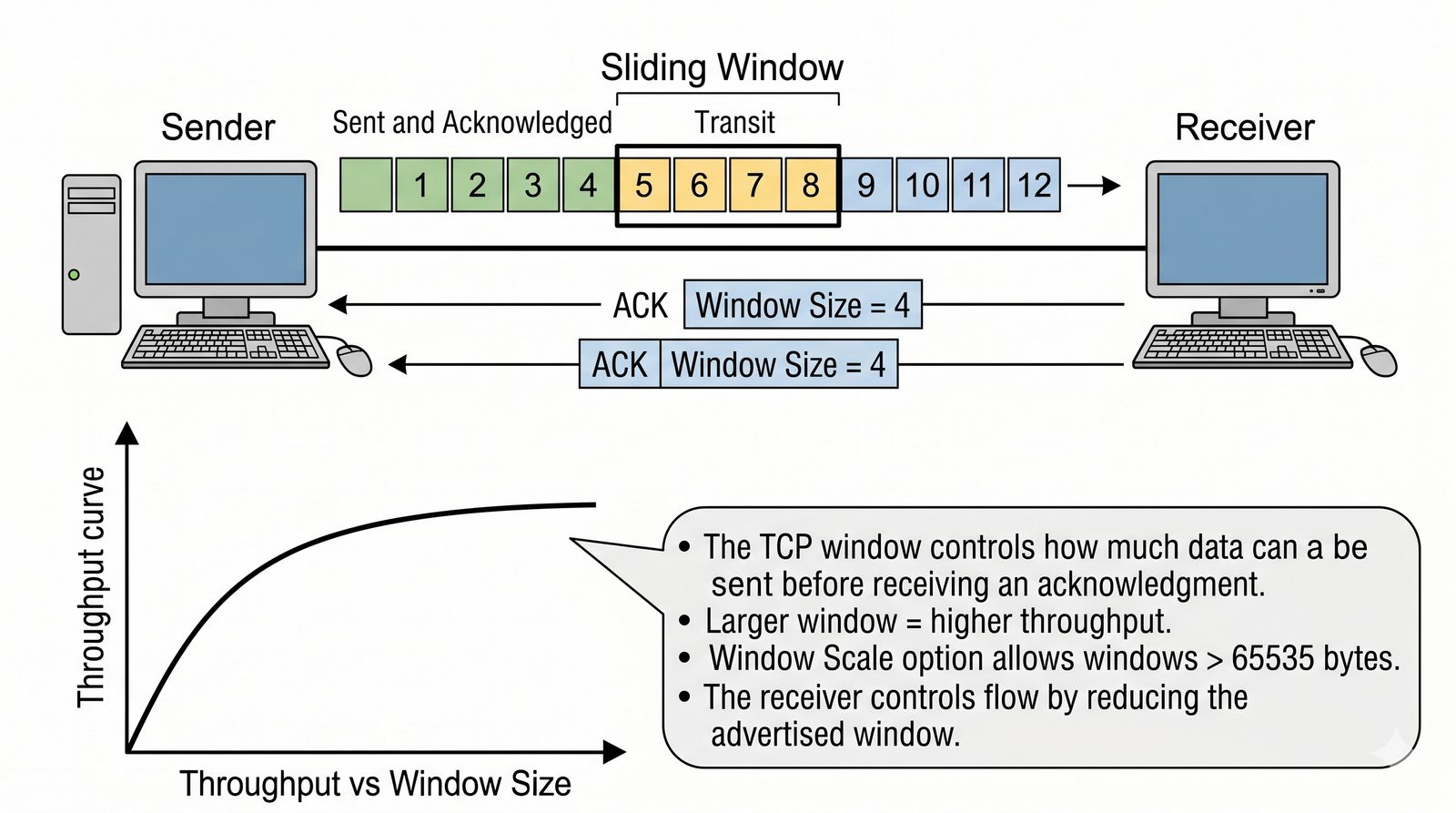
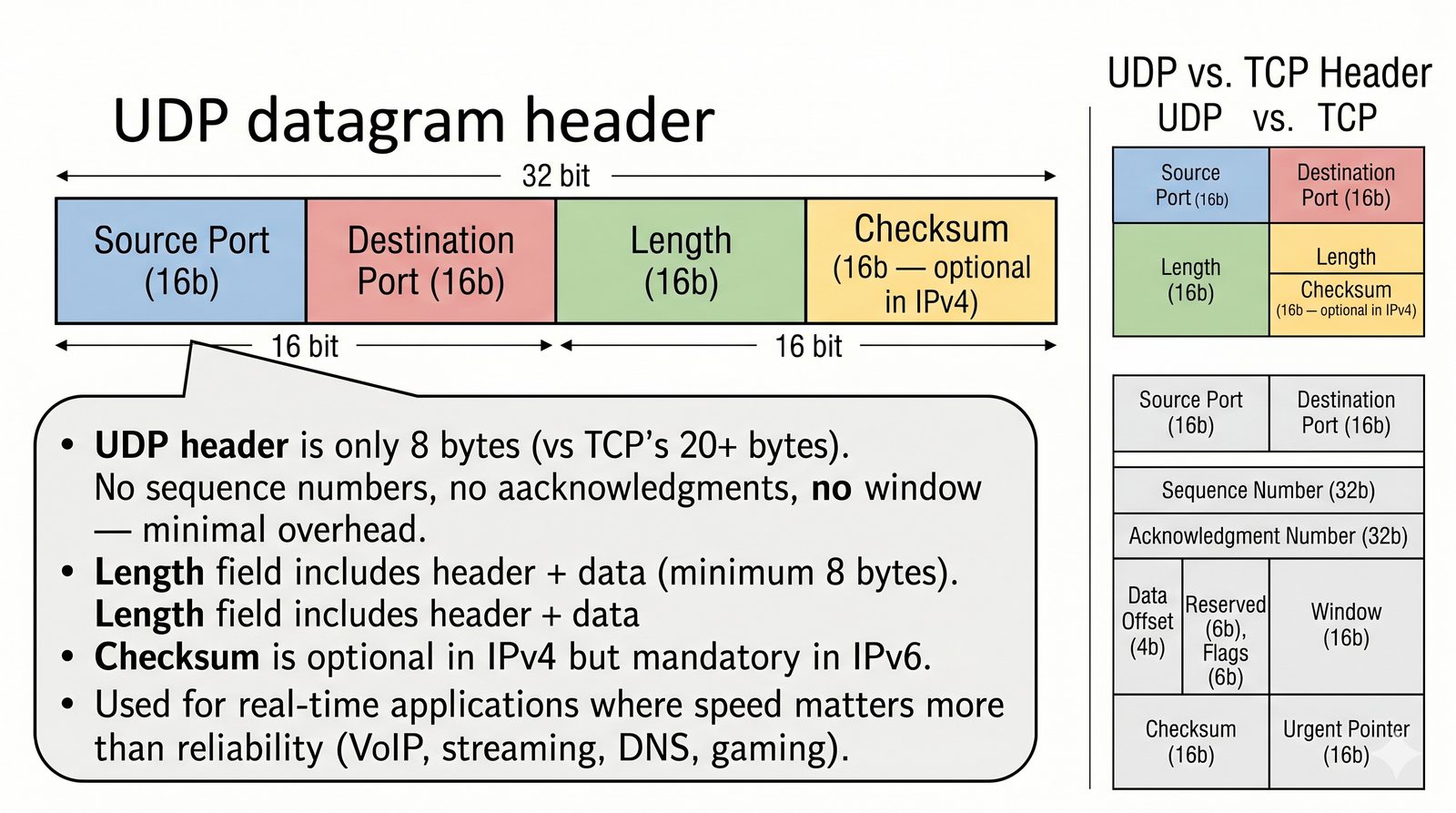
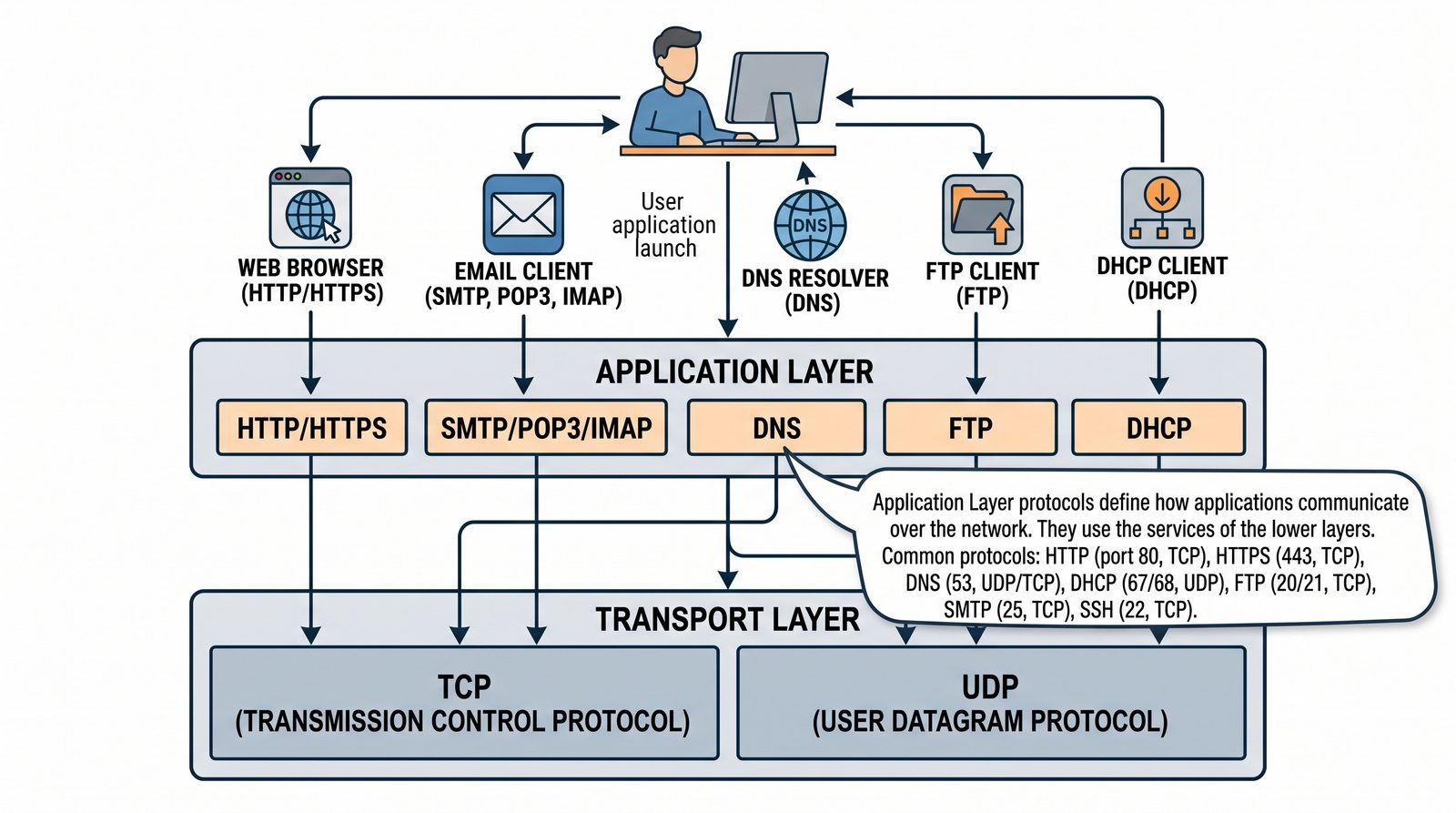
