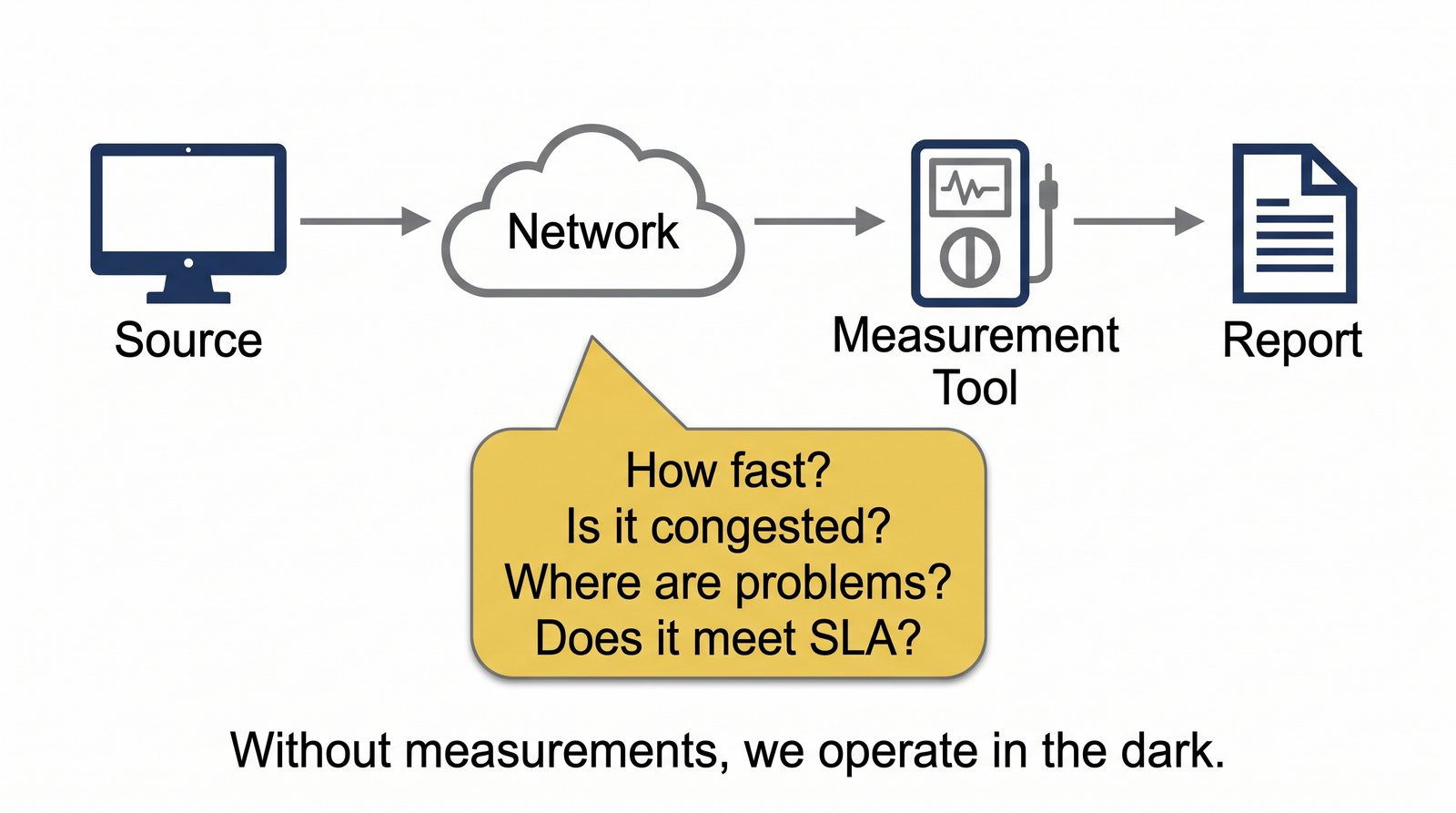
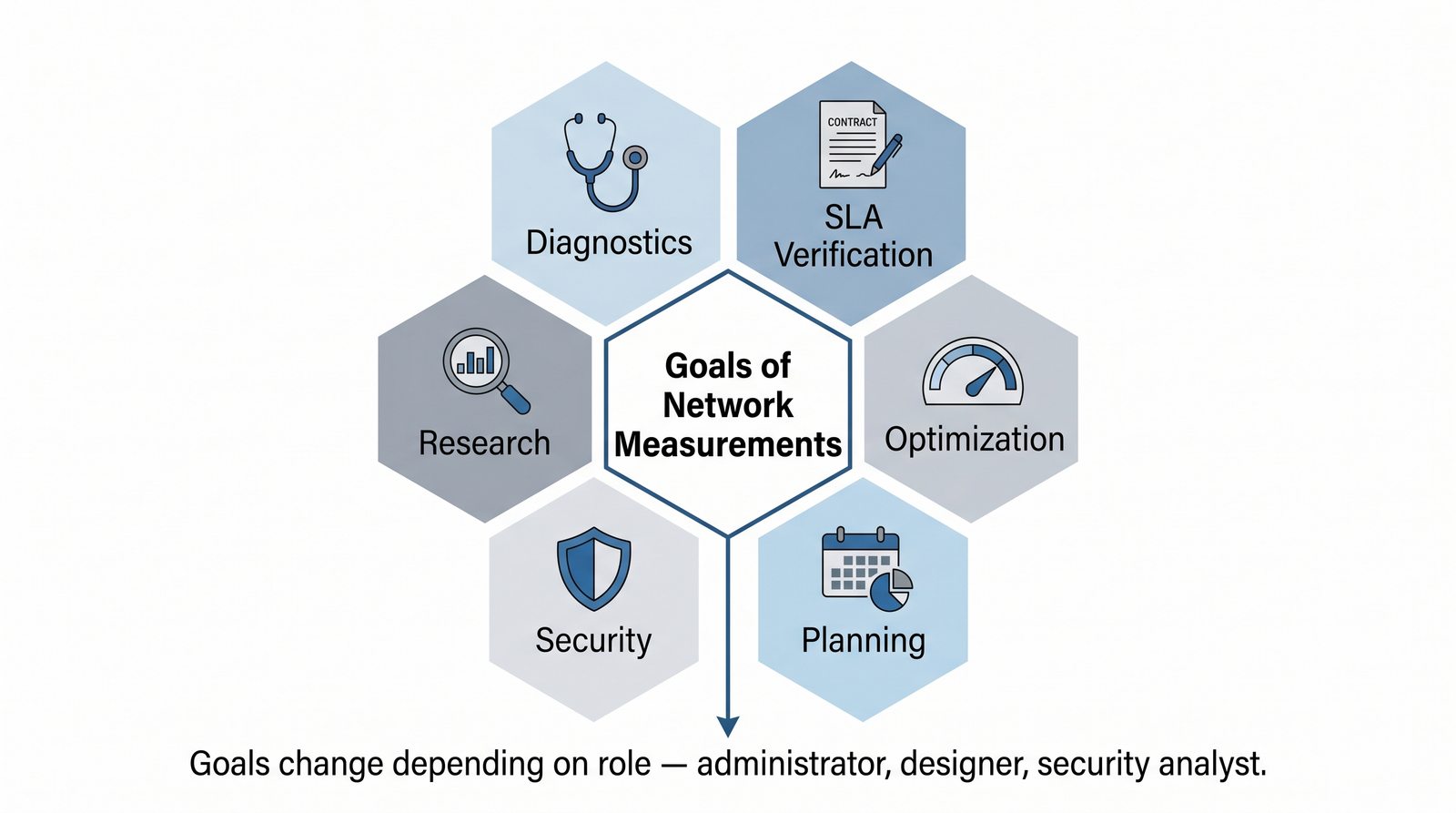
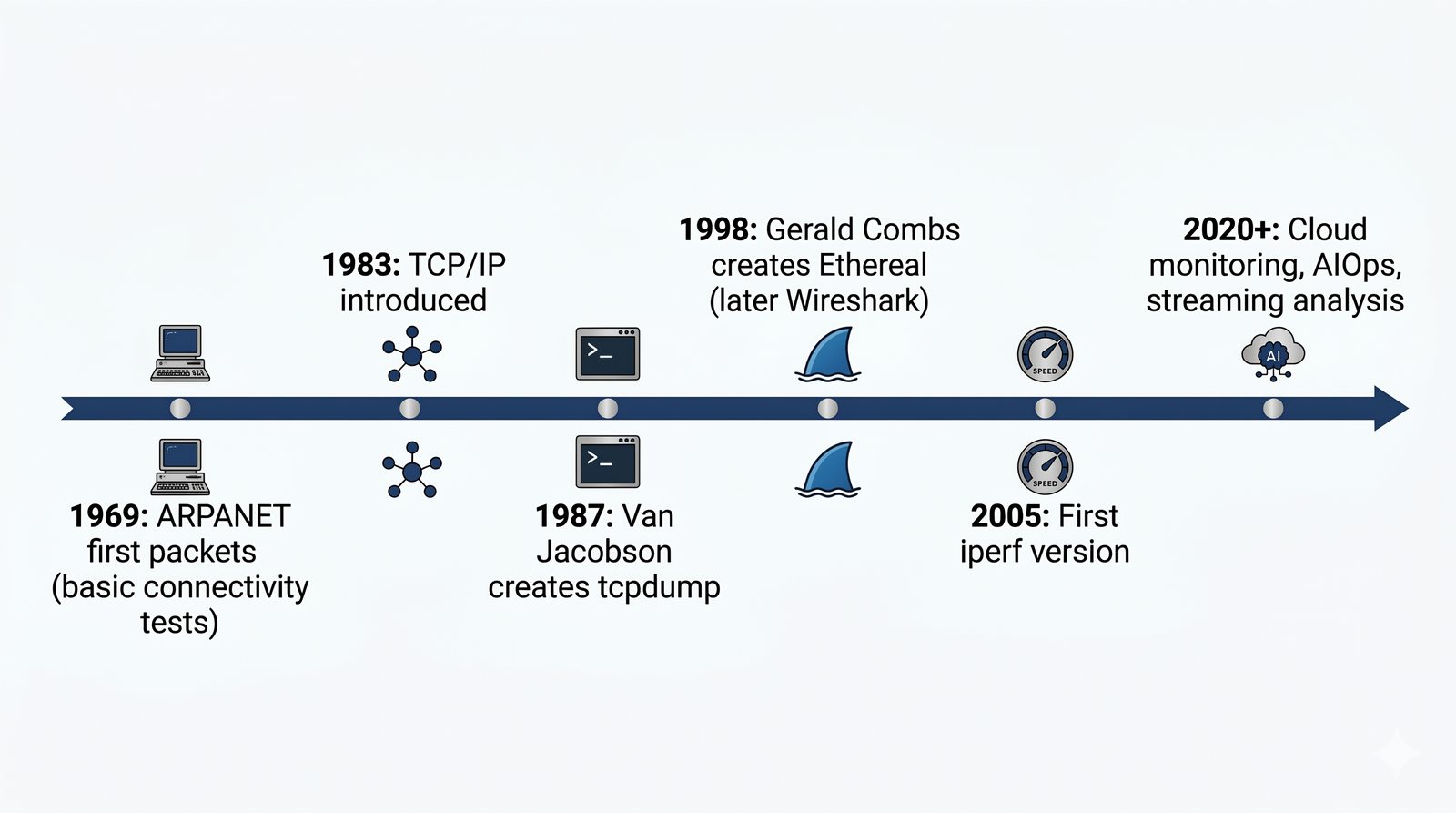
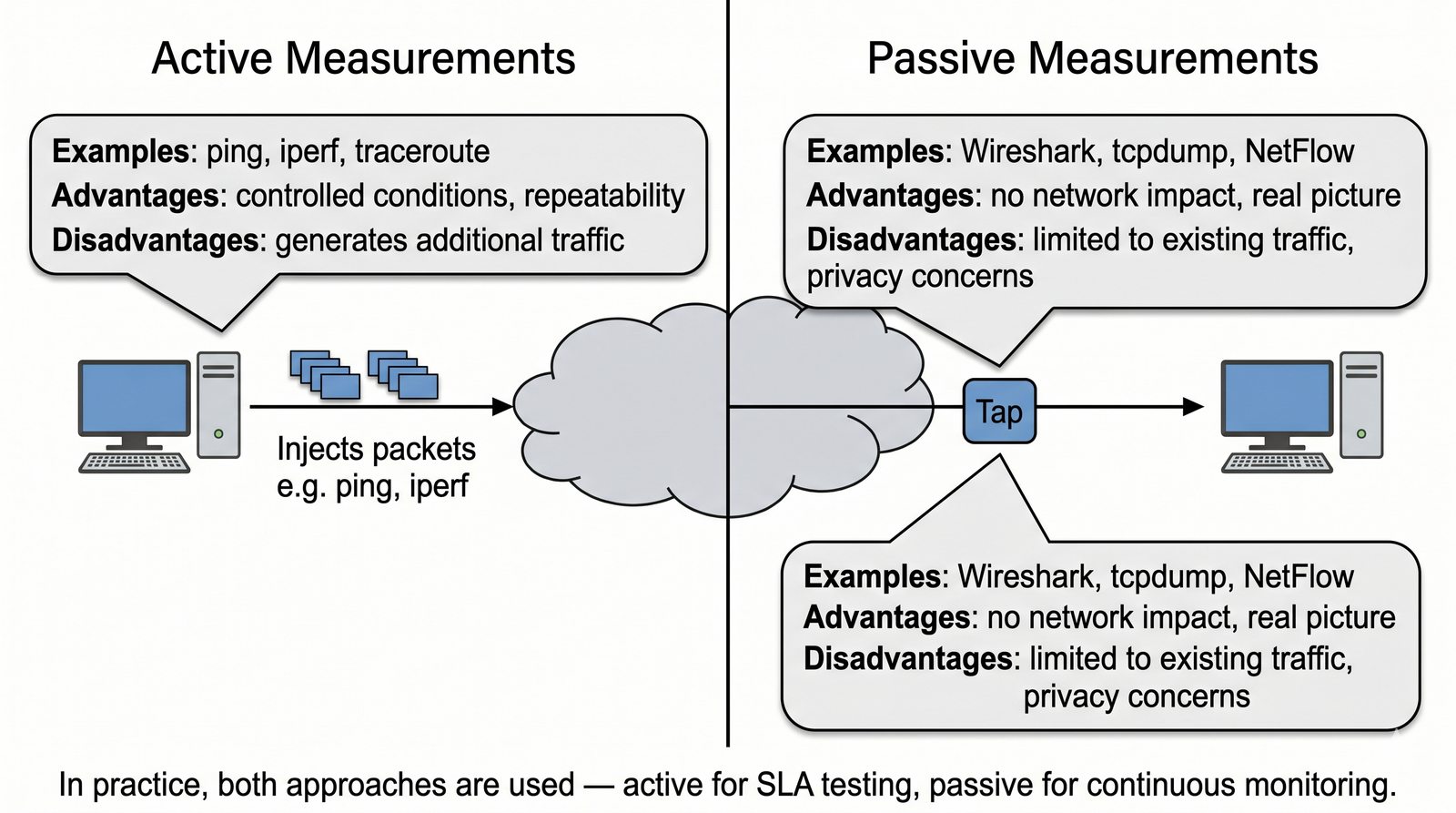
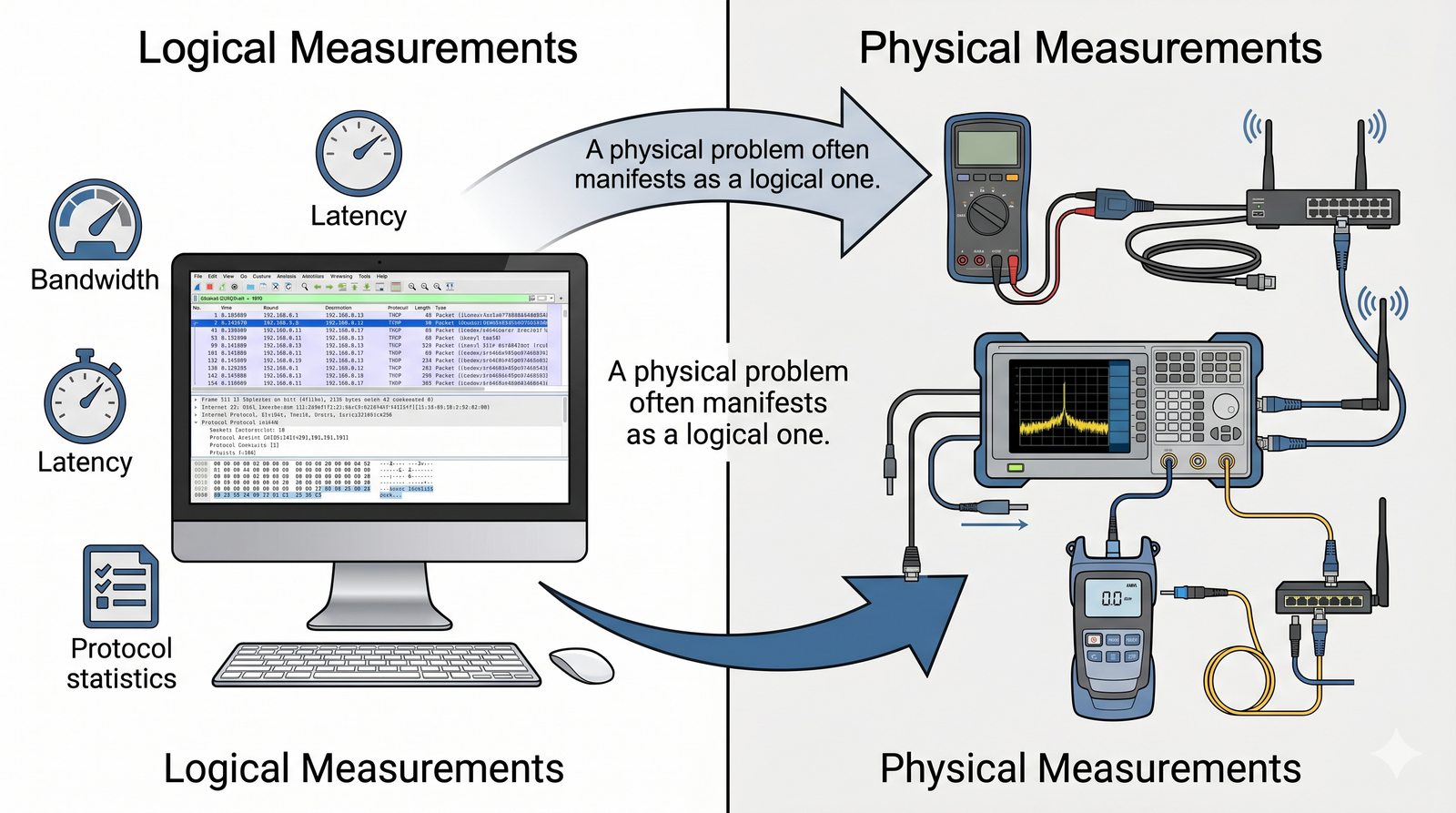
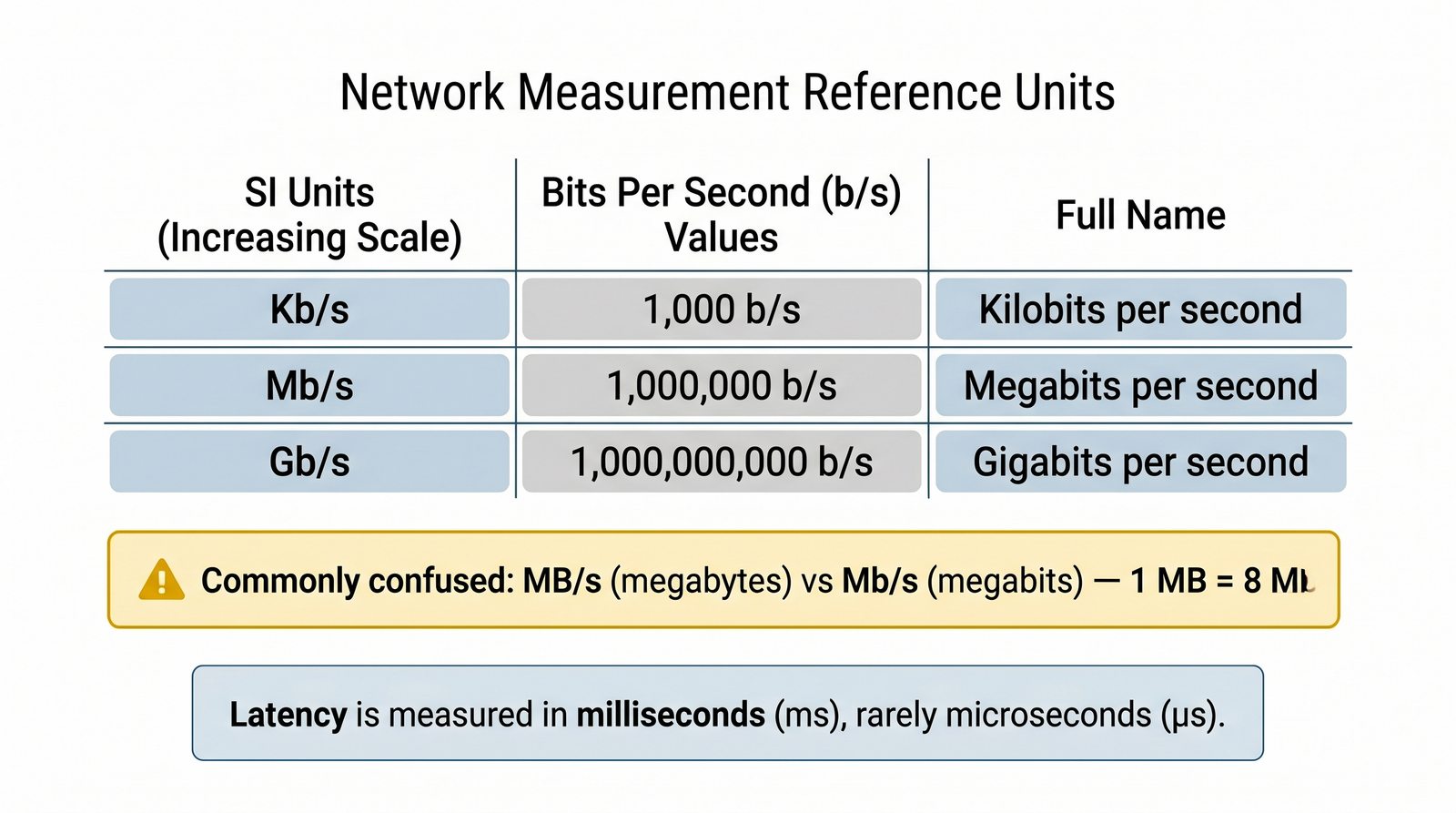
