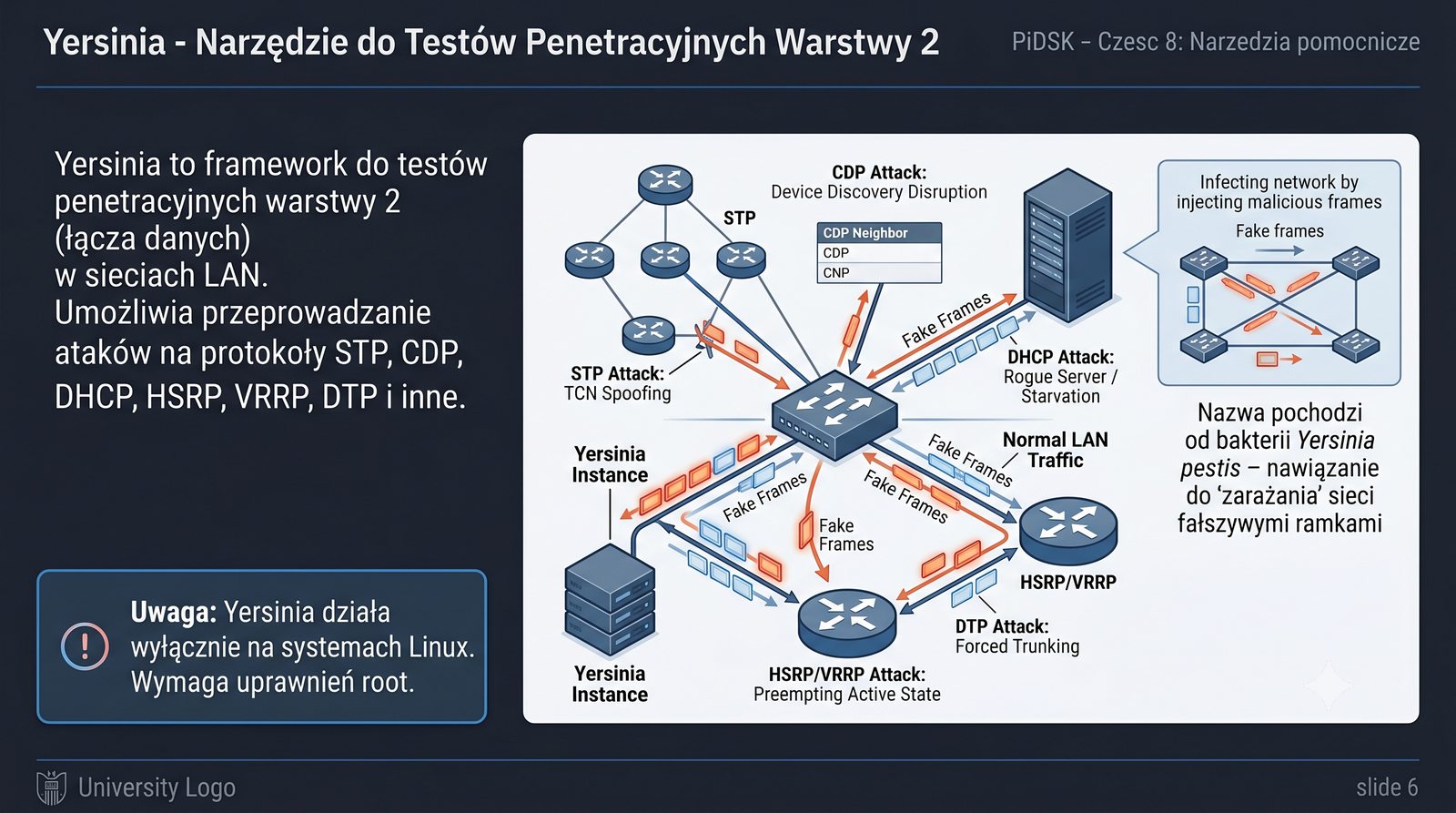