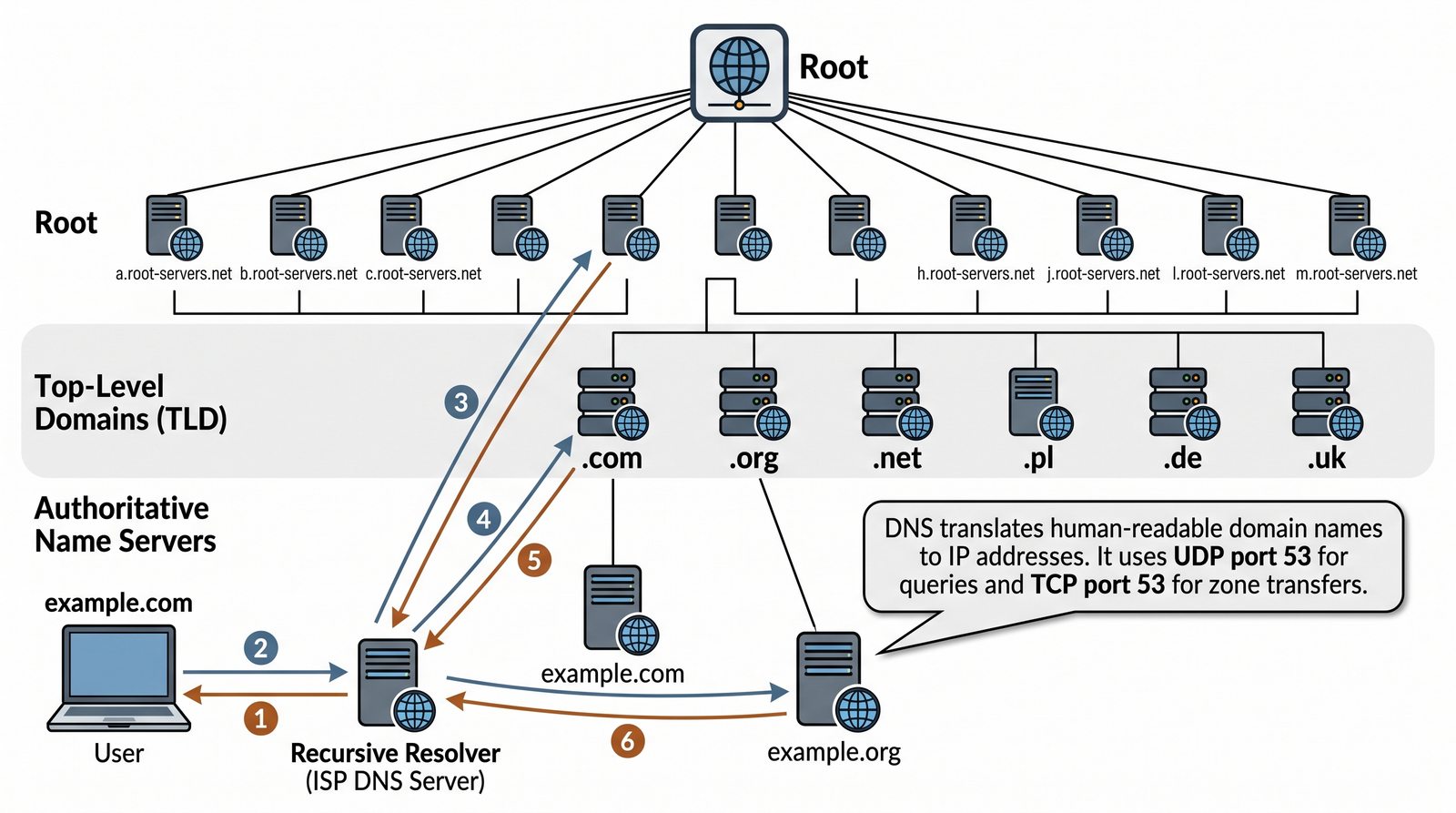
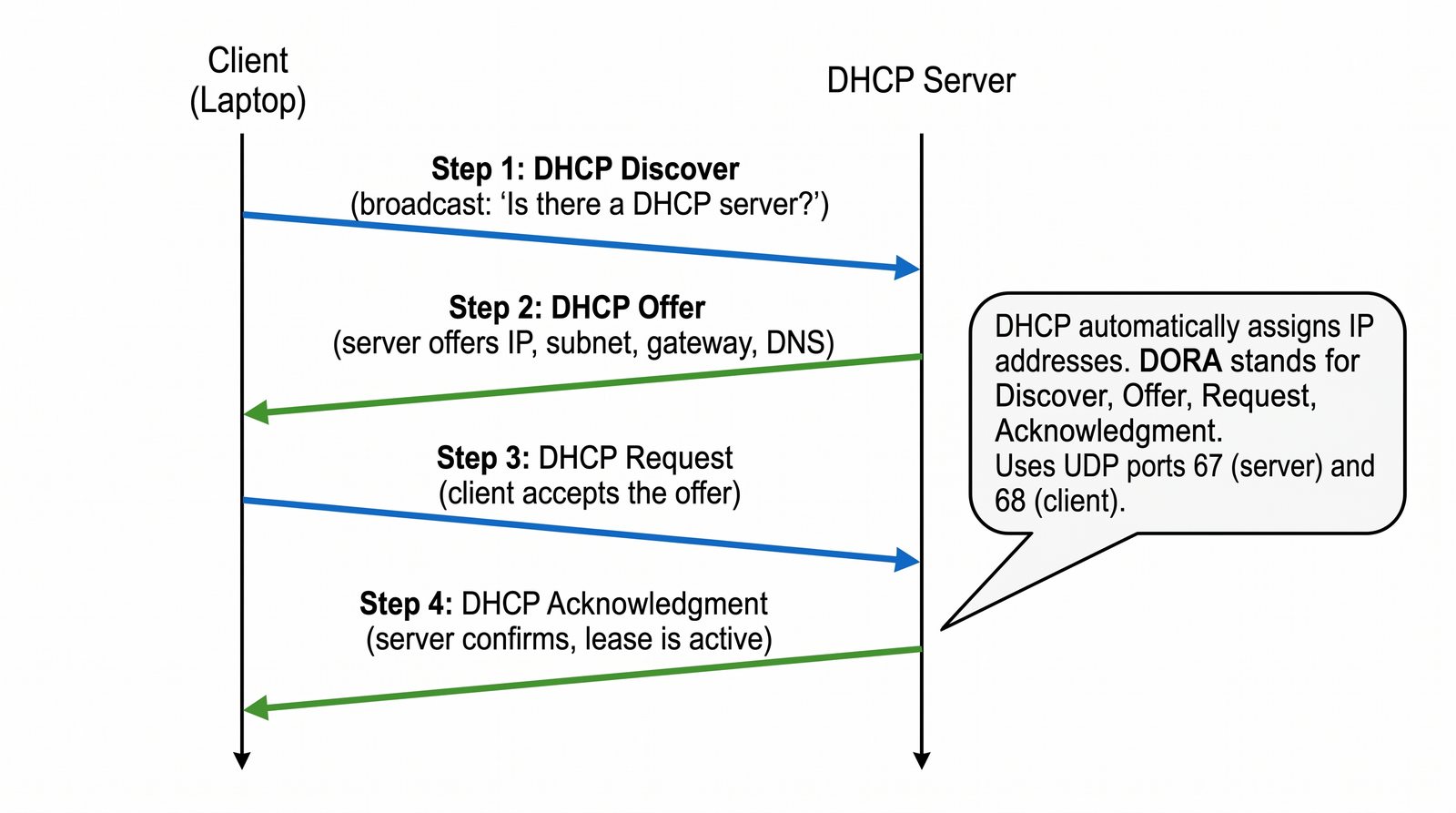
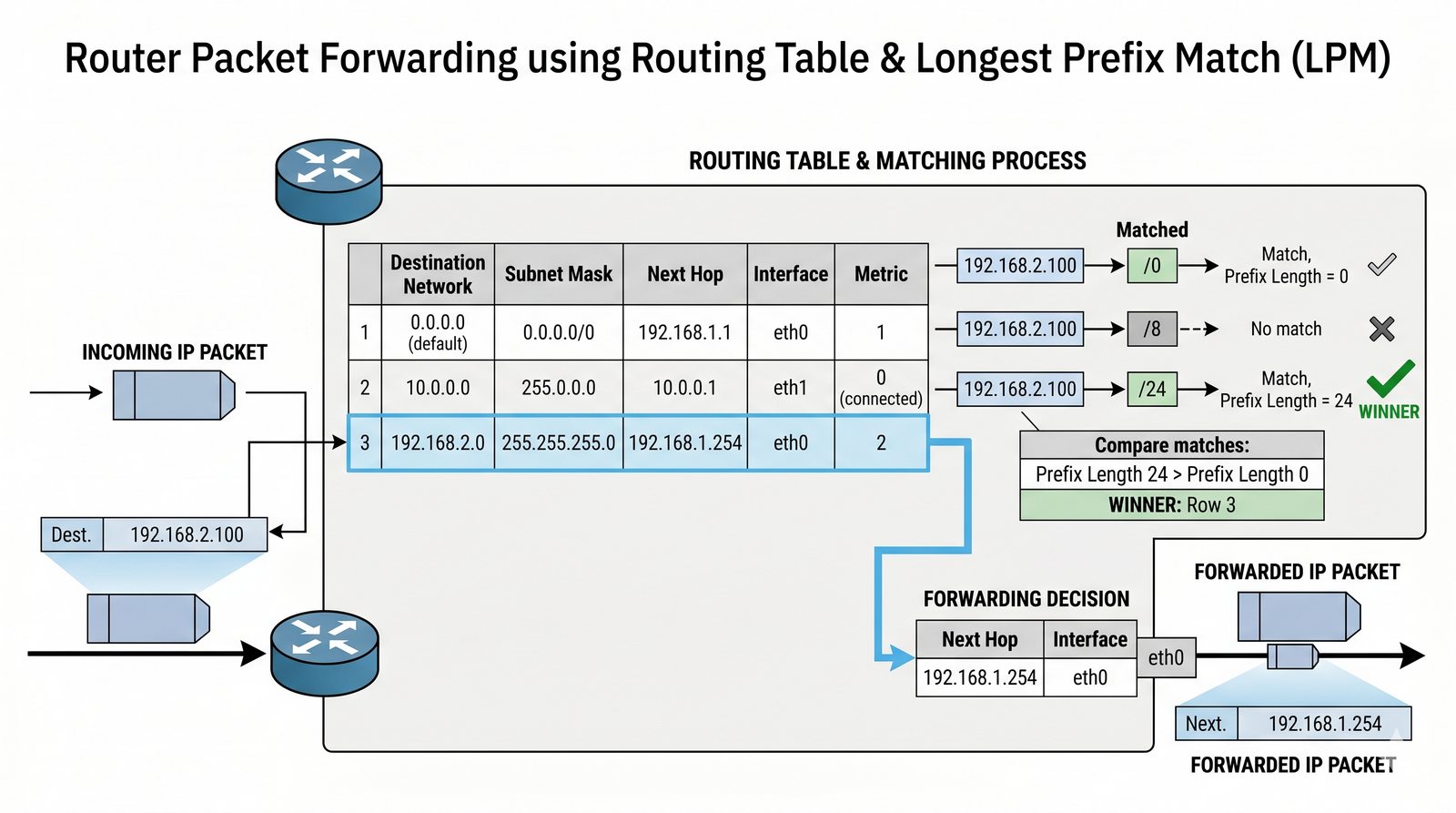
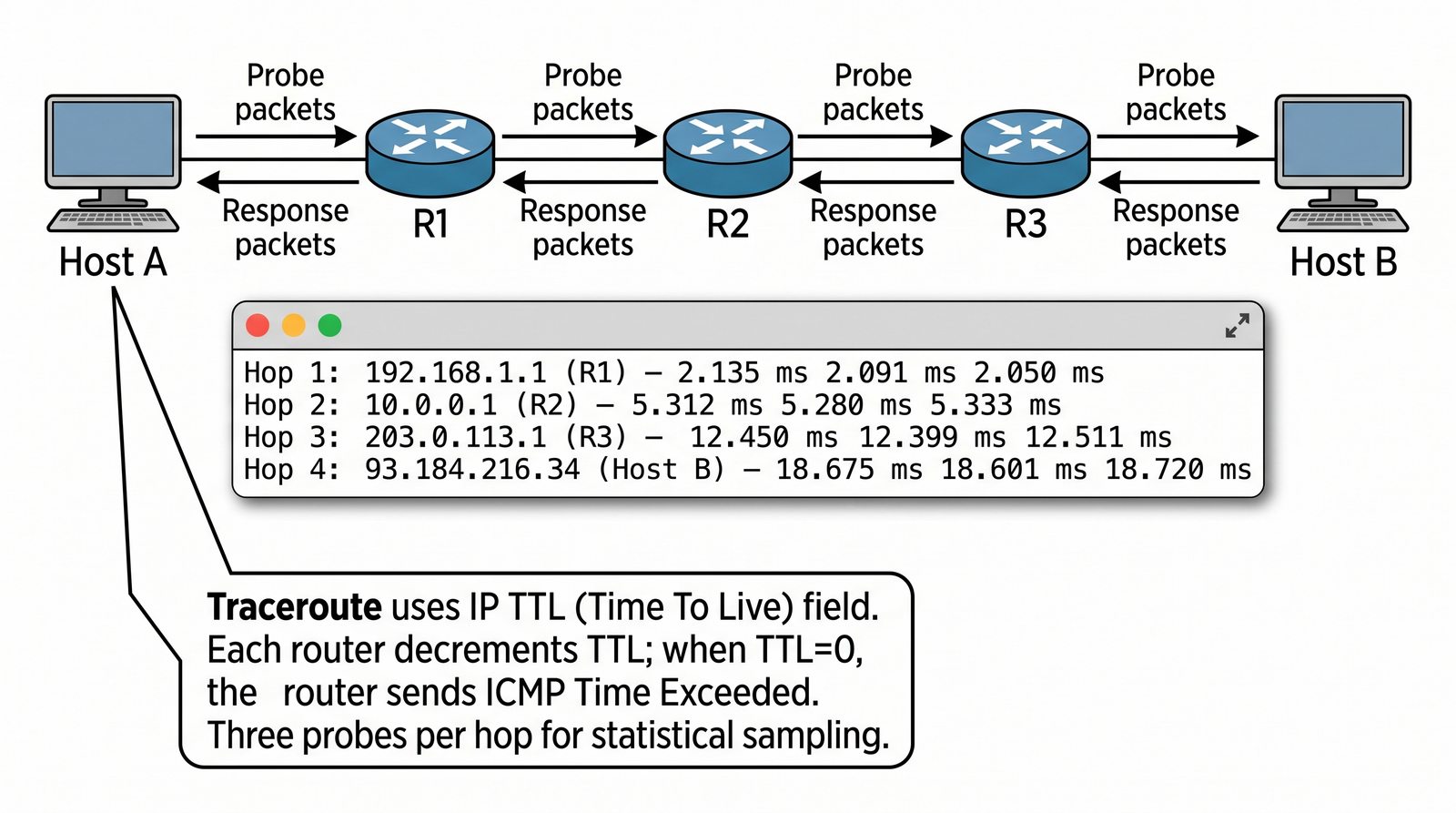