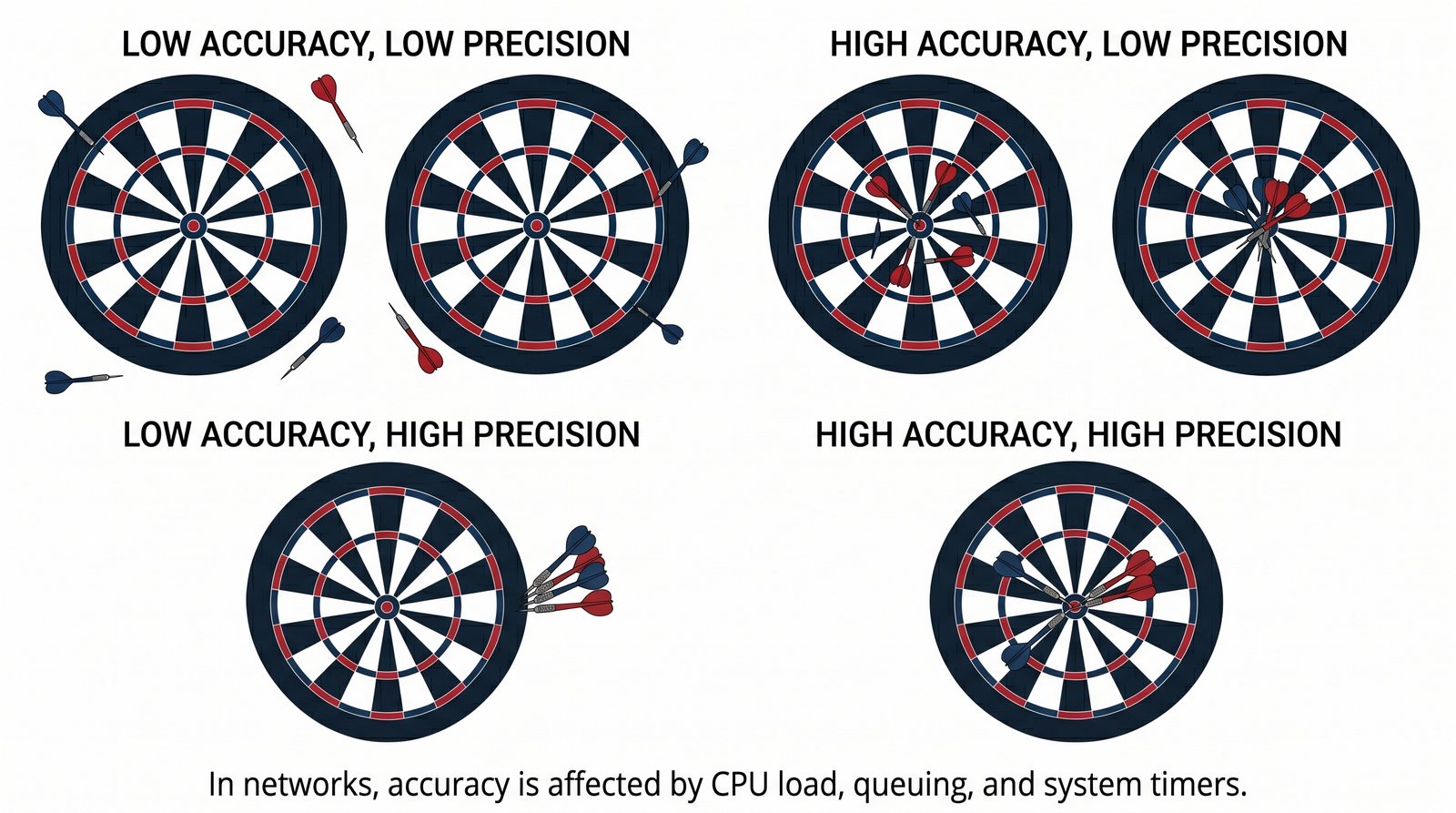
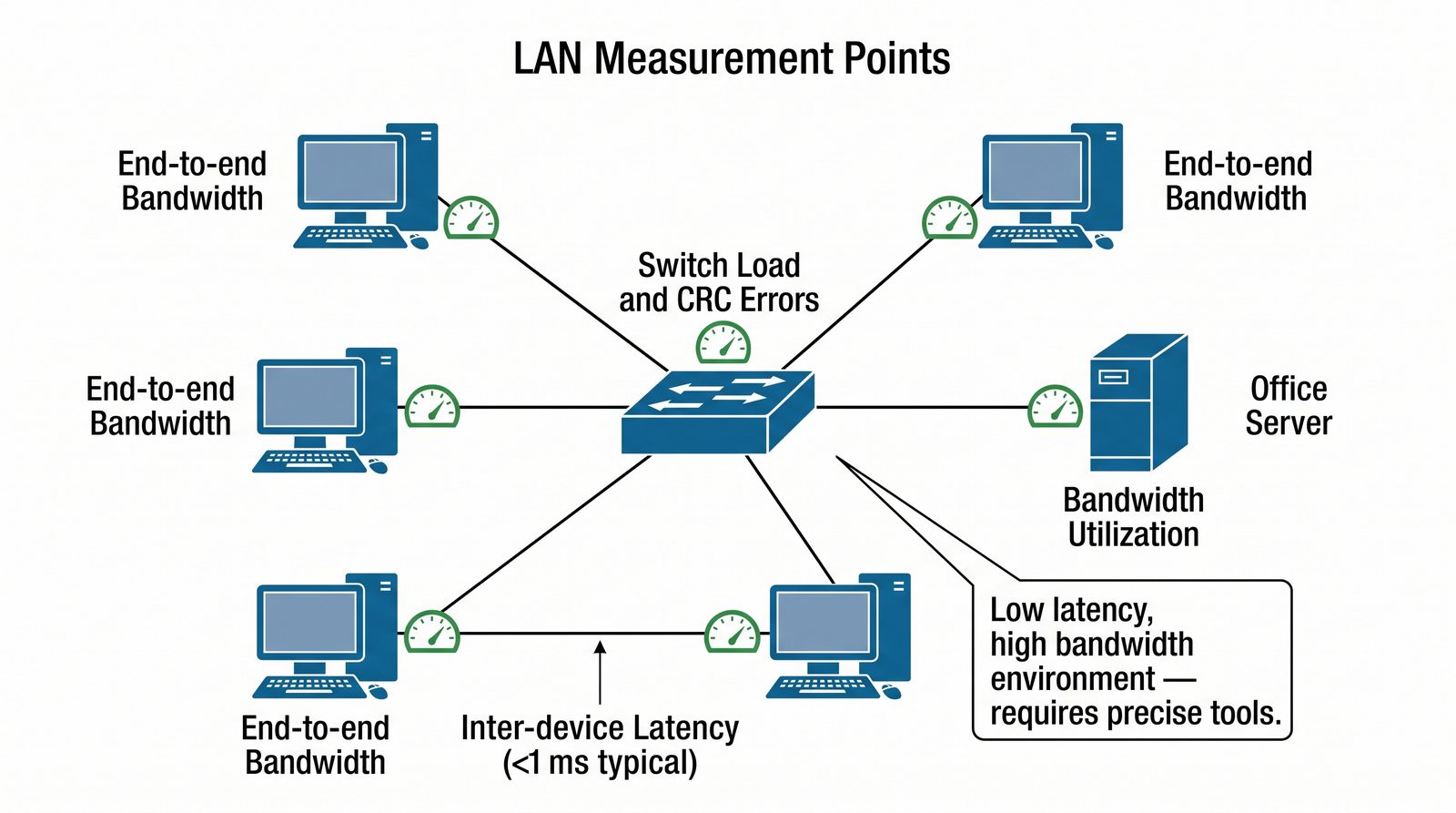
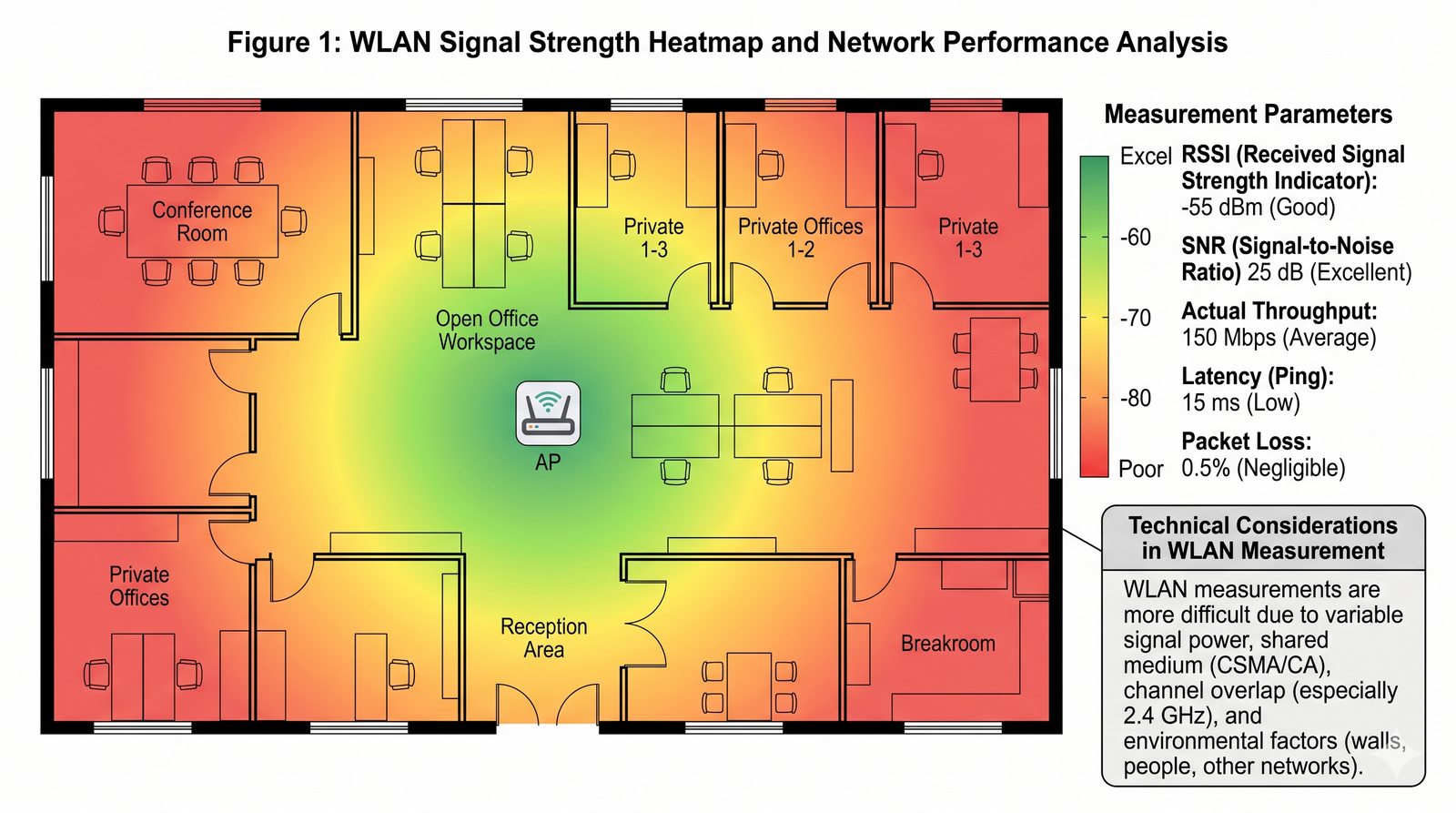
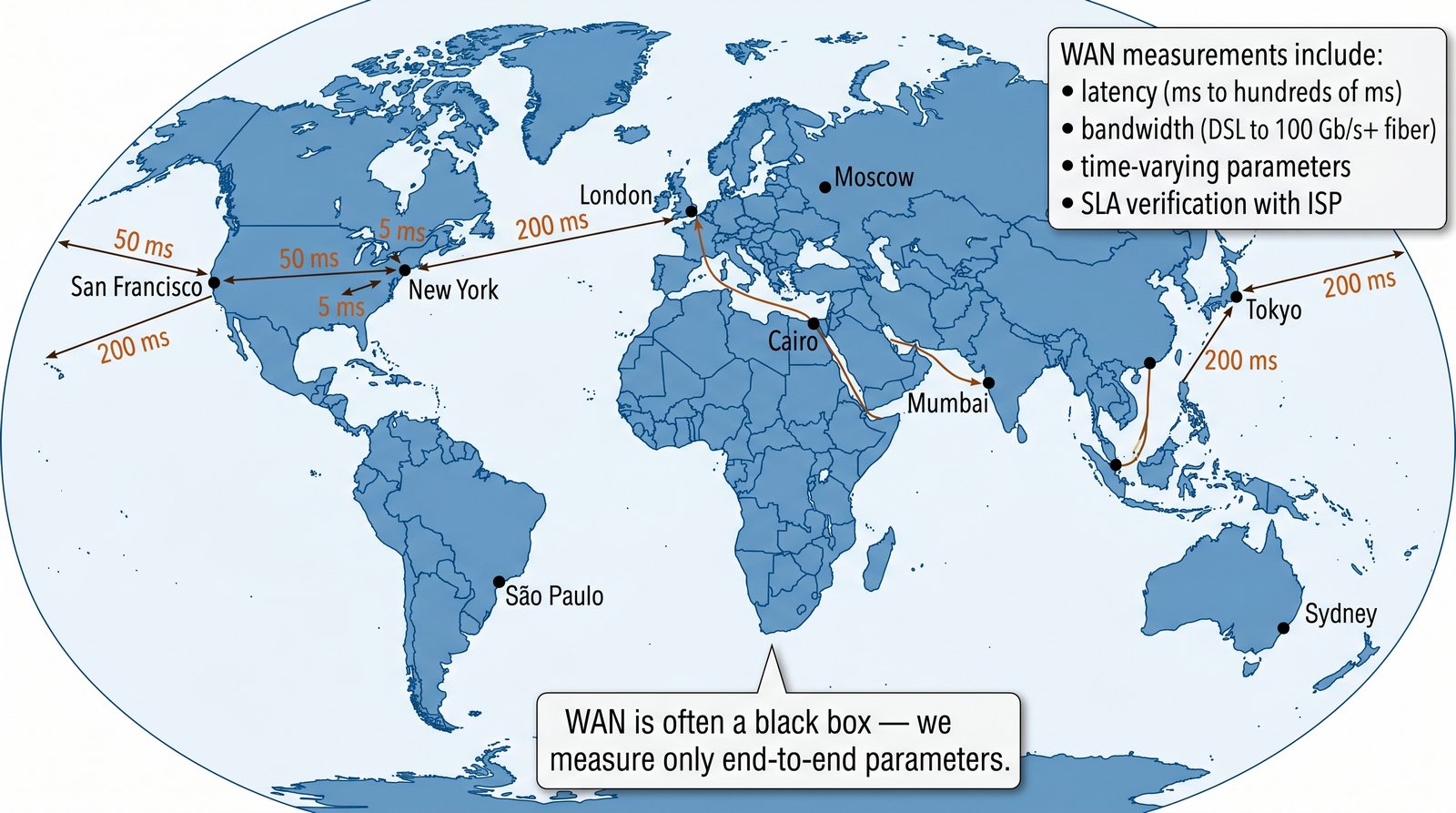
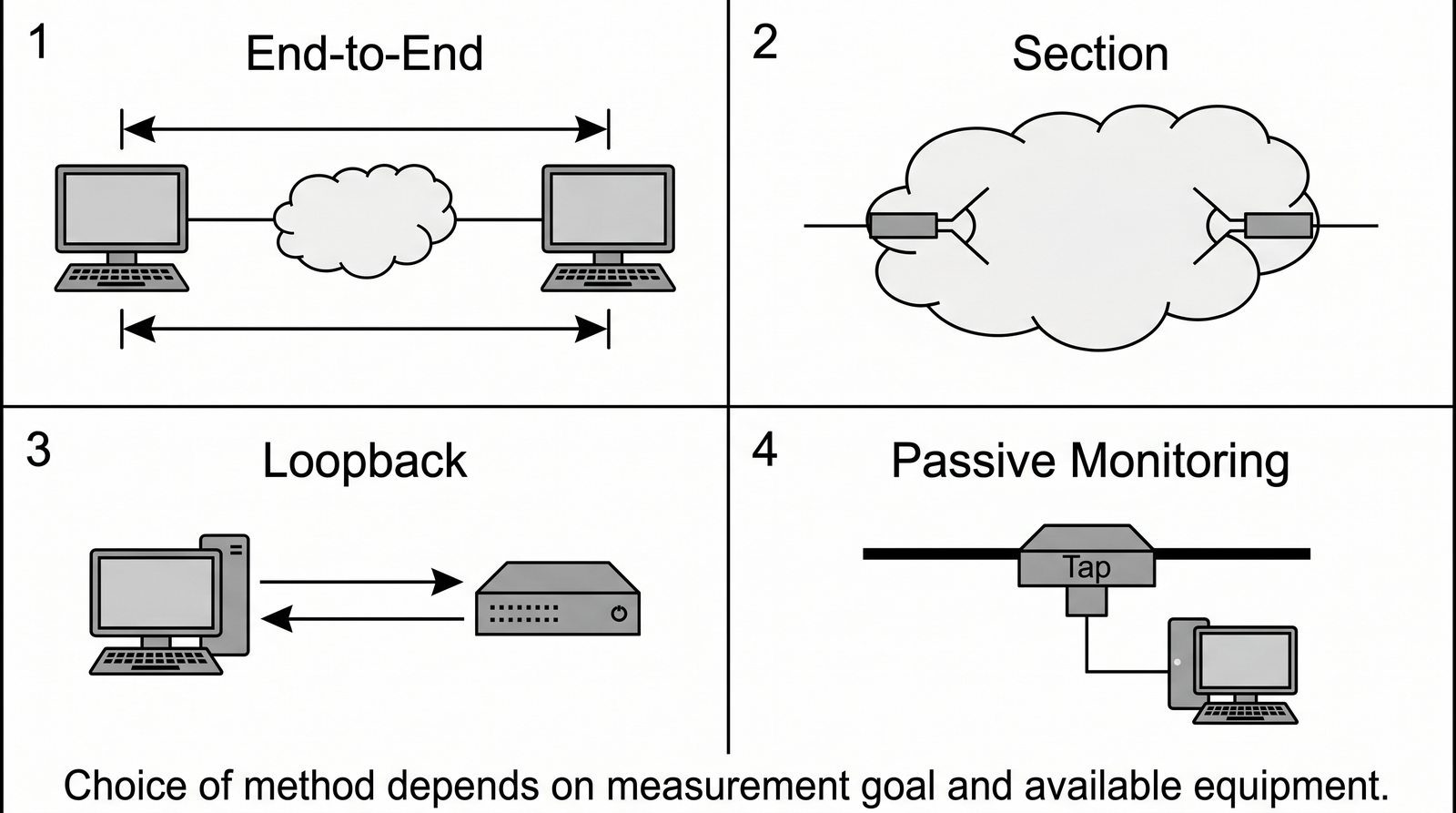
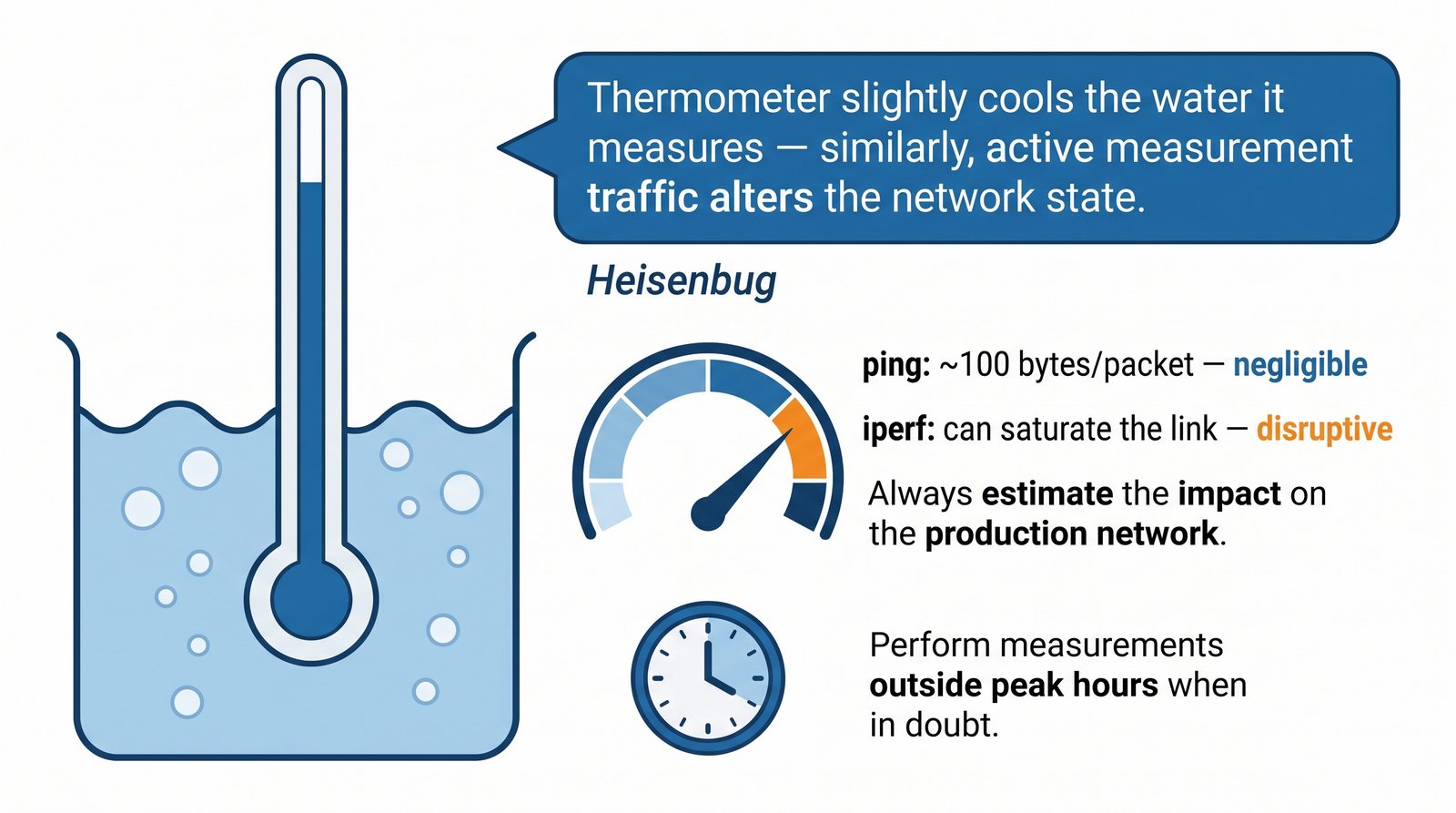