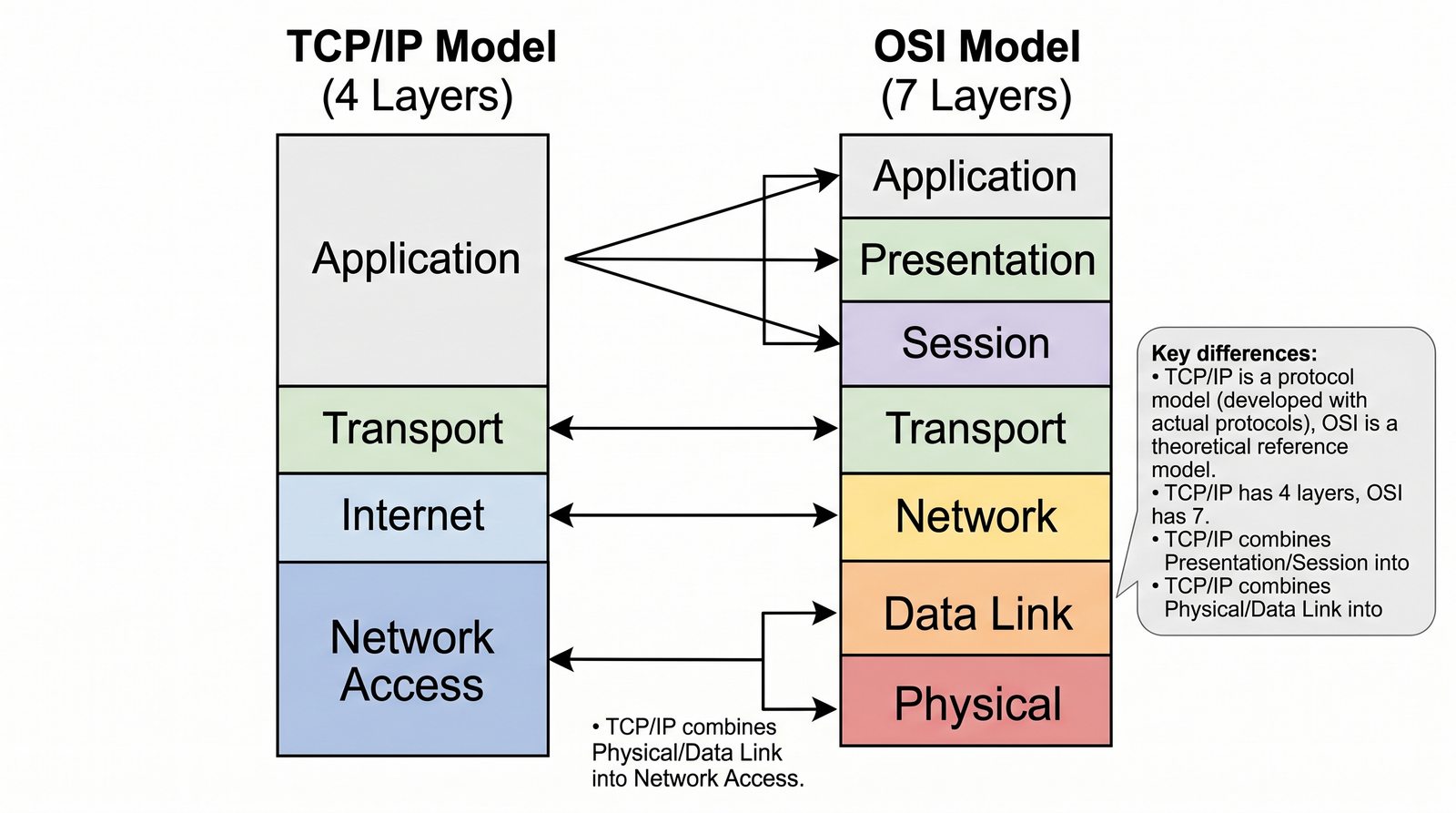
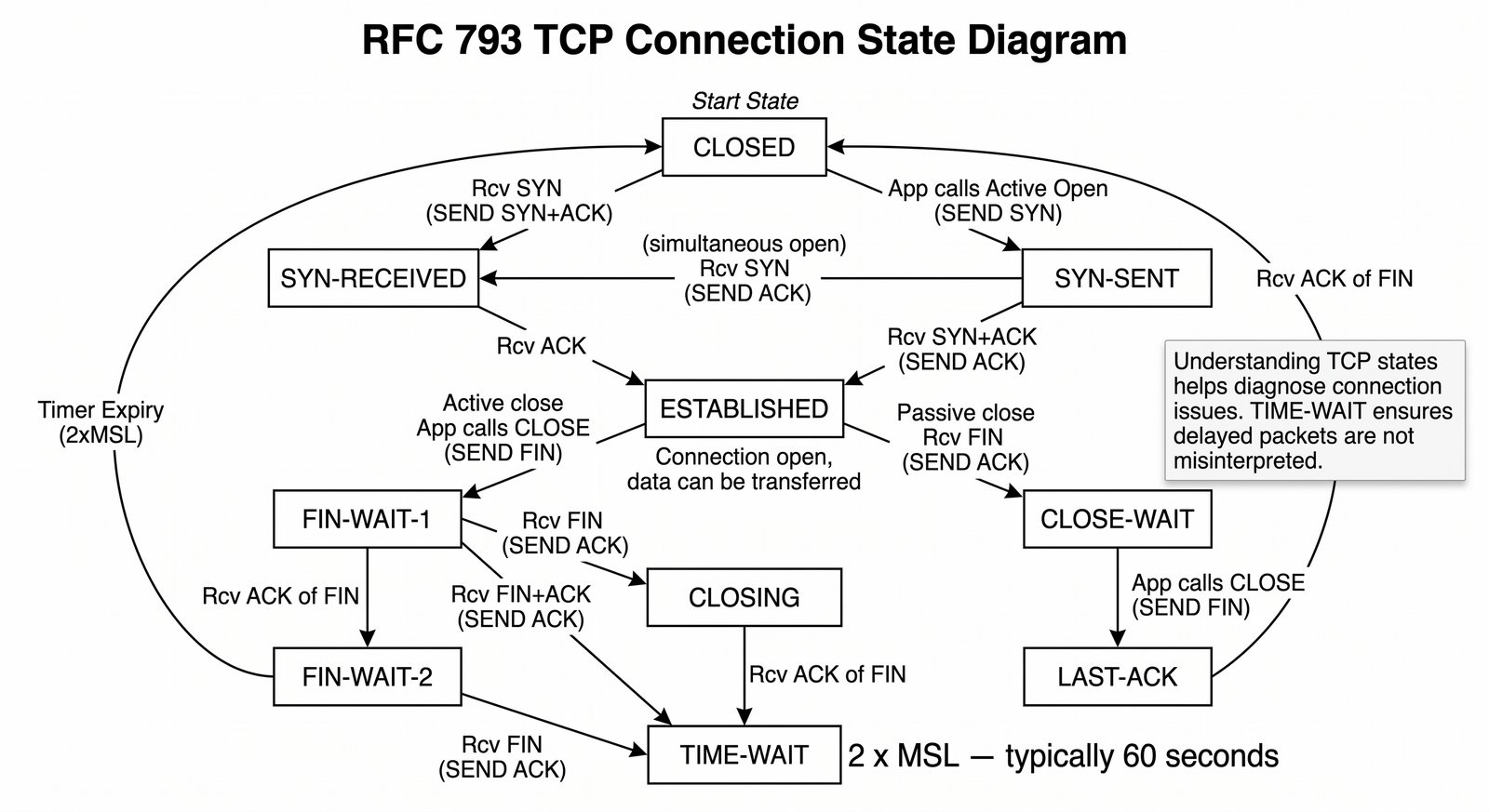
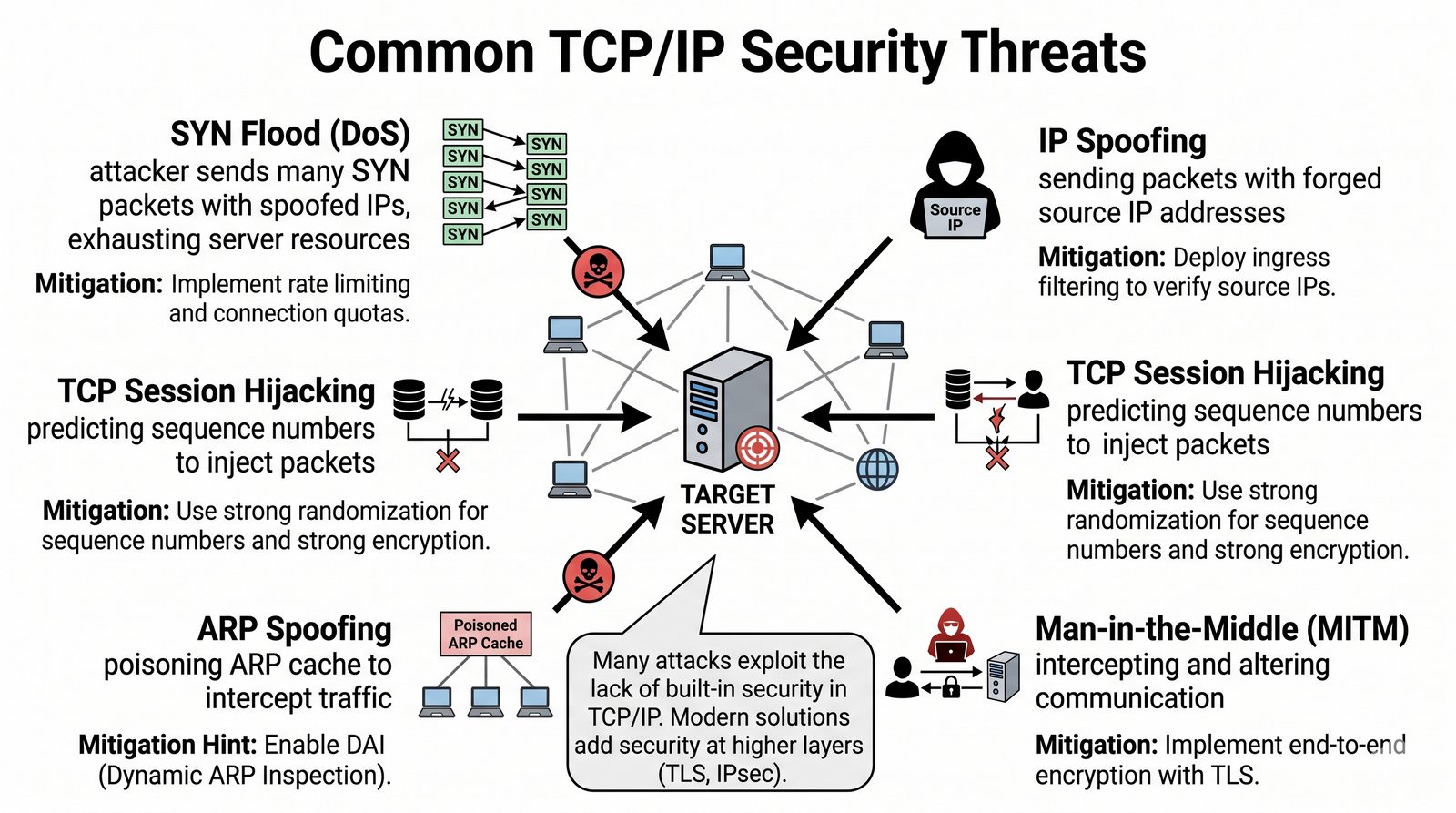
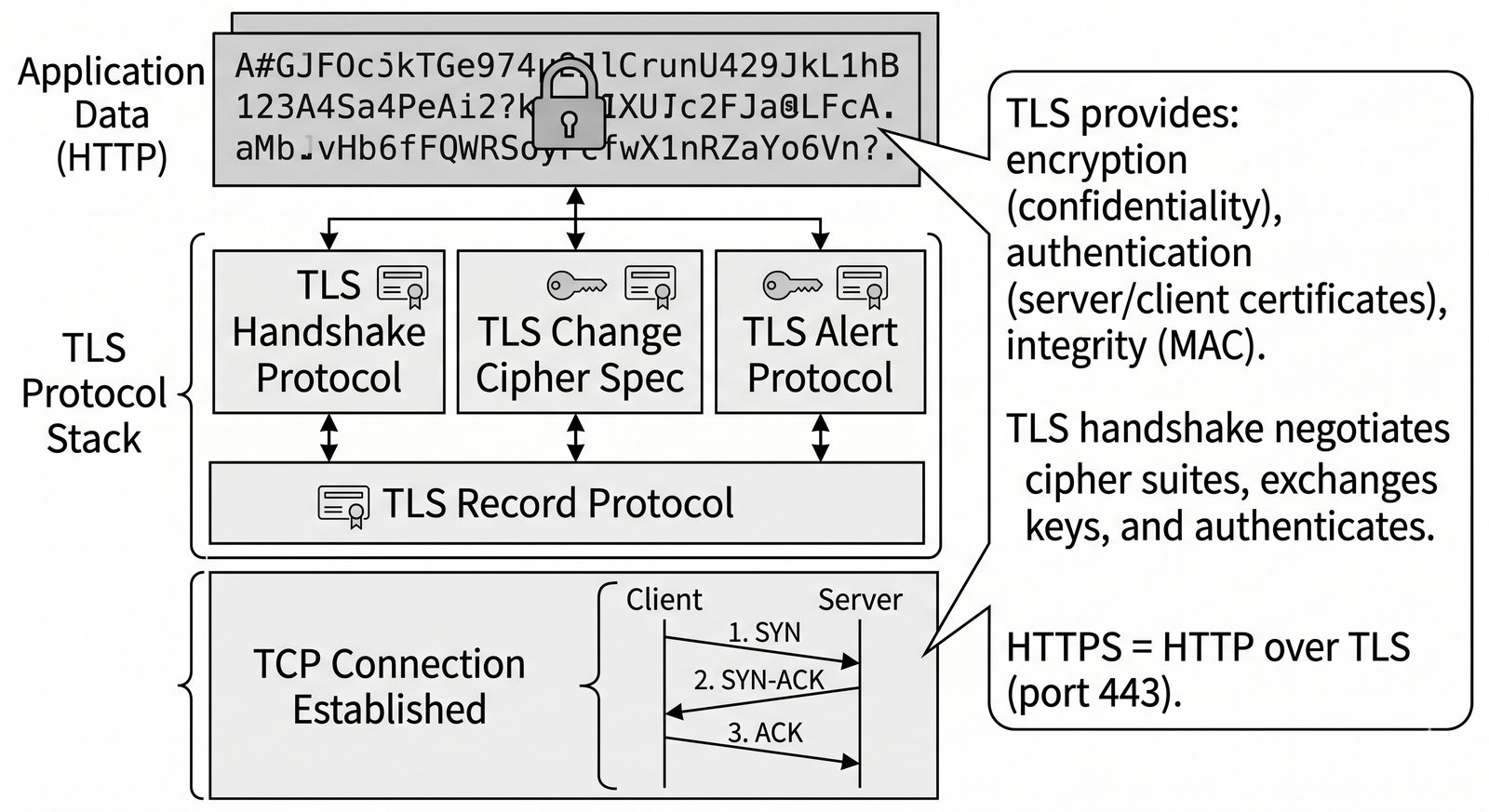
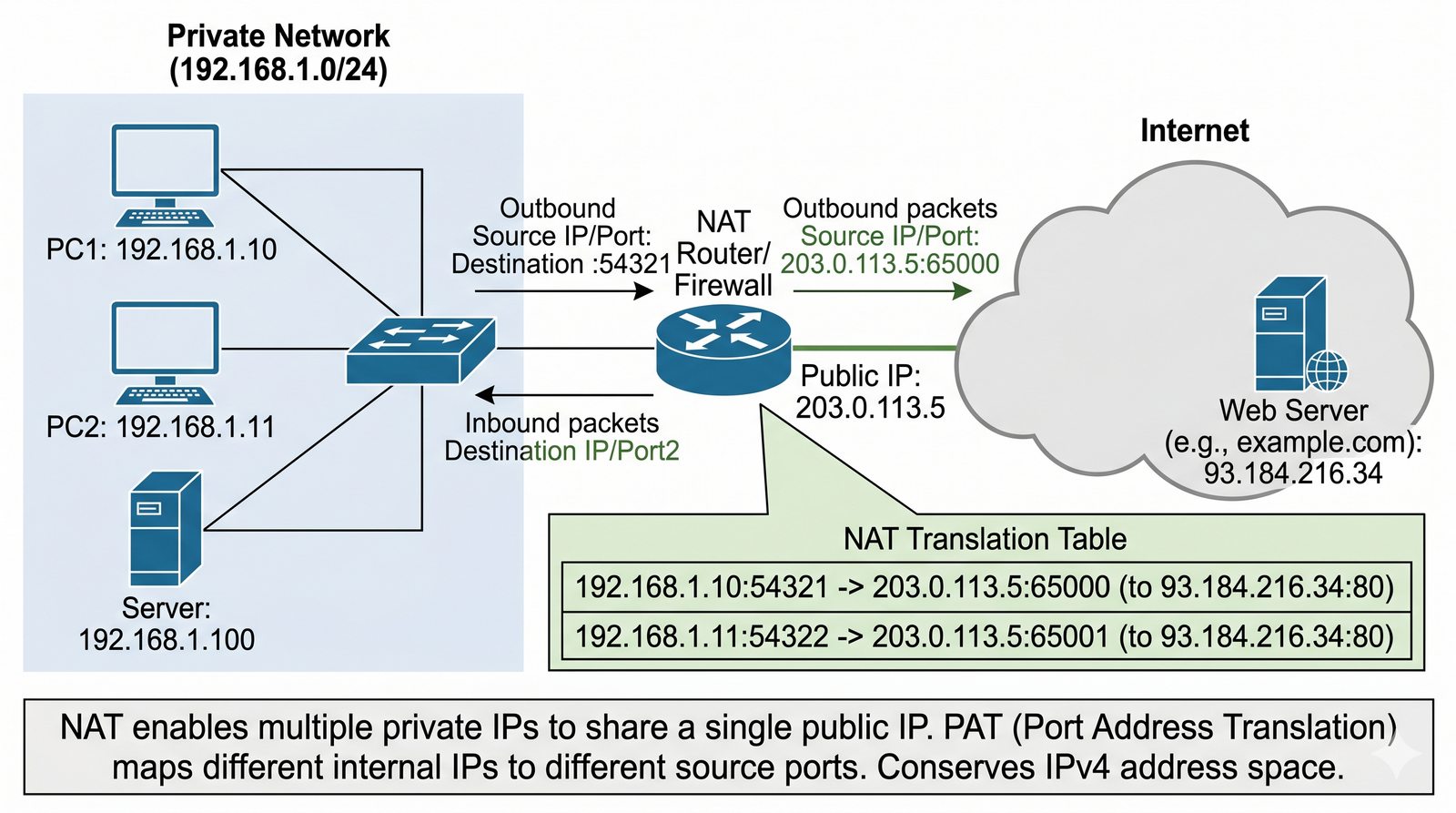
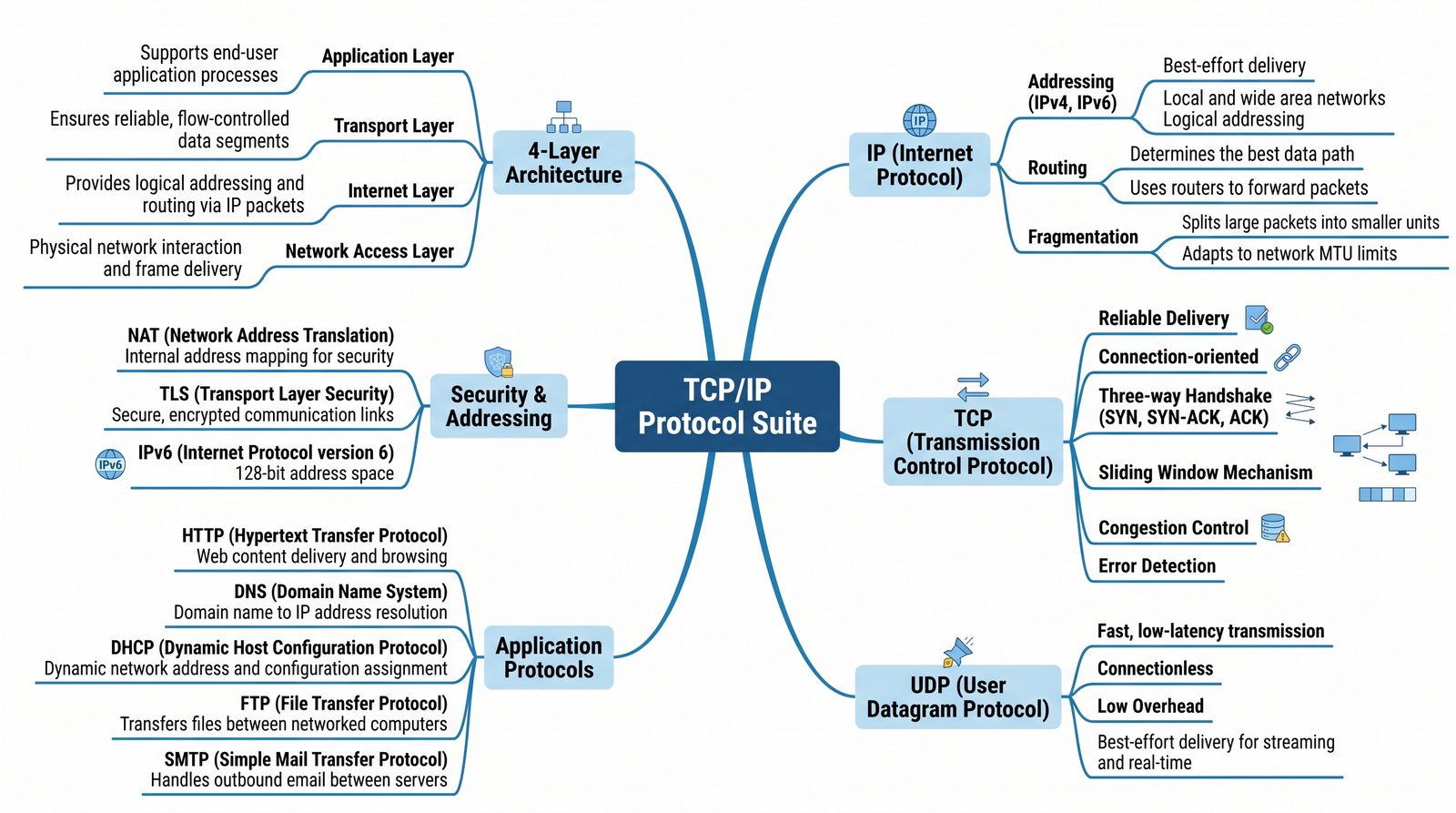
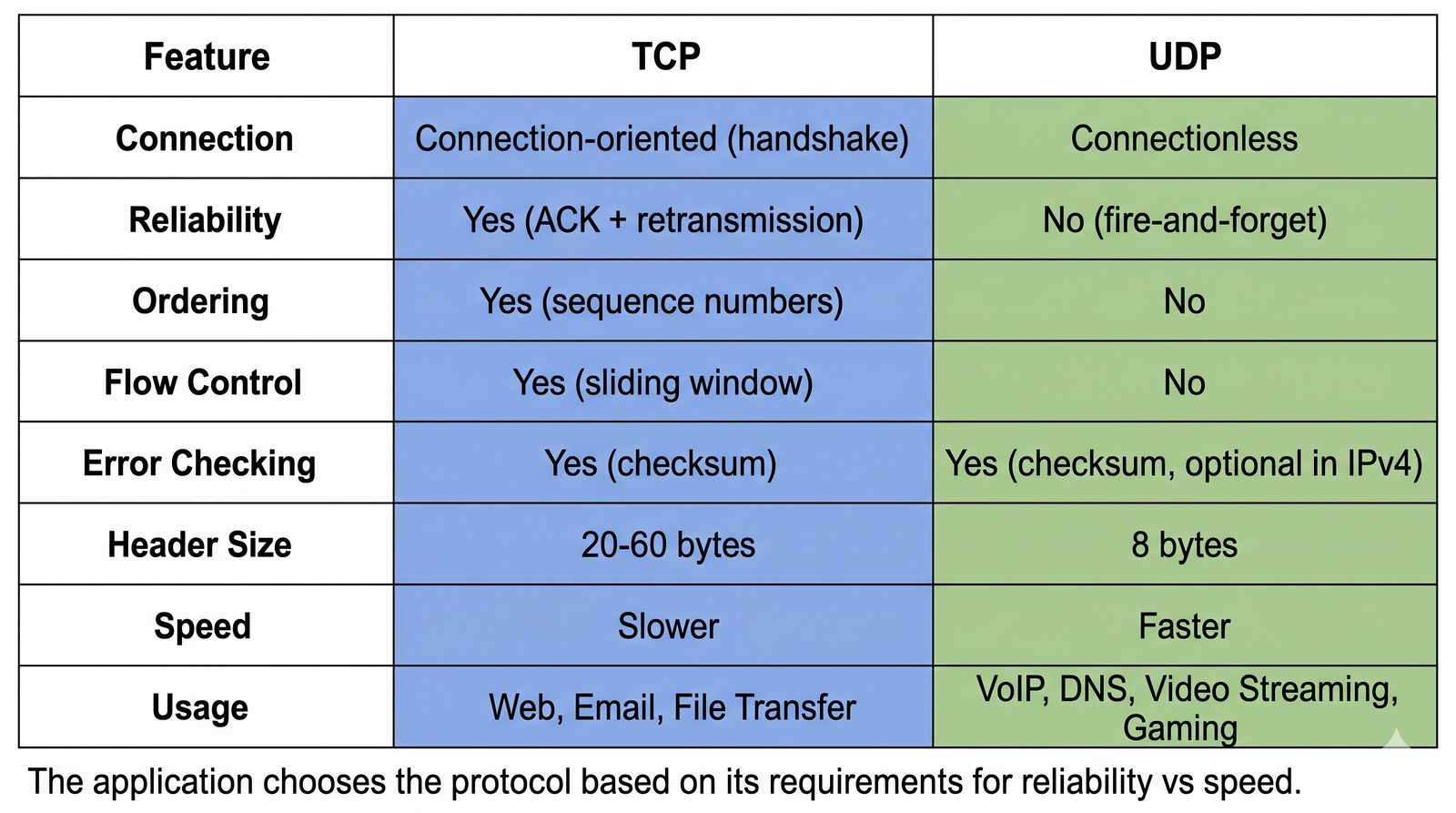