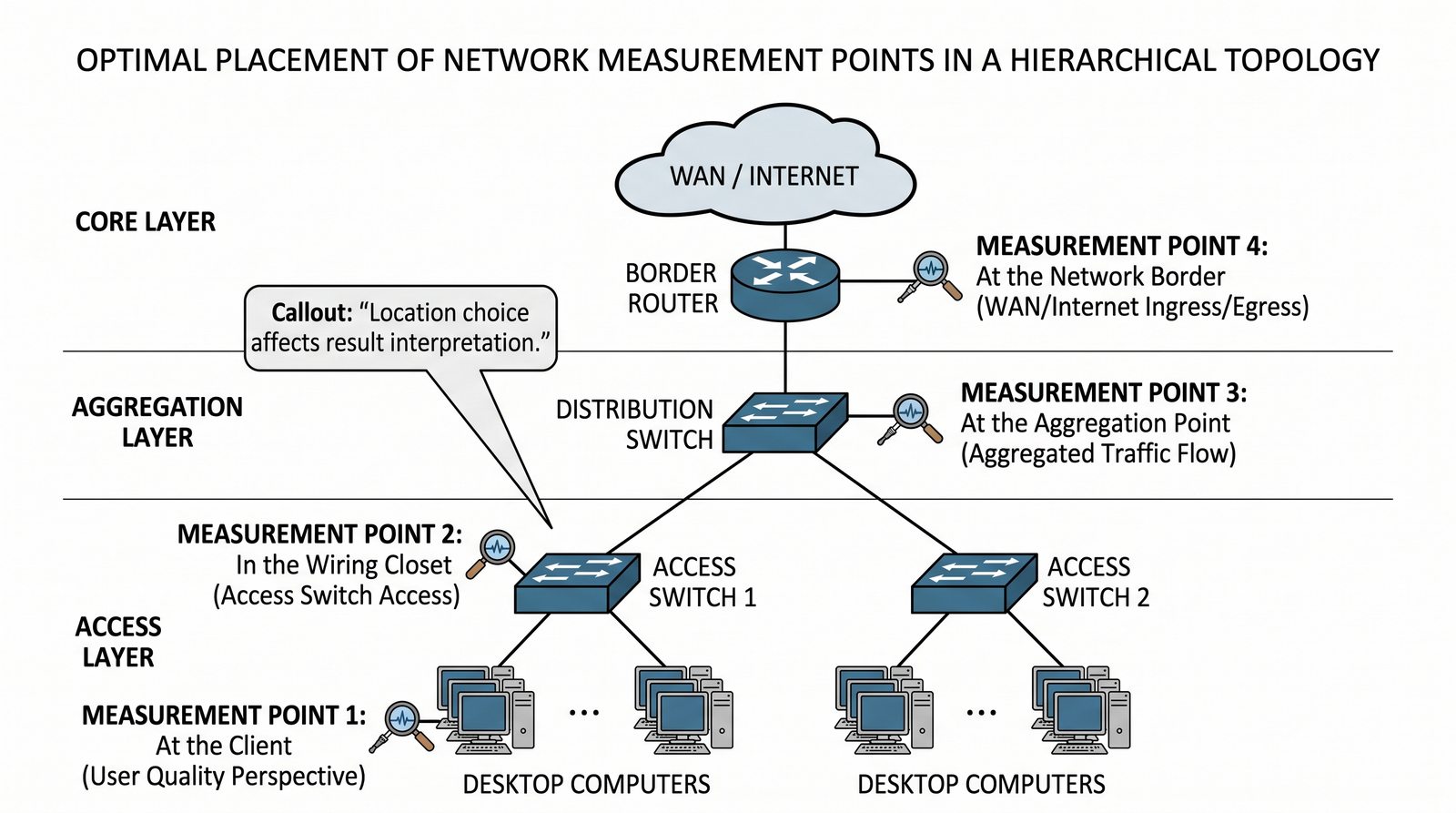
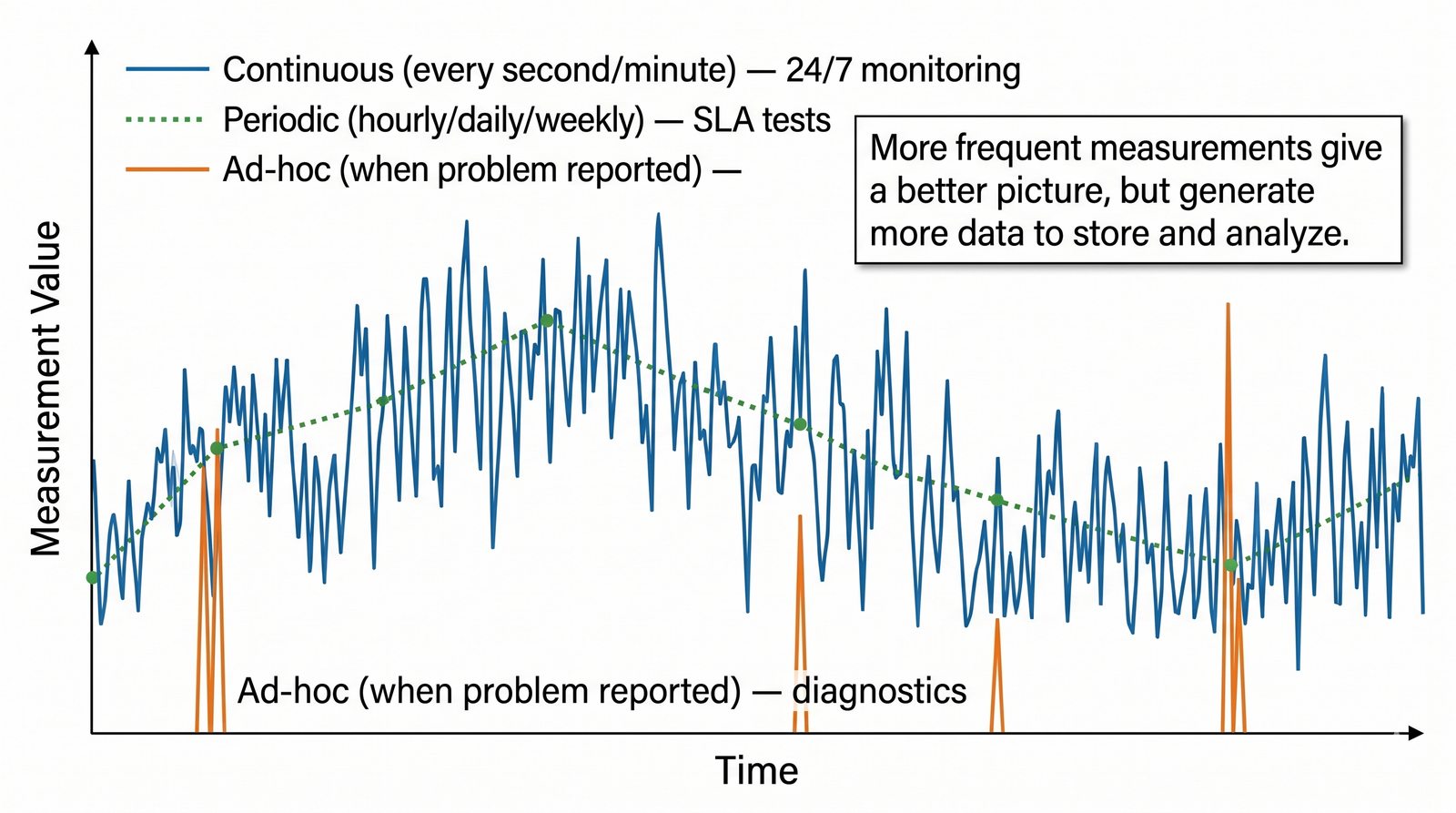
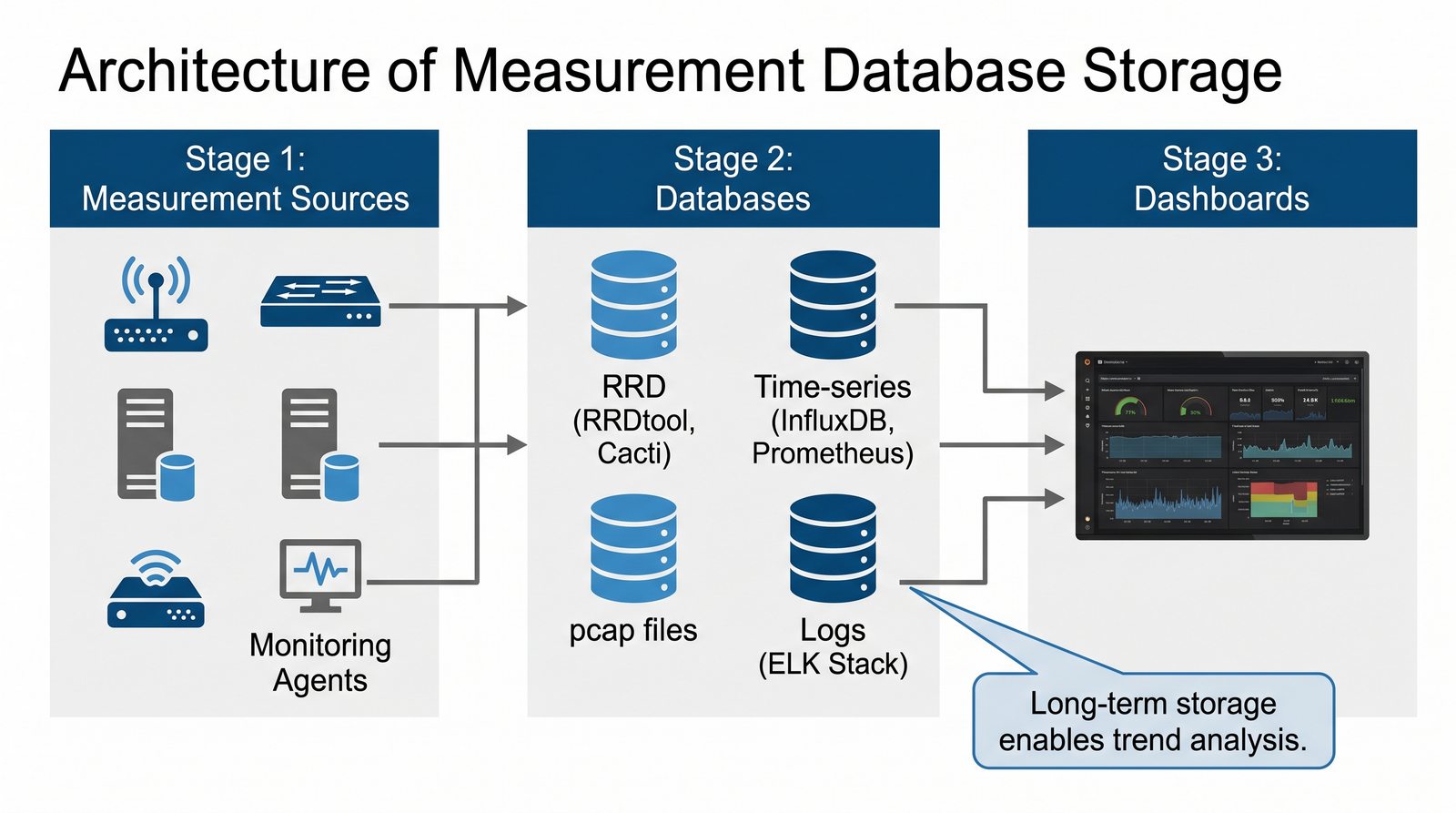
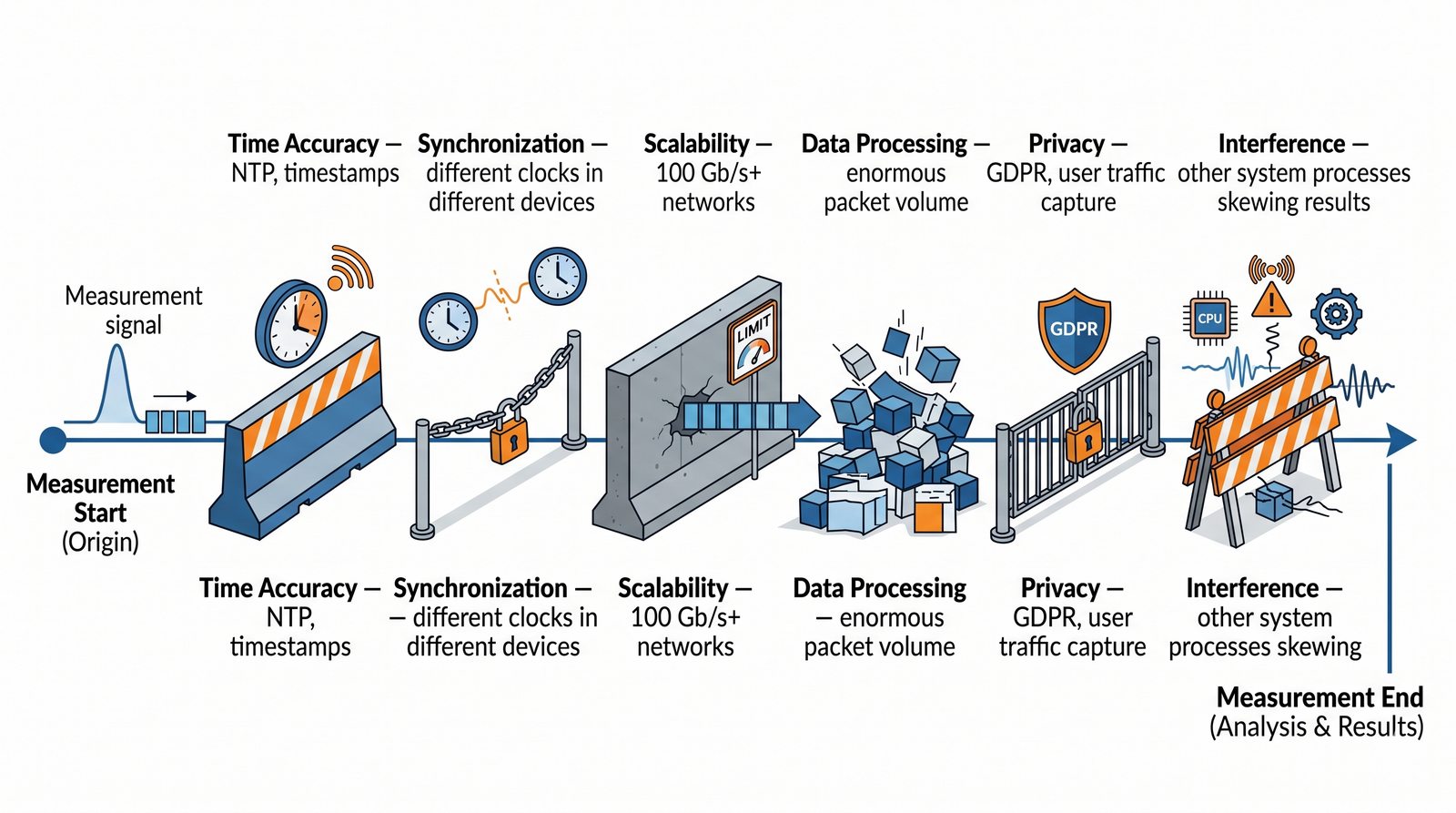
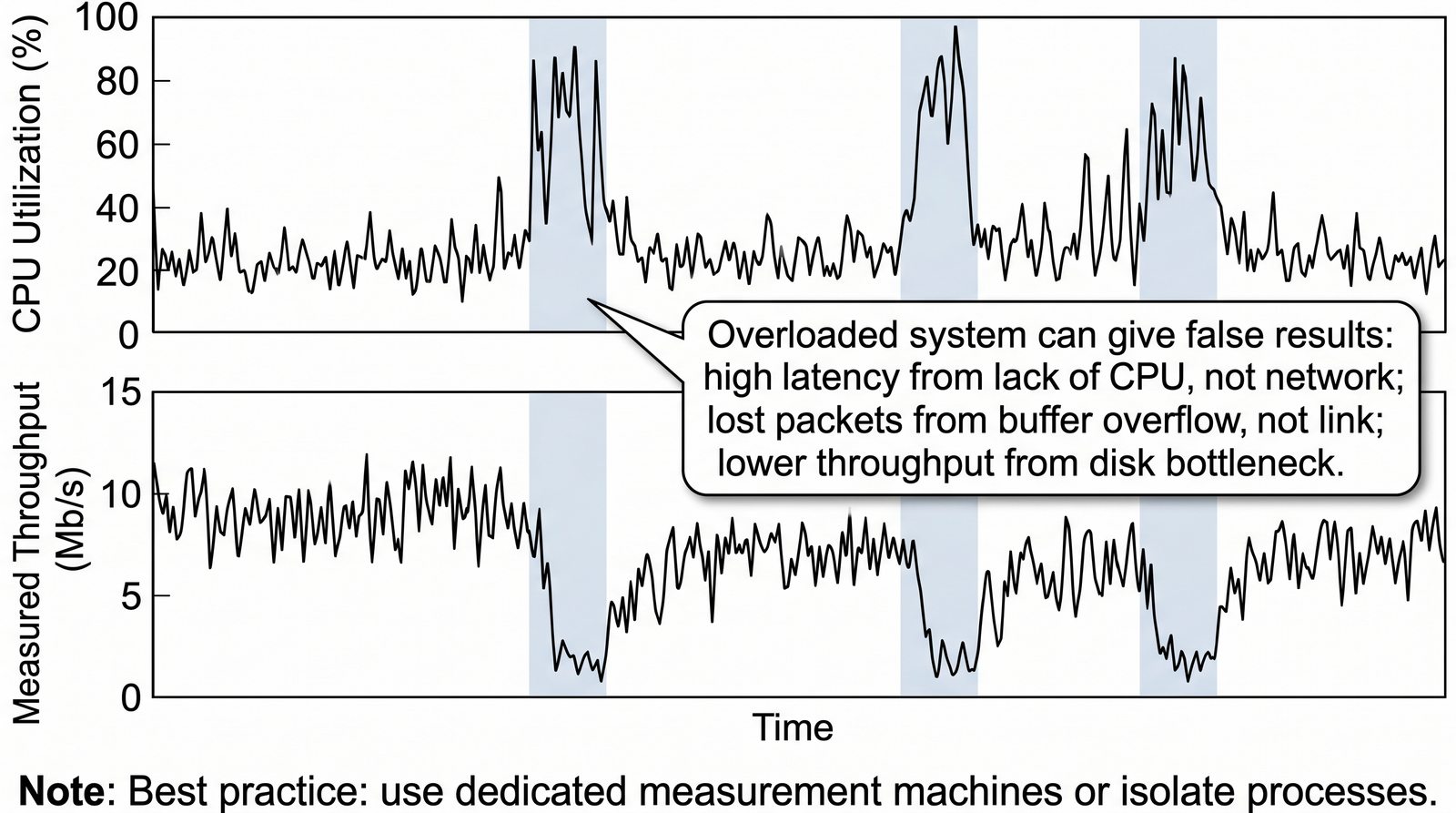
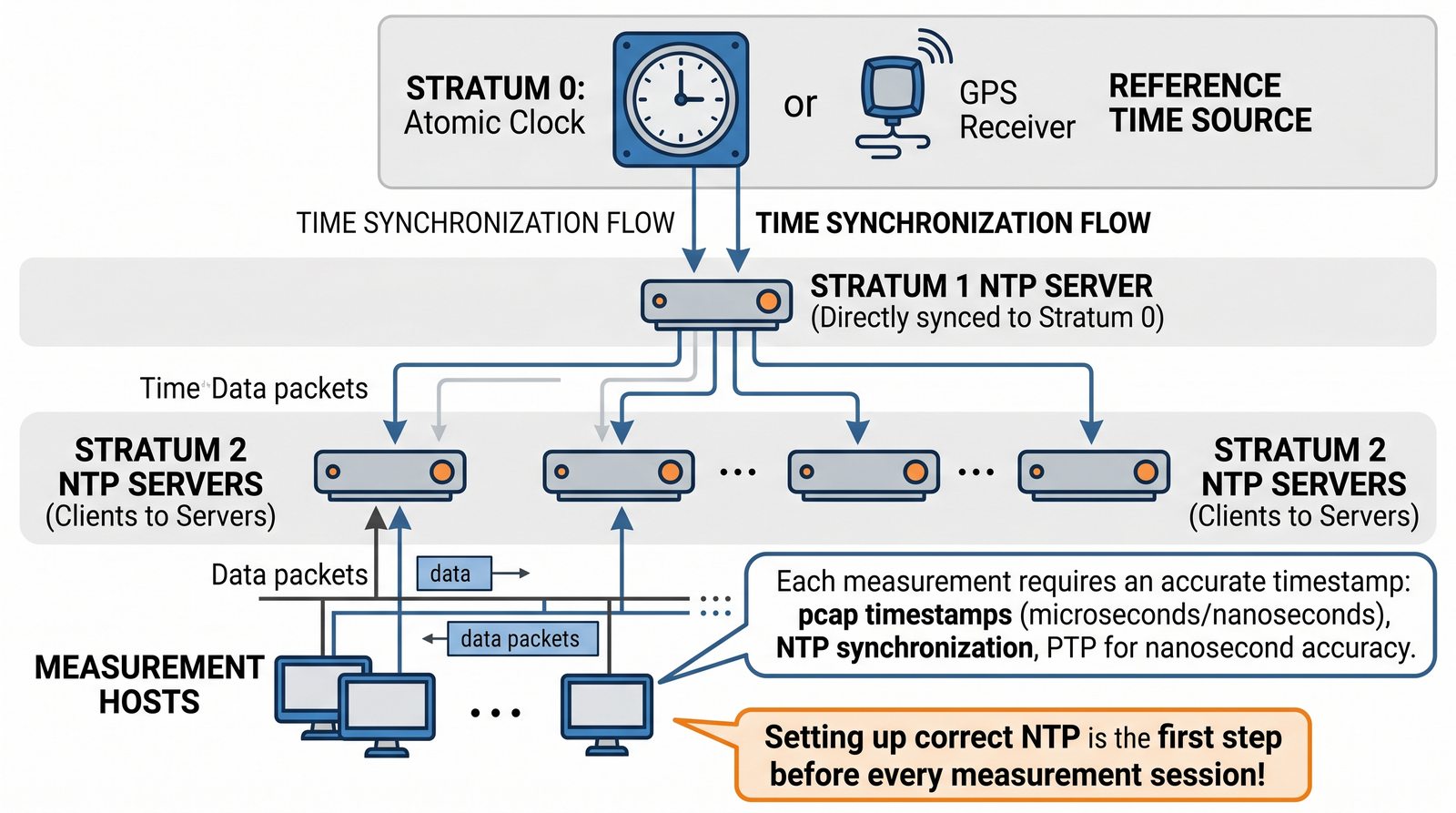