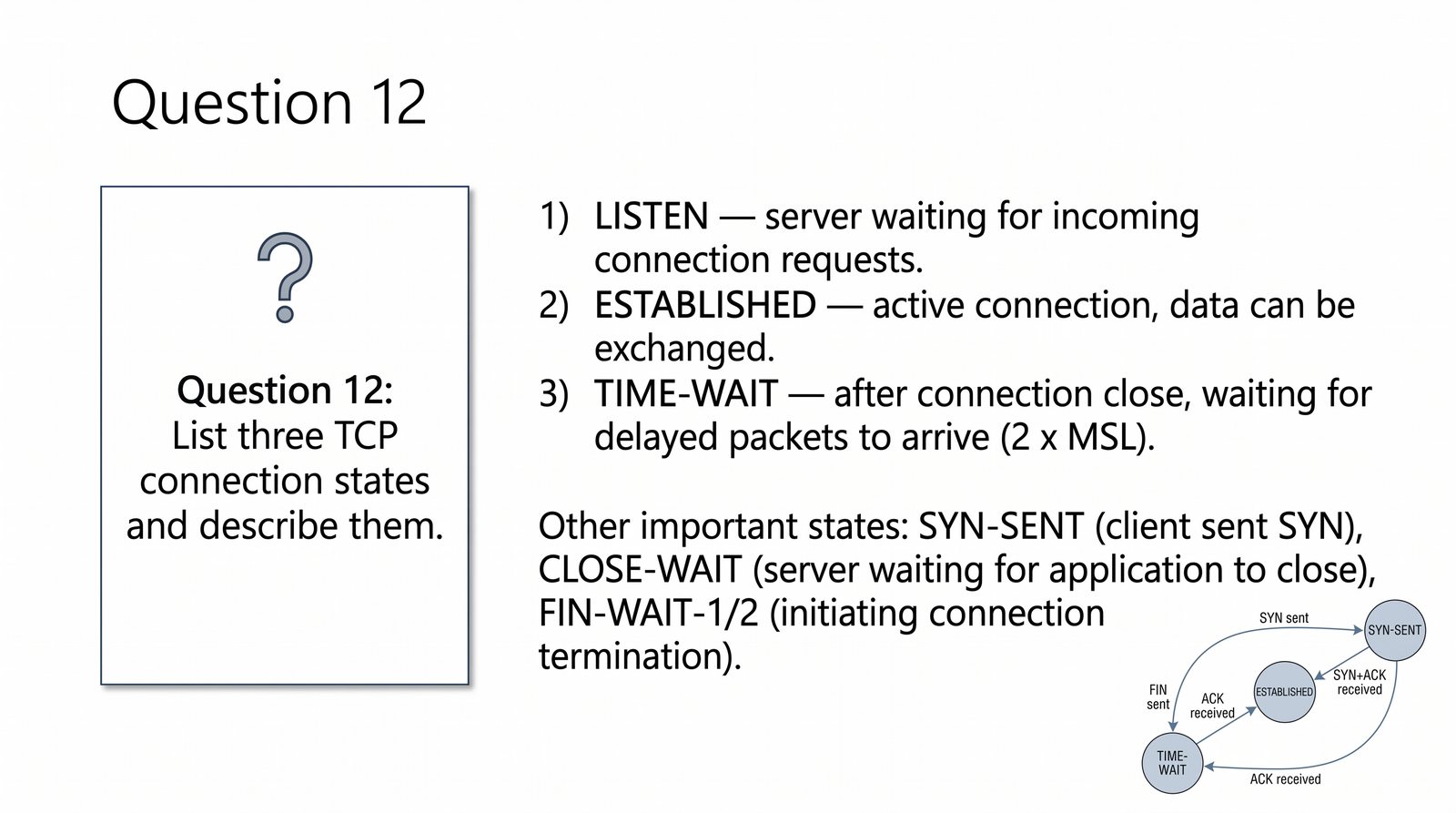
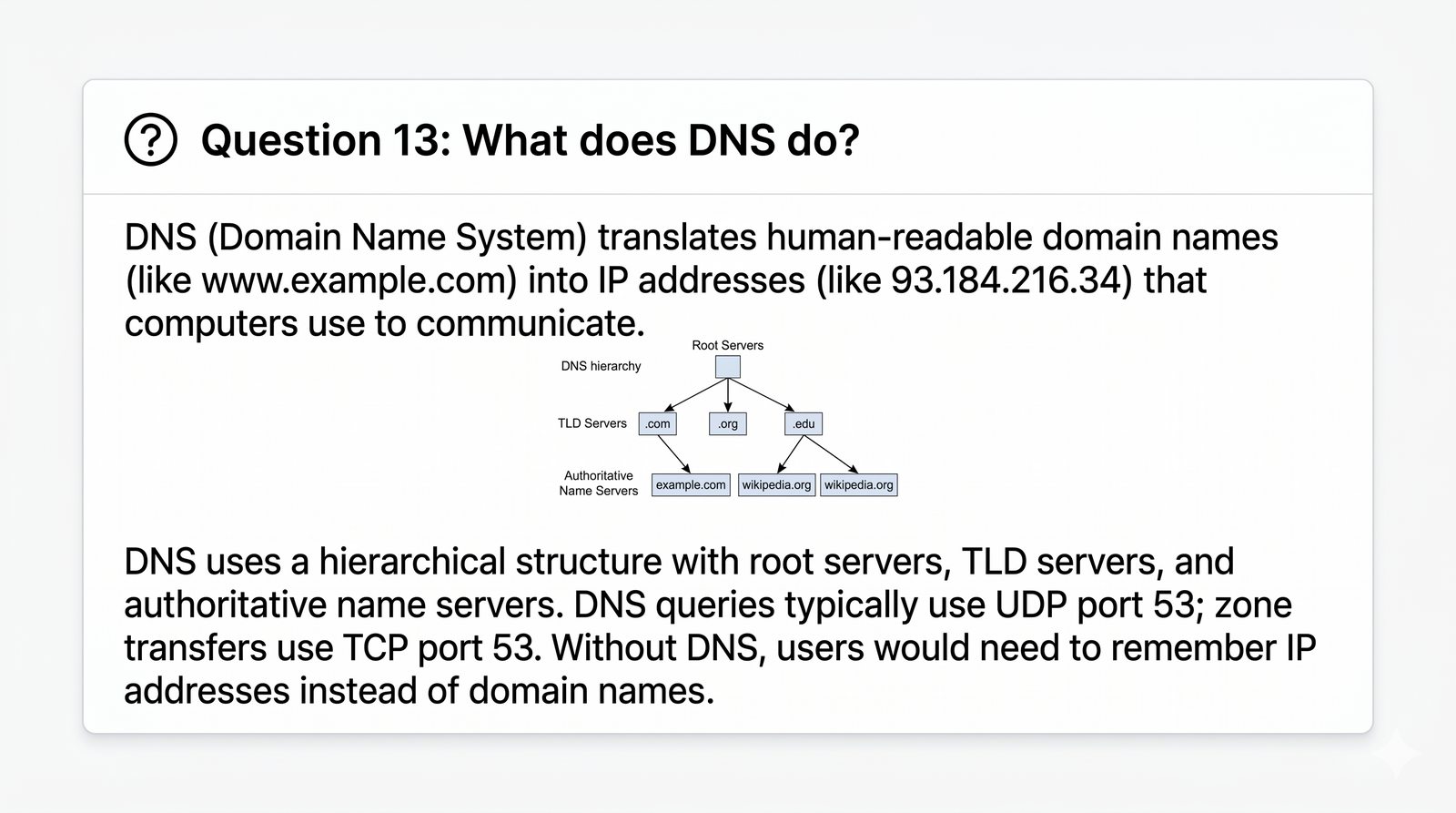
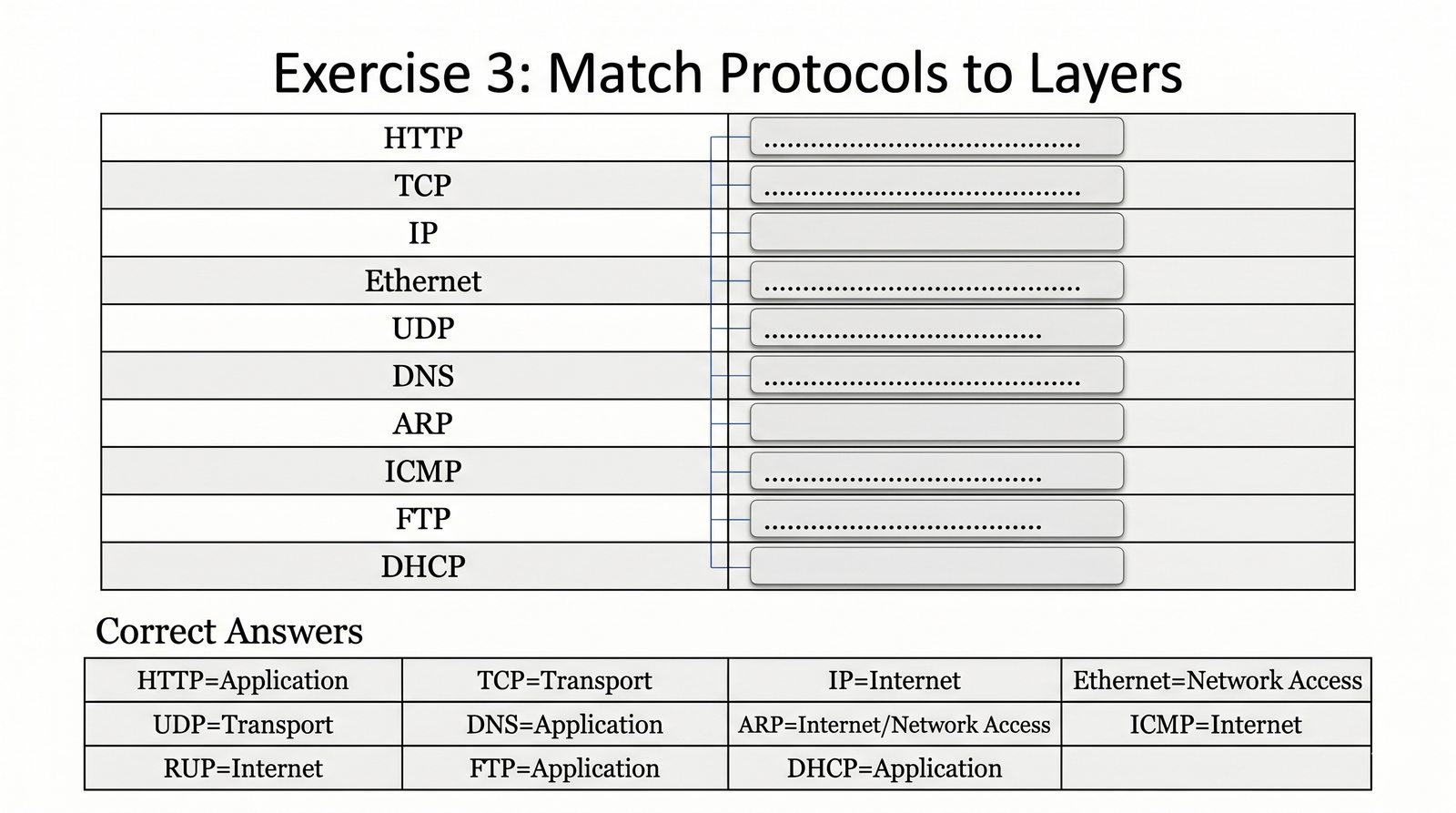