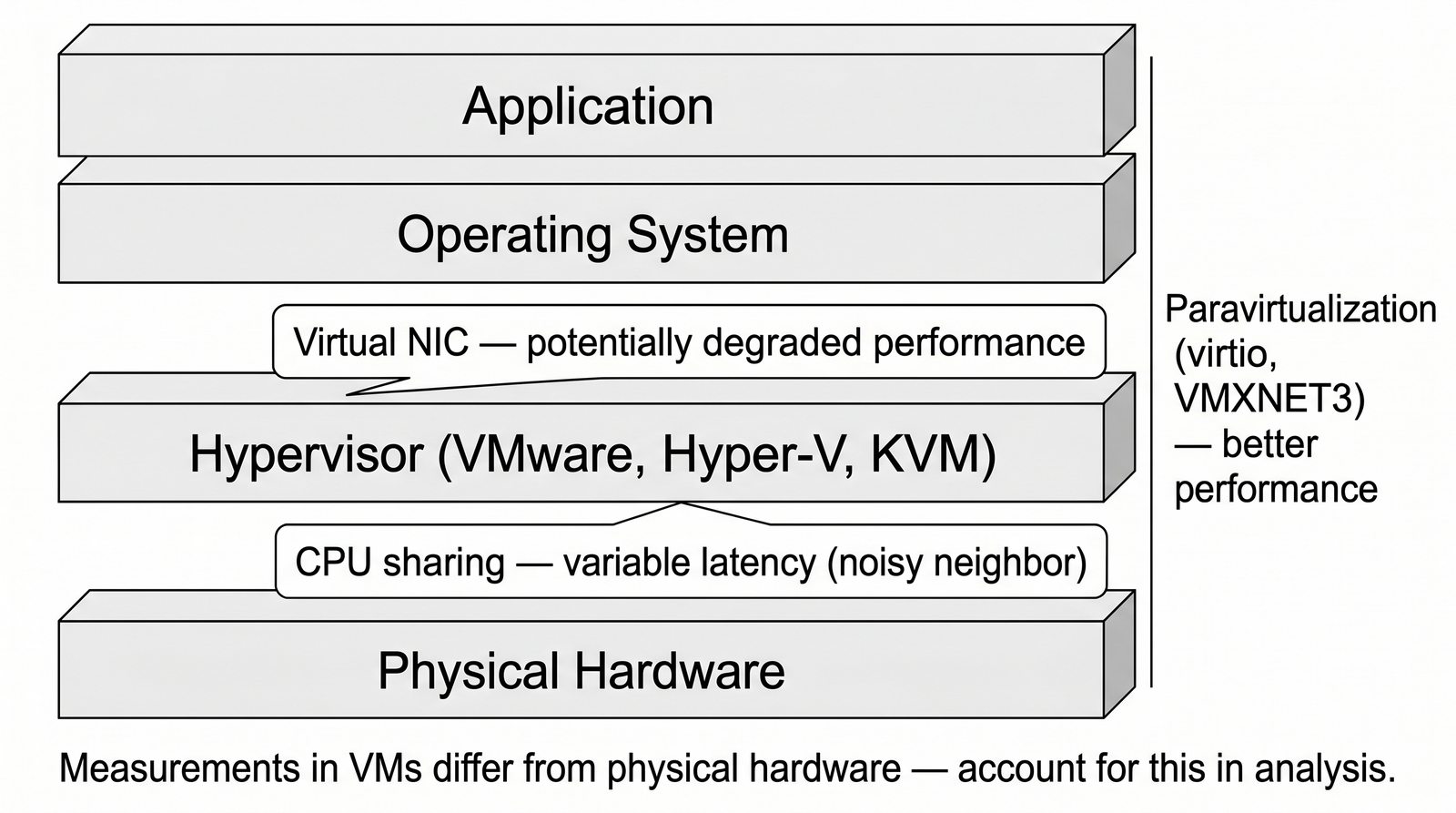
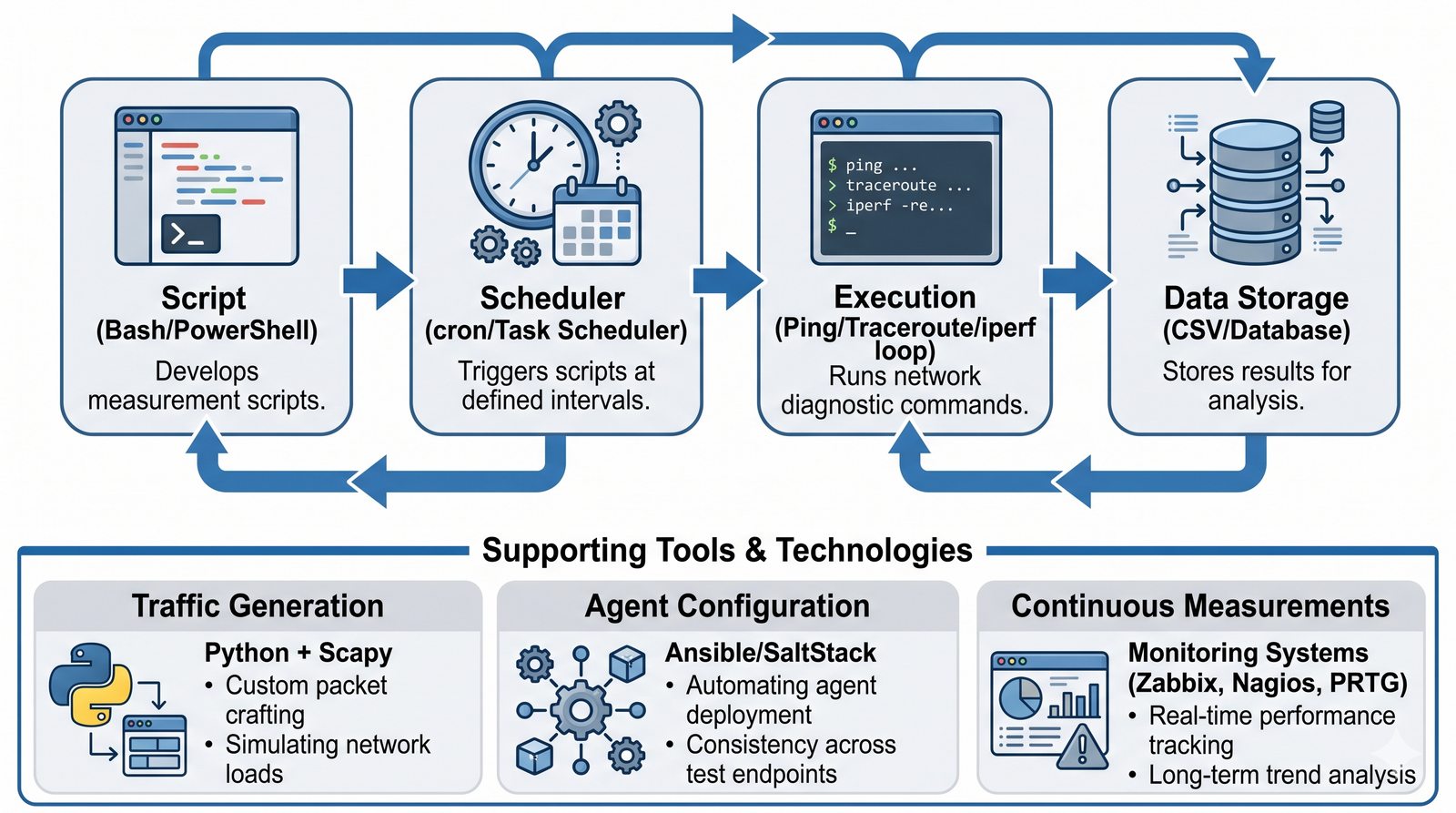
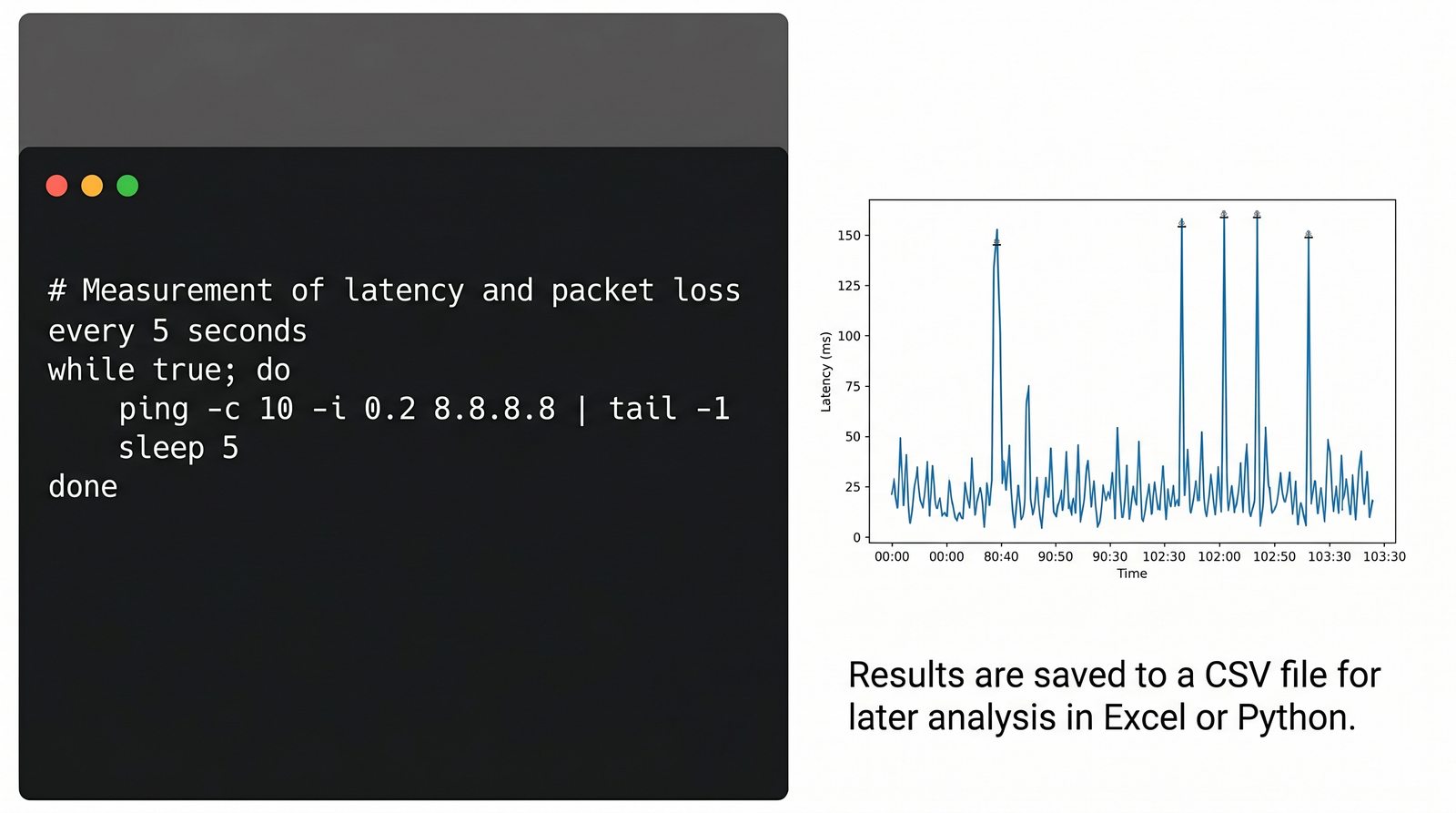
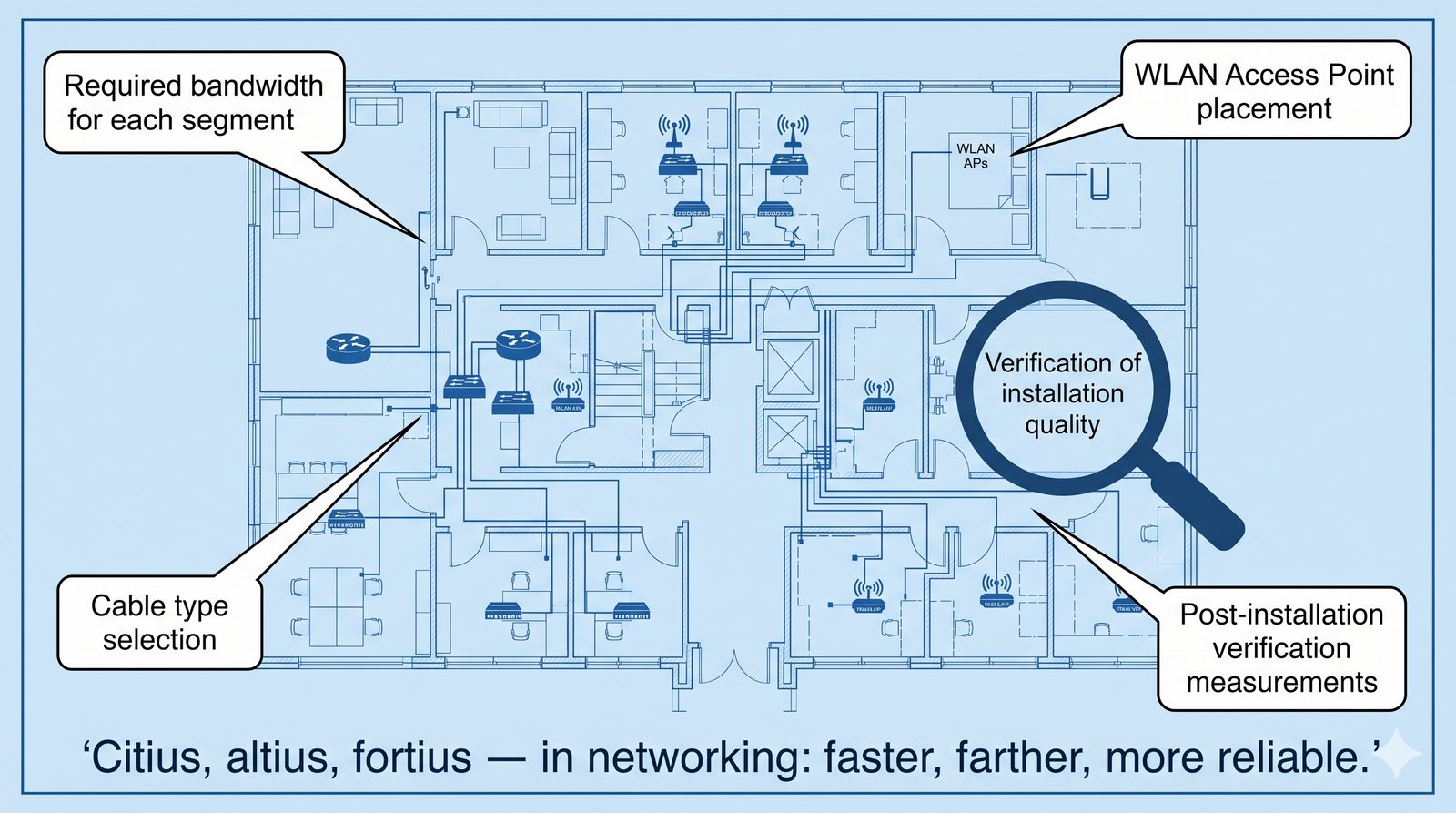
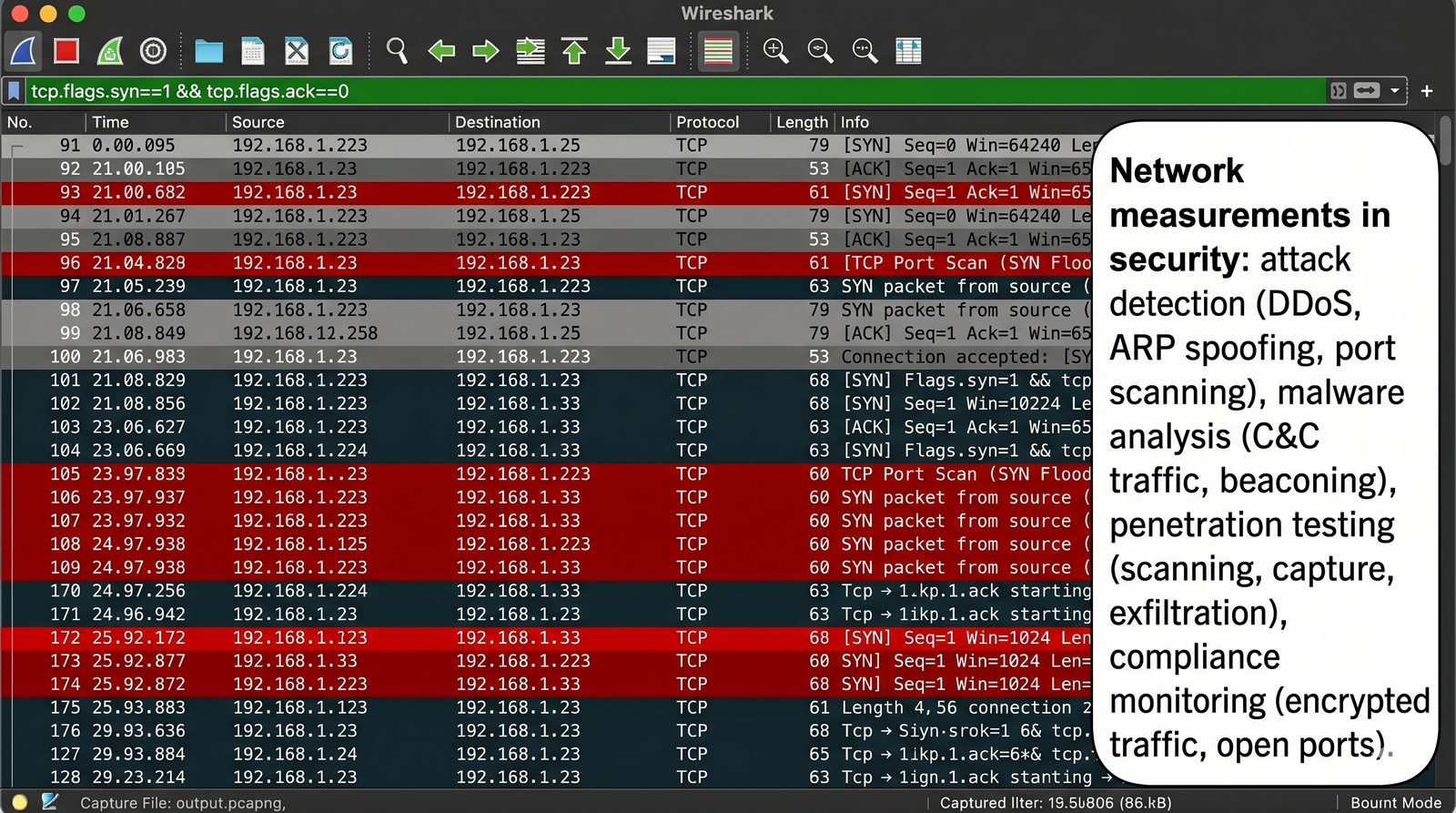
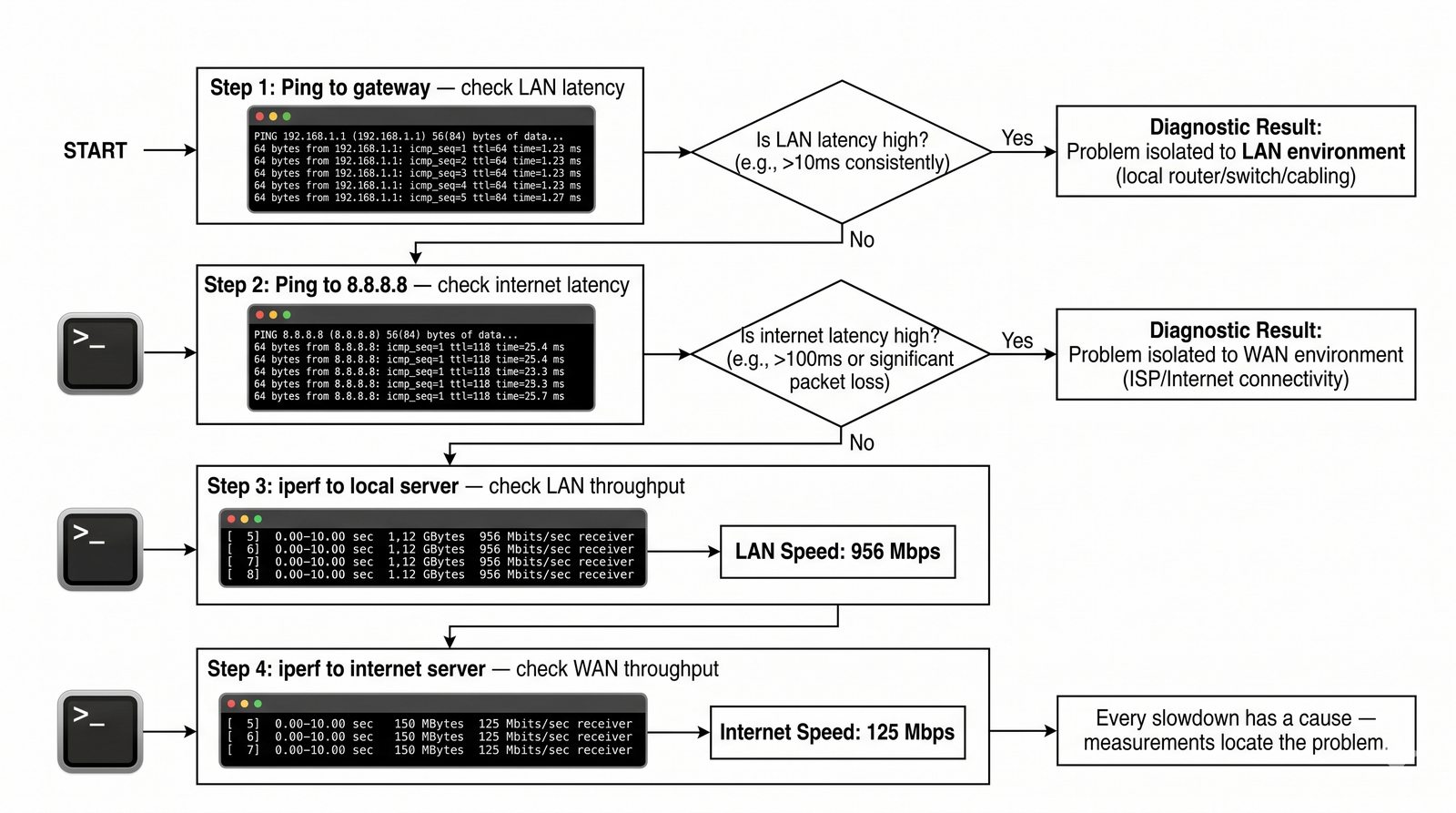
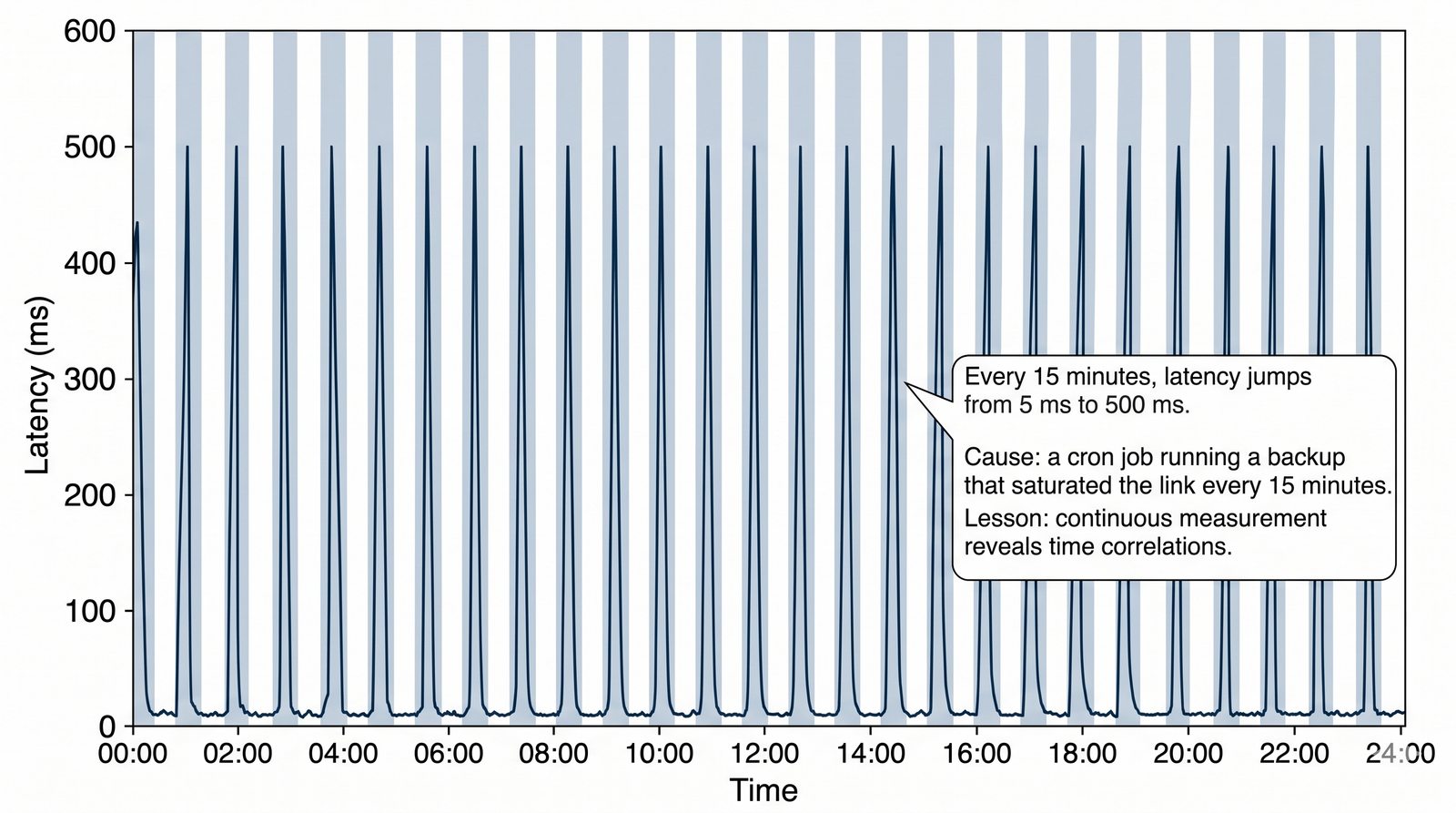
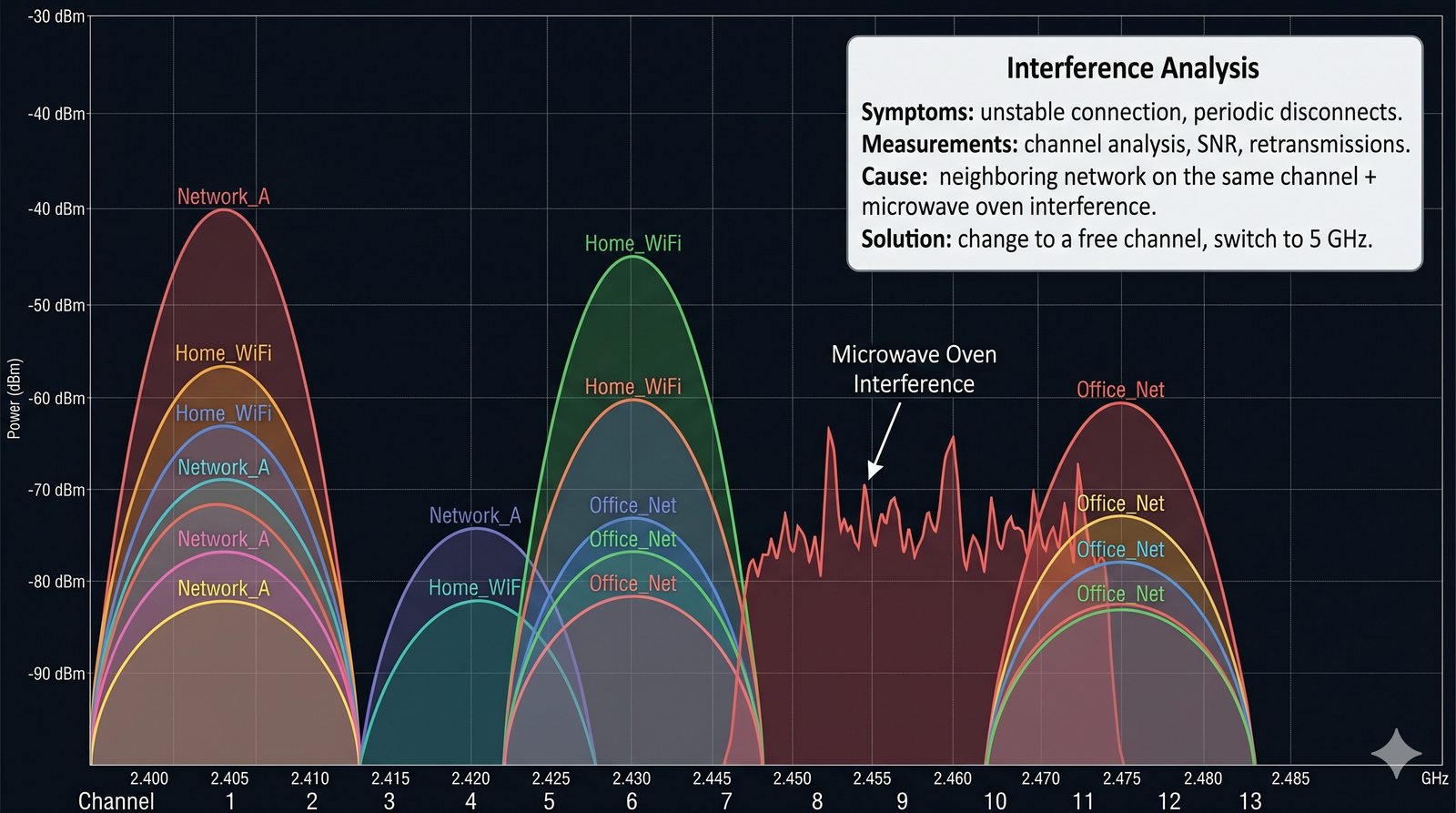
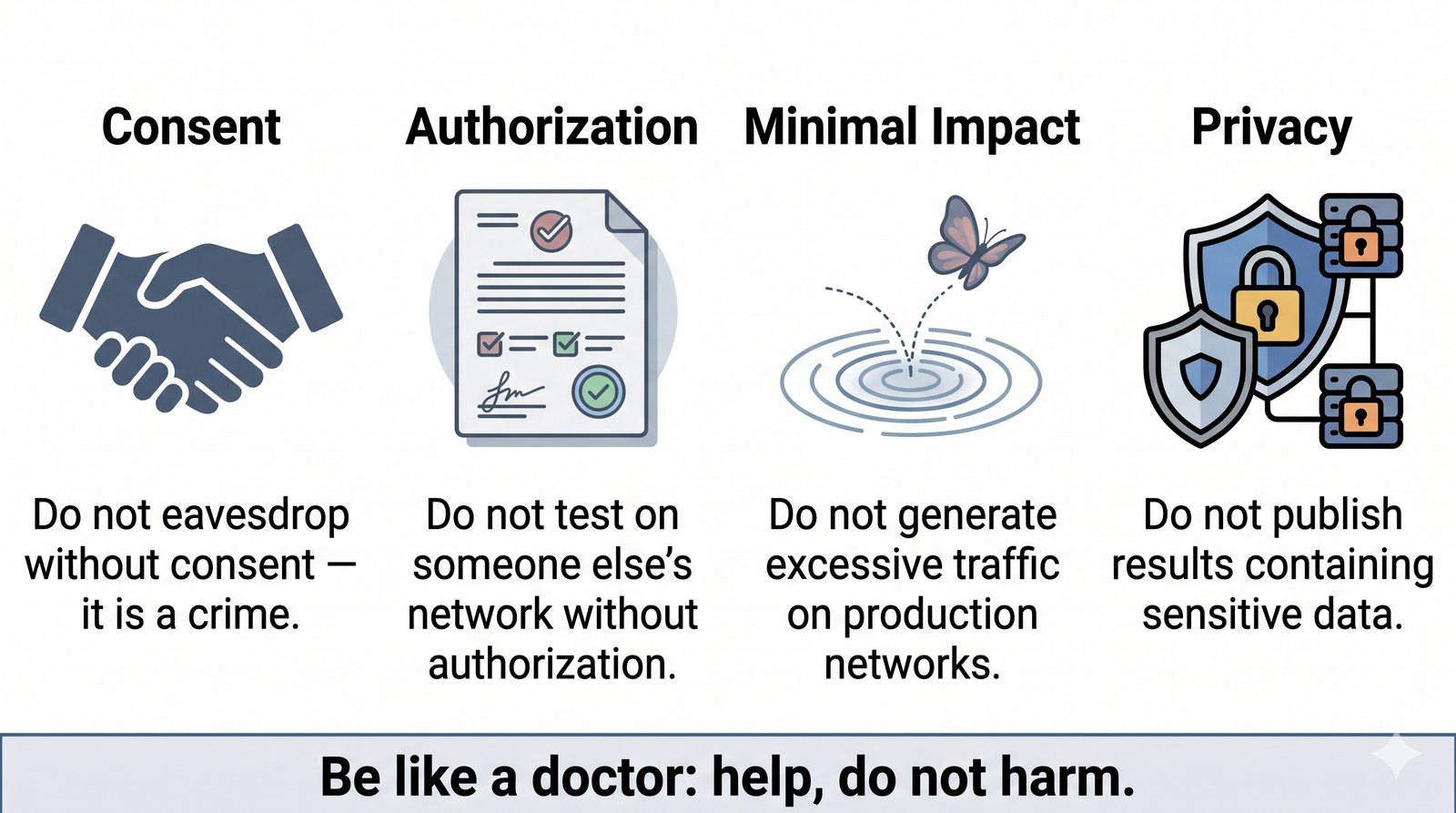
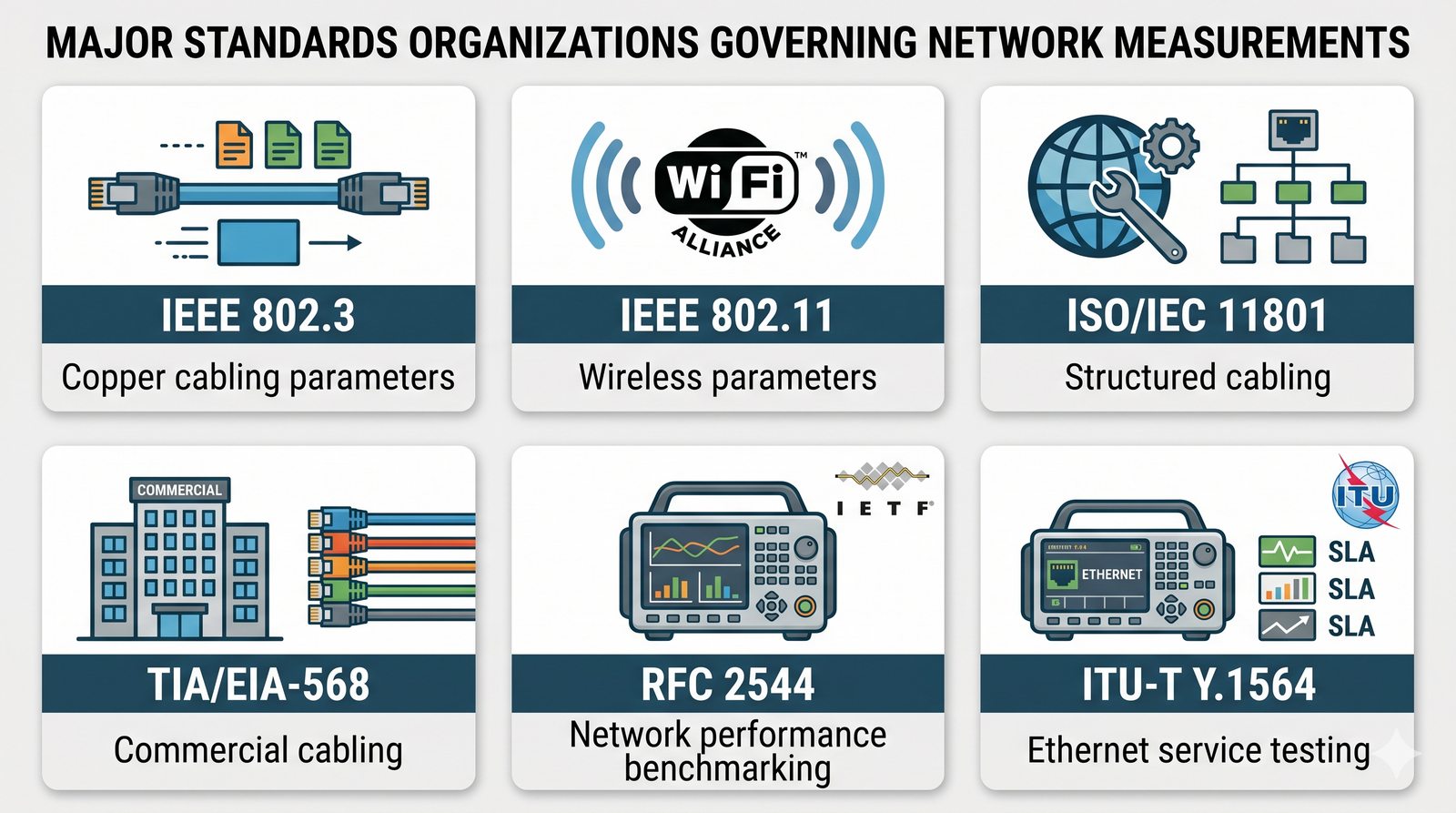
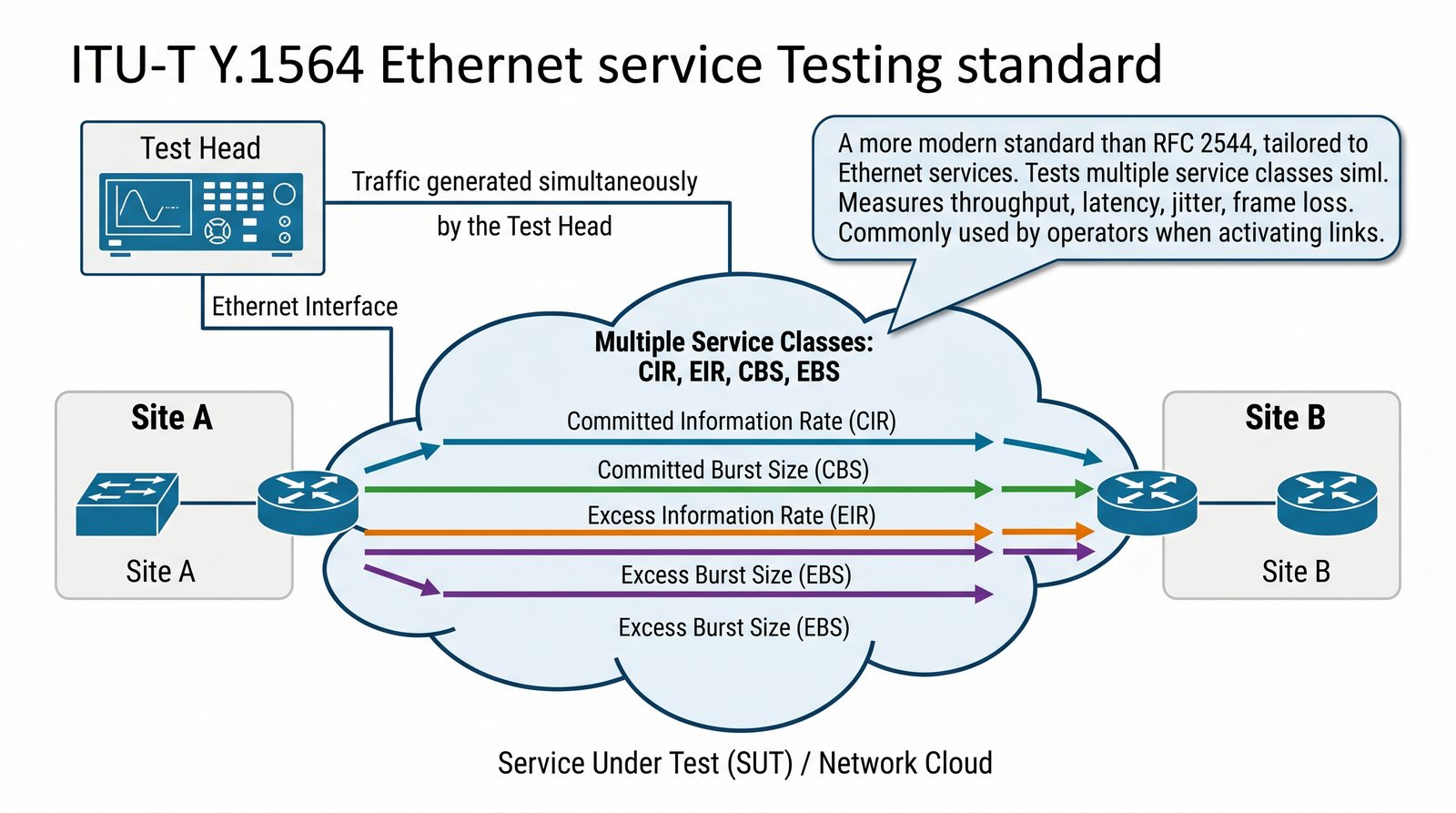
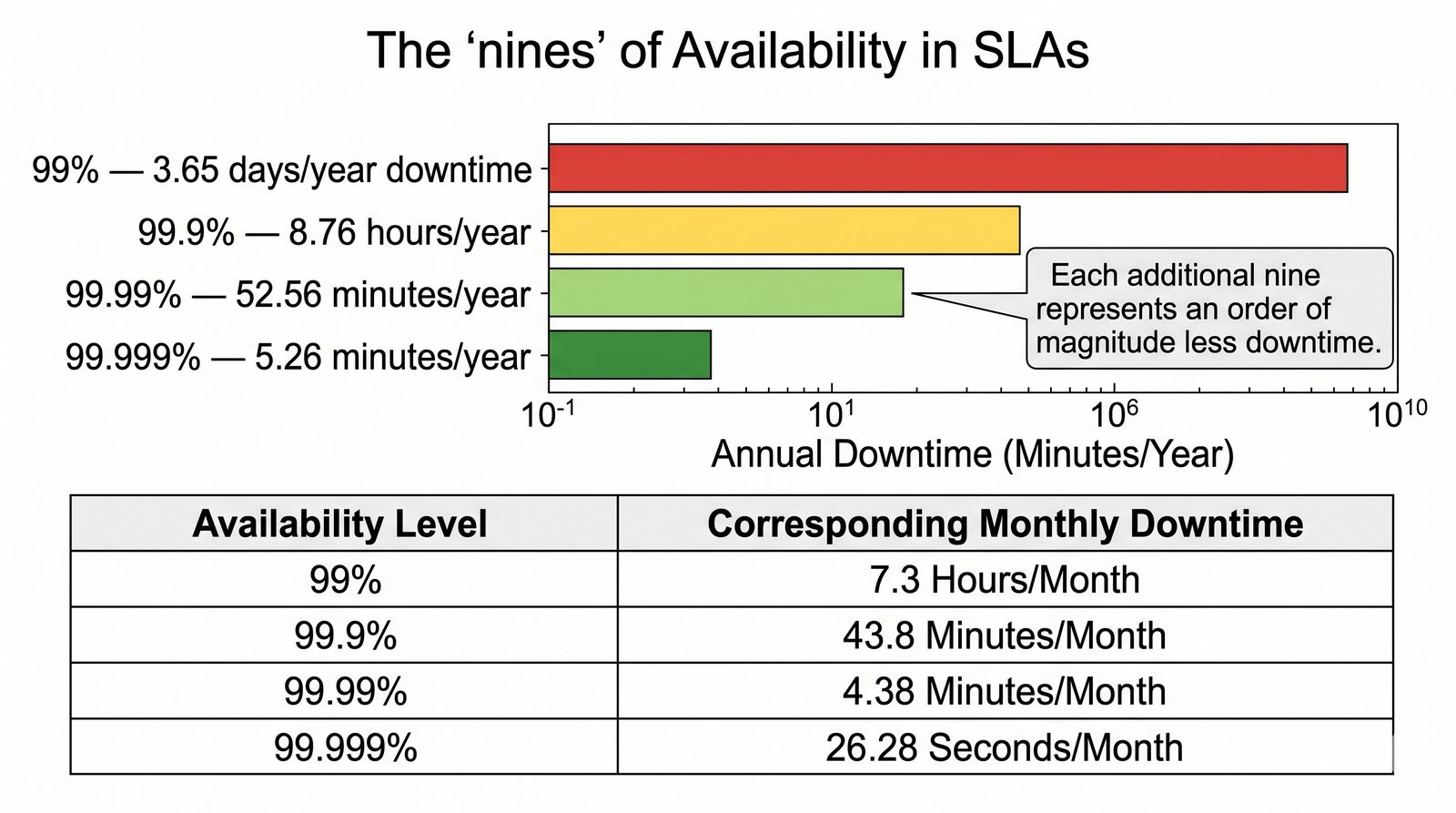