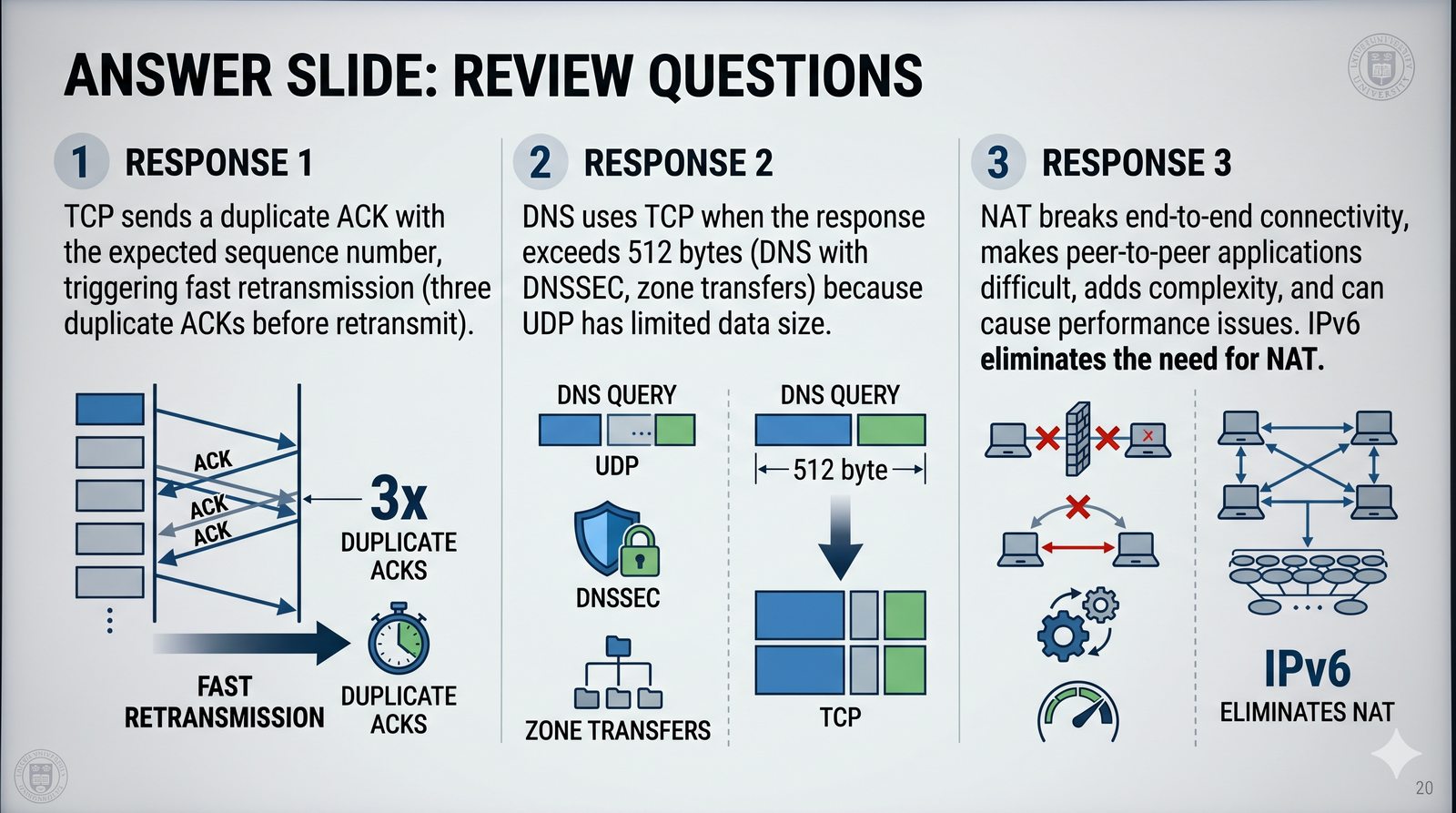
Prezentacja przedstawia model TCP/IP, będący praktycznym standardem komunikacji w dzisiejszym internecie, wywodzącym się z sieci ARPANET. Omówiono cztery warstwy modelu: dostępu do sieci, internetową, transportową i aplikacji, wraz z porównaniem do modelu ISO/OSI. Przedstawiono najważniejsze protokoły, adresację, routing, zarządzanie połączeniami oraz zagadnienia bezpieczeństwa i przyszłości TCP/IP.