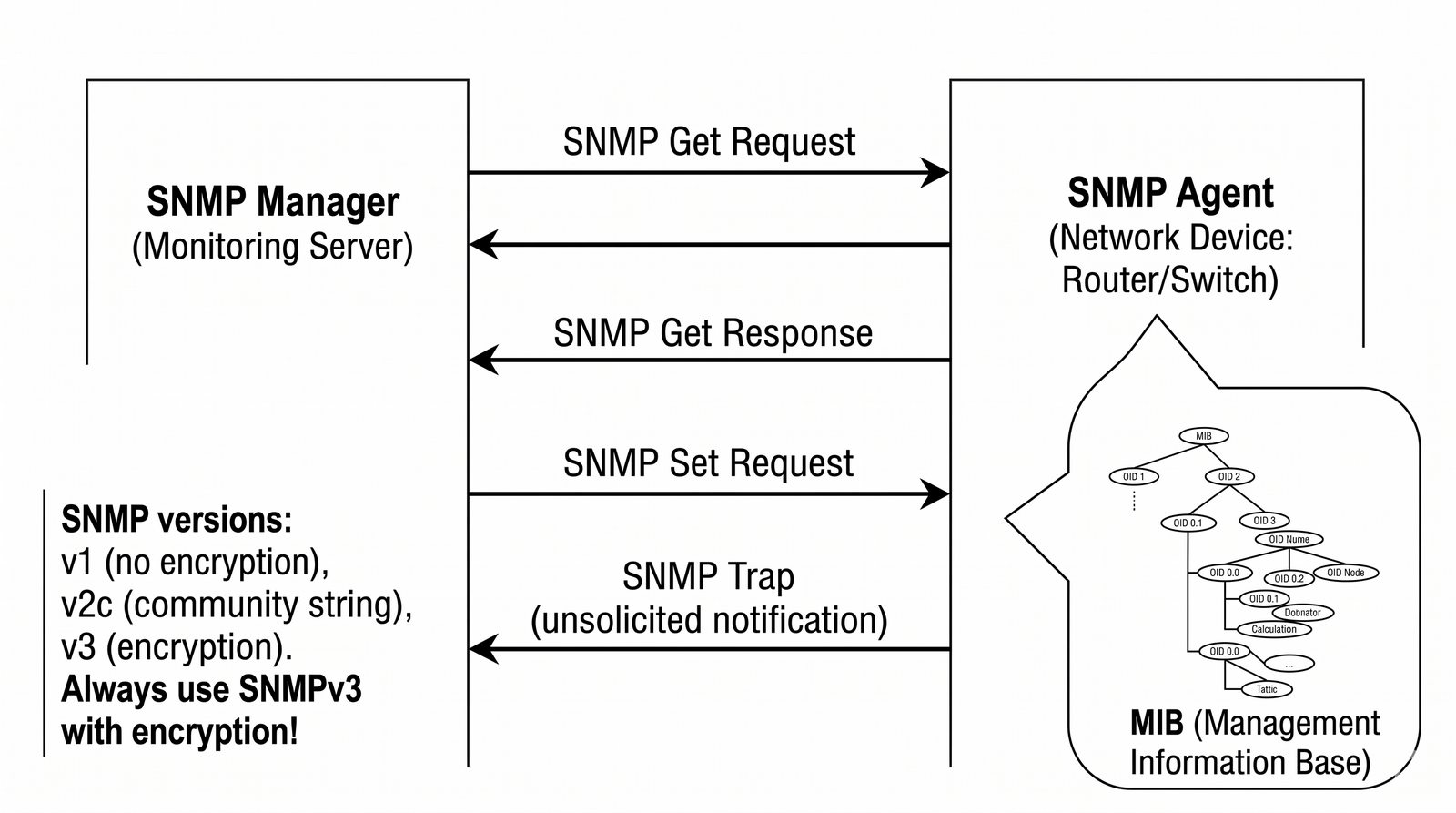
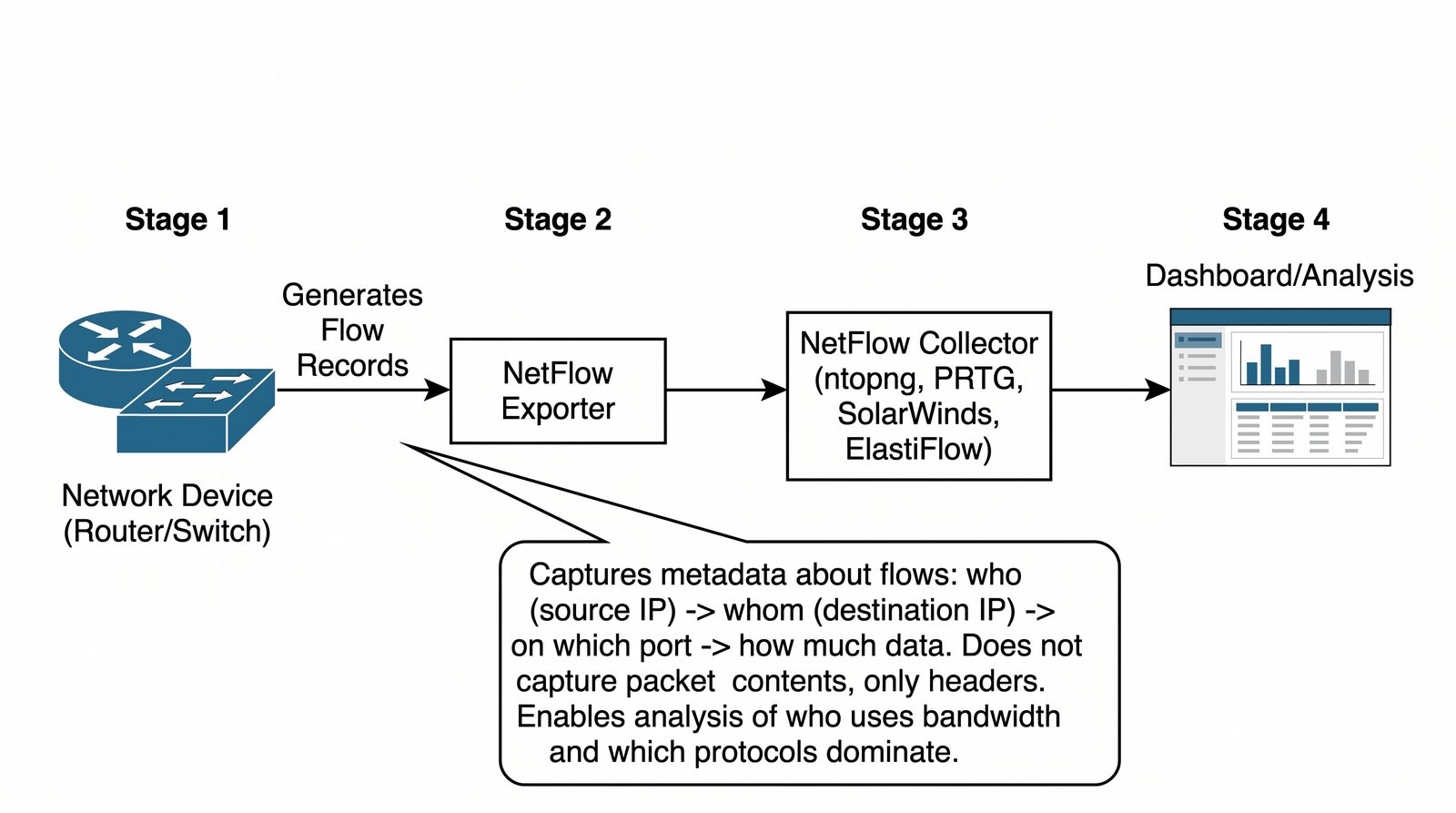
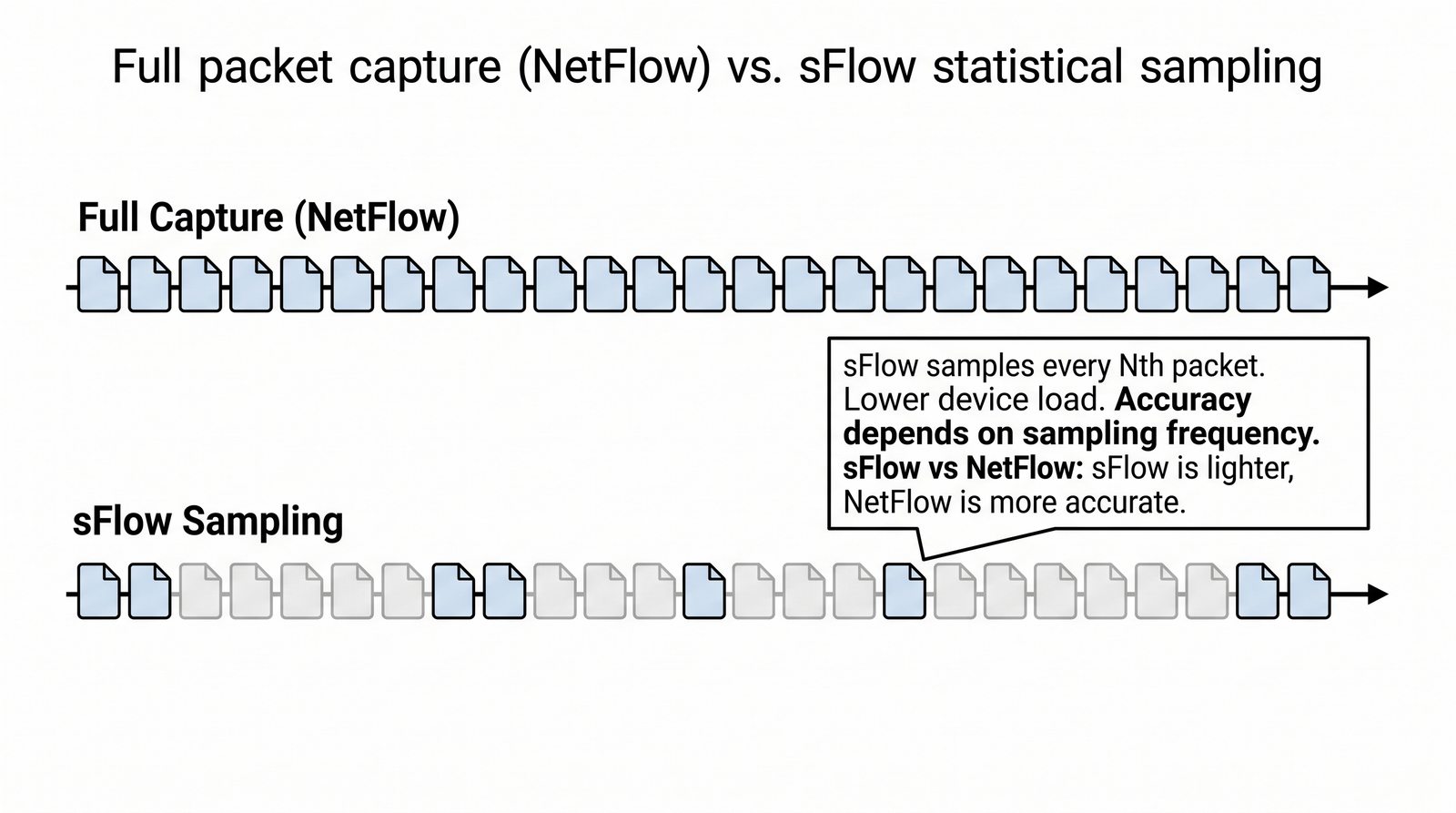
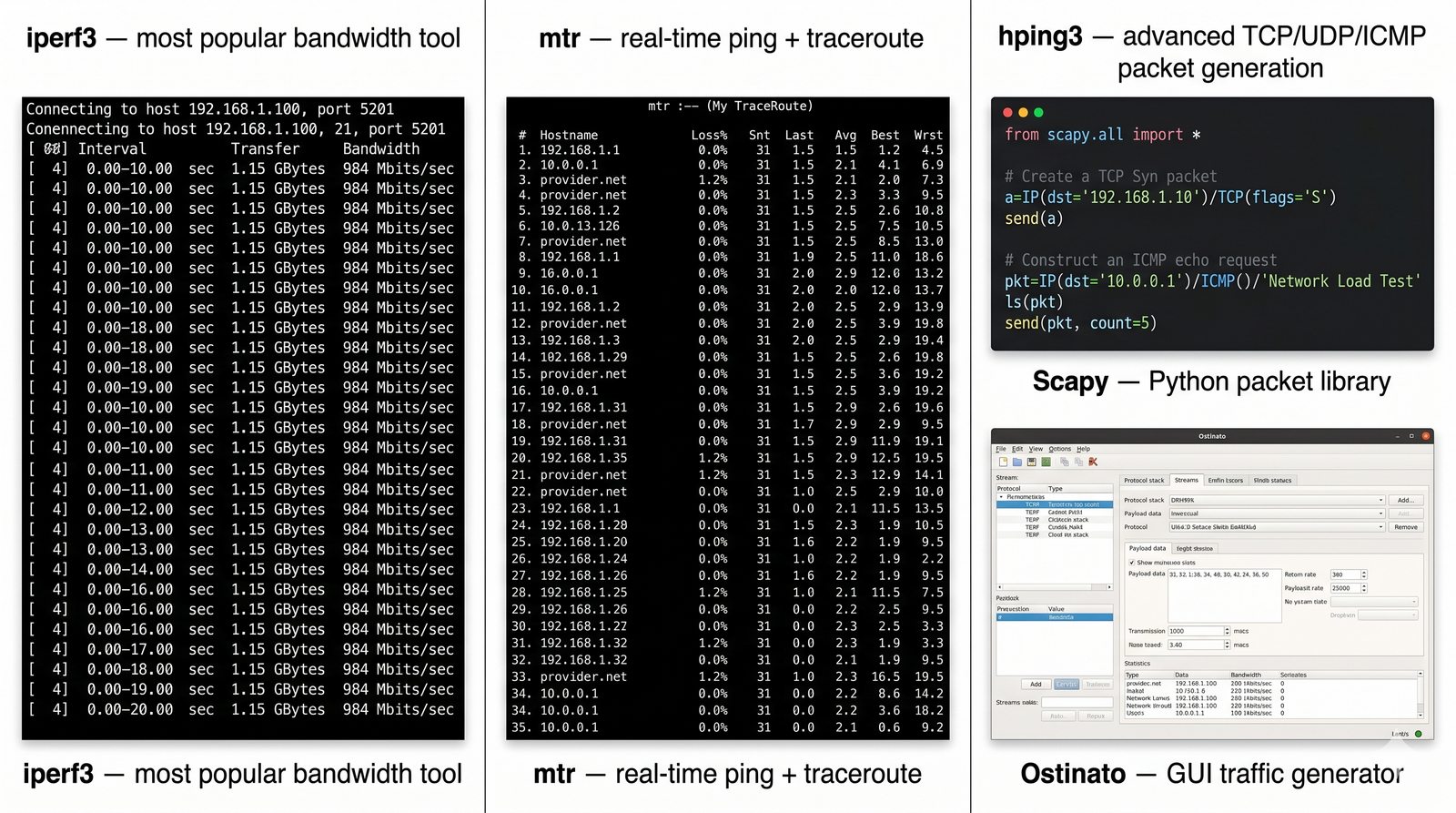
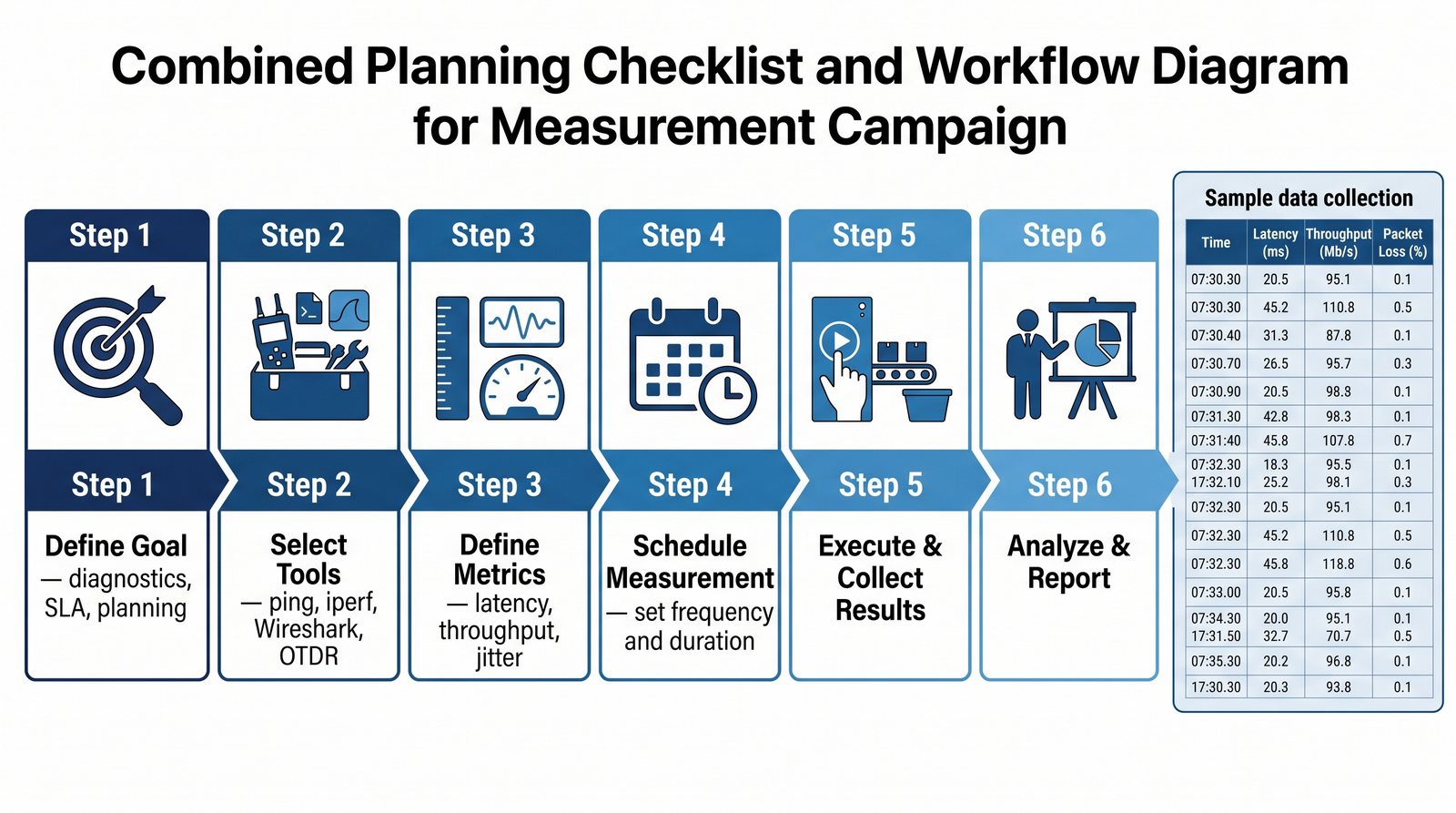
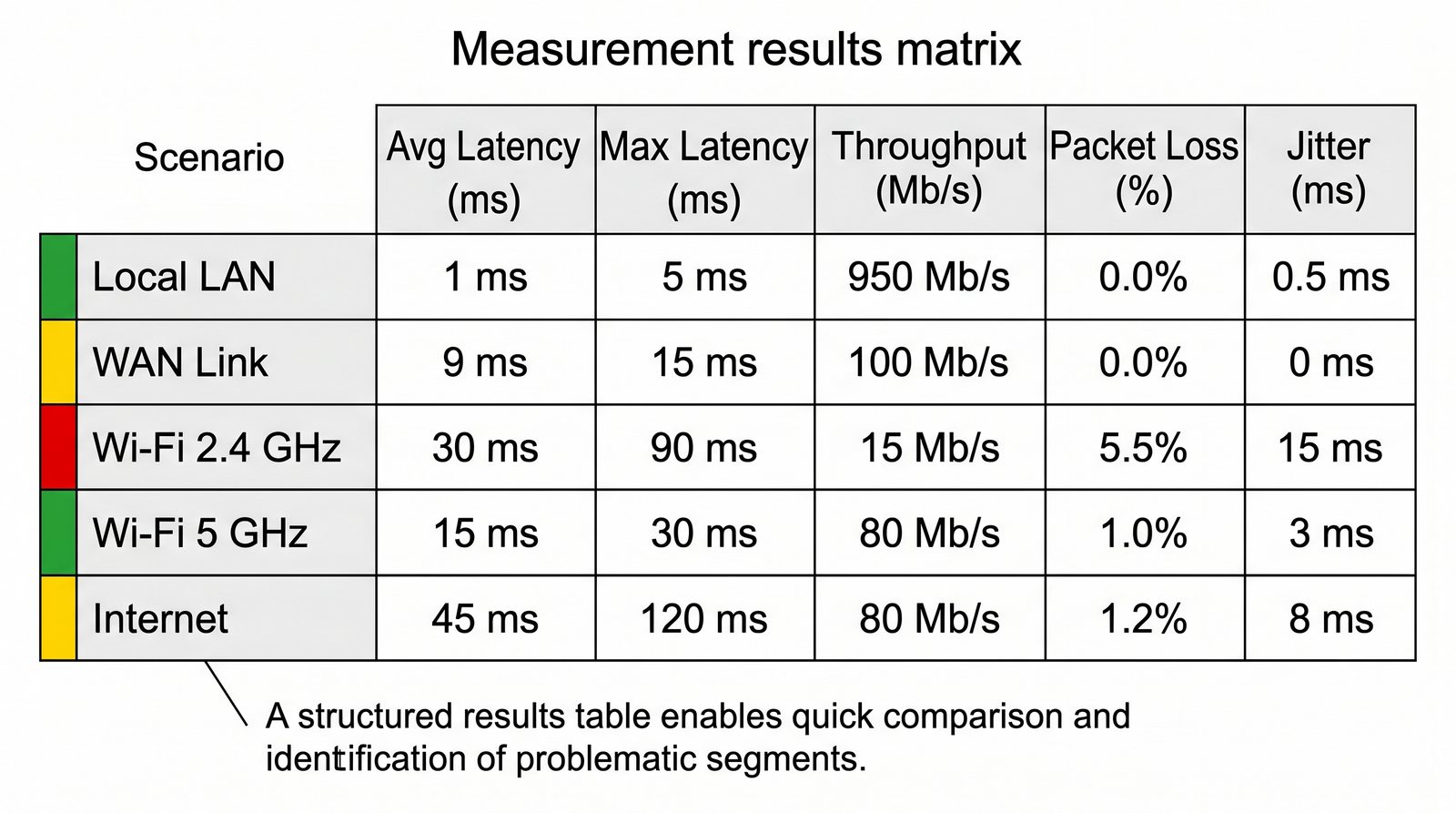
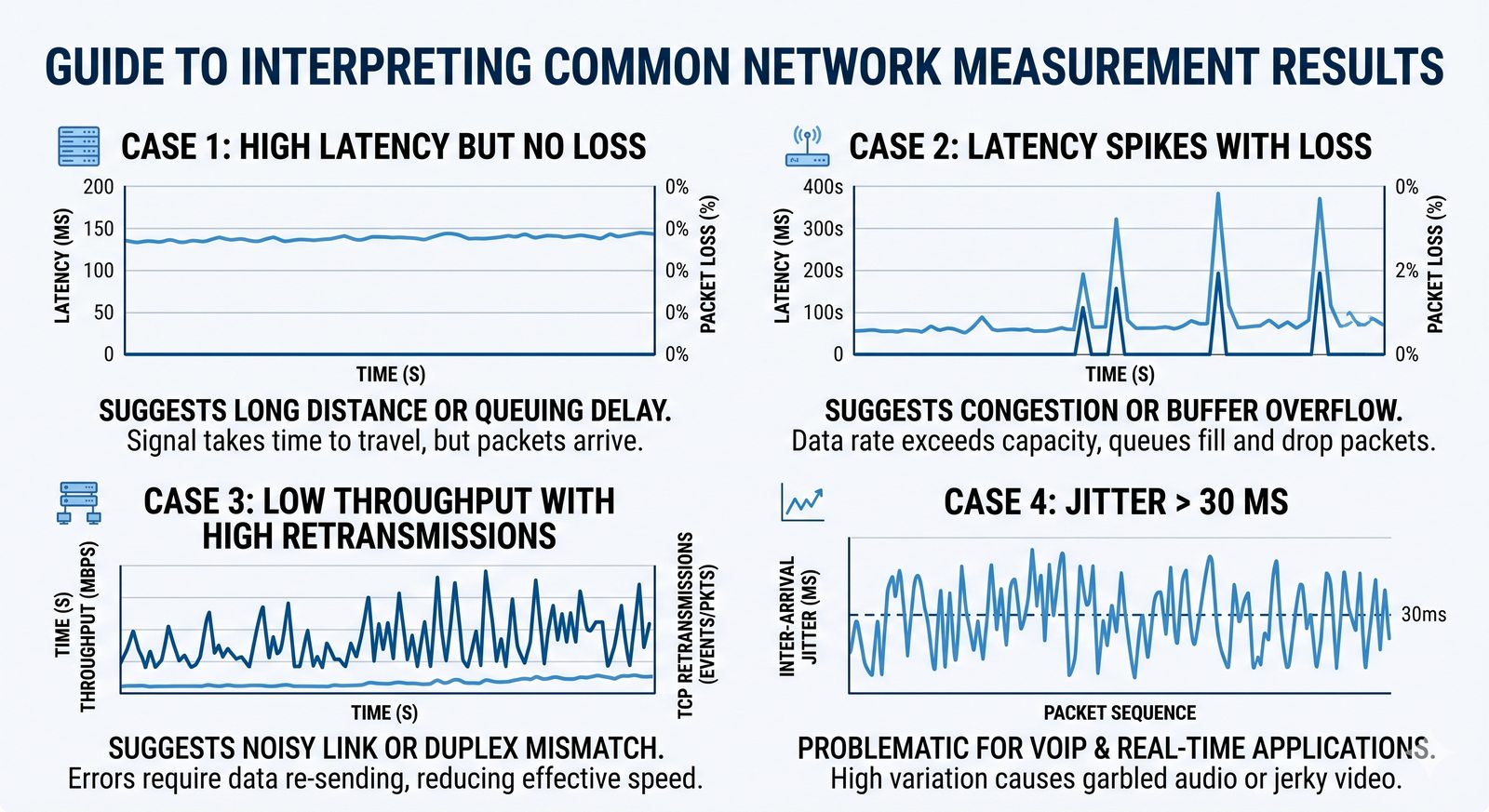
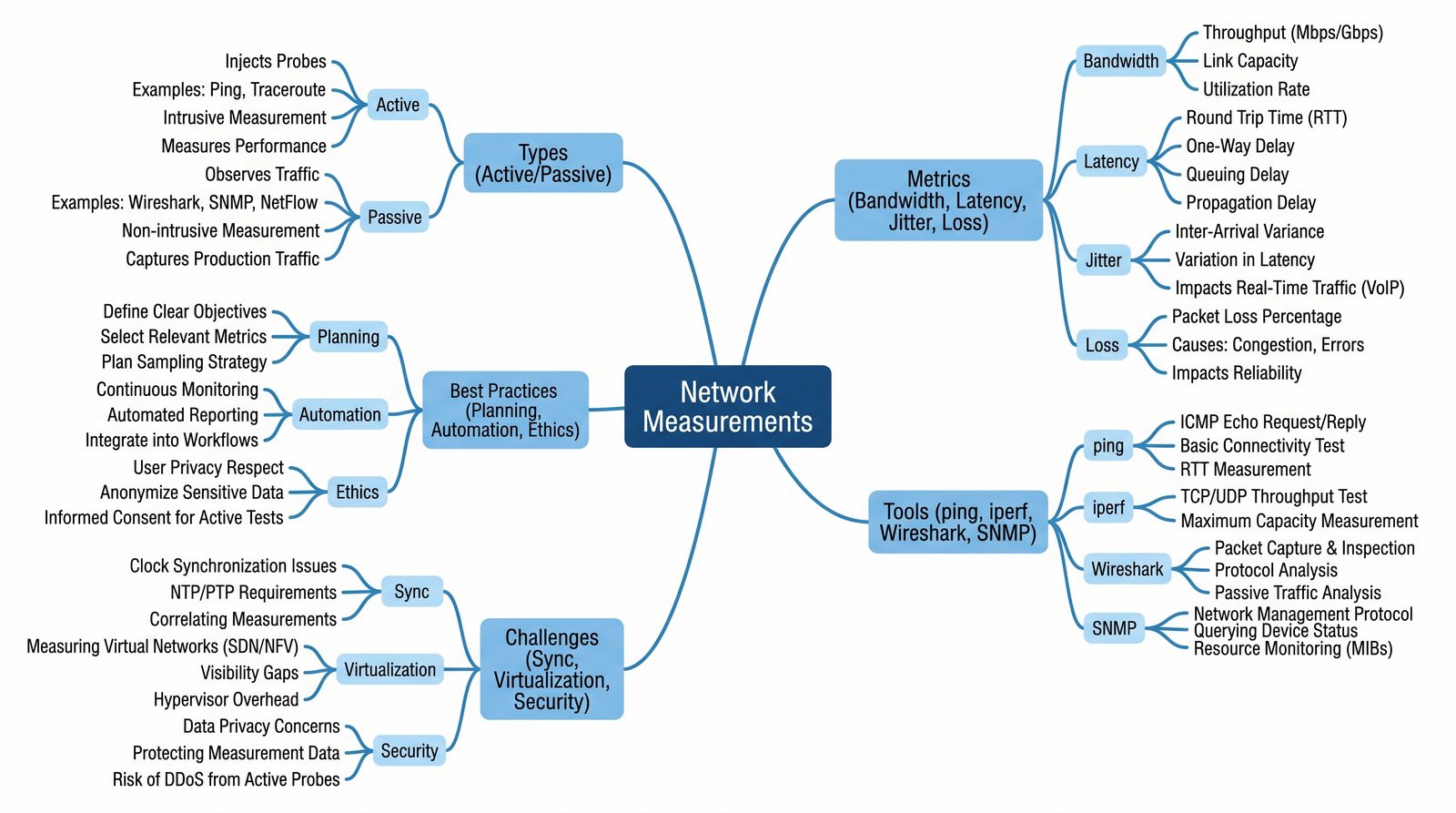
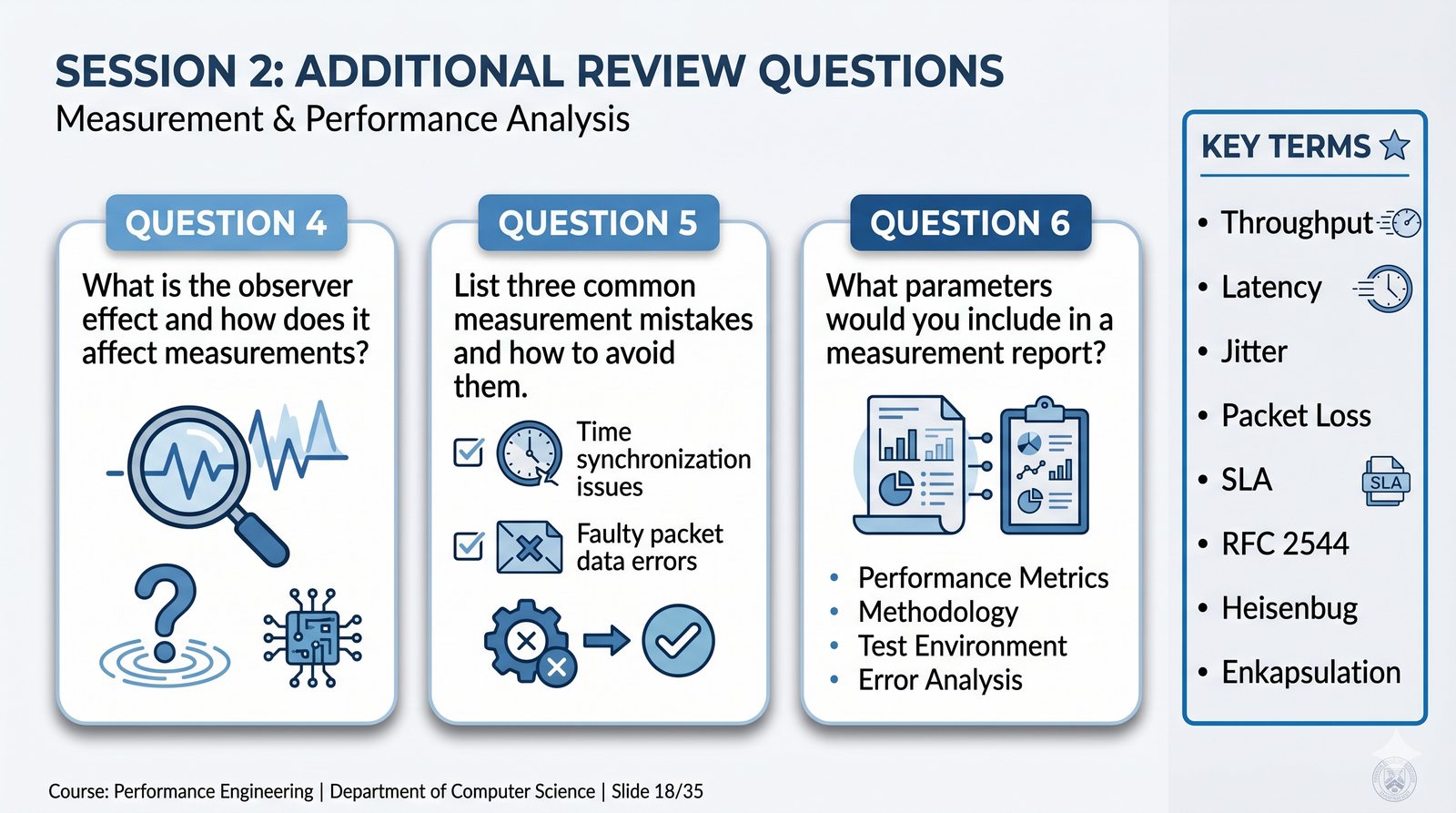
Prezentacja wprowadza w tematykę pomiarów sieciowych, wyjaśniając ich znaczenie dla diagnostyki i utrzymania infrastruktury IT. Omówiono rodzaje pomiarów aktywne i pasywne, kluczowe metryki oraz jednostki pomiarowe stosowane w sieciach LAN, WLAN i WAN. Przedstawiono również wyzwania związane z dokładnością i precyzją pomiarów we współczesnych środowiskach sieciowych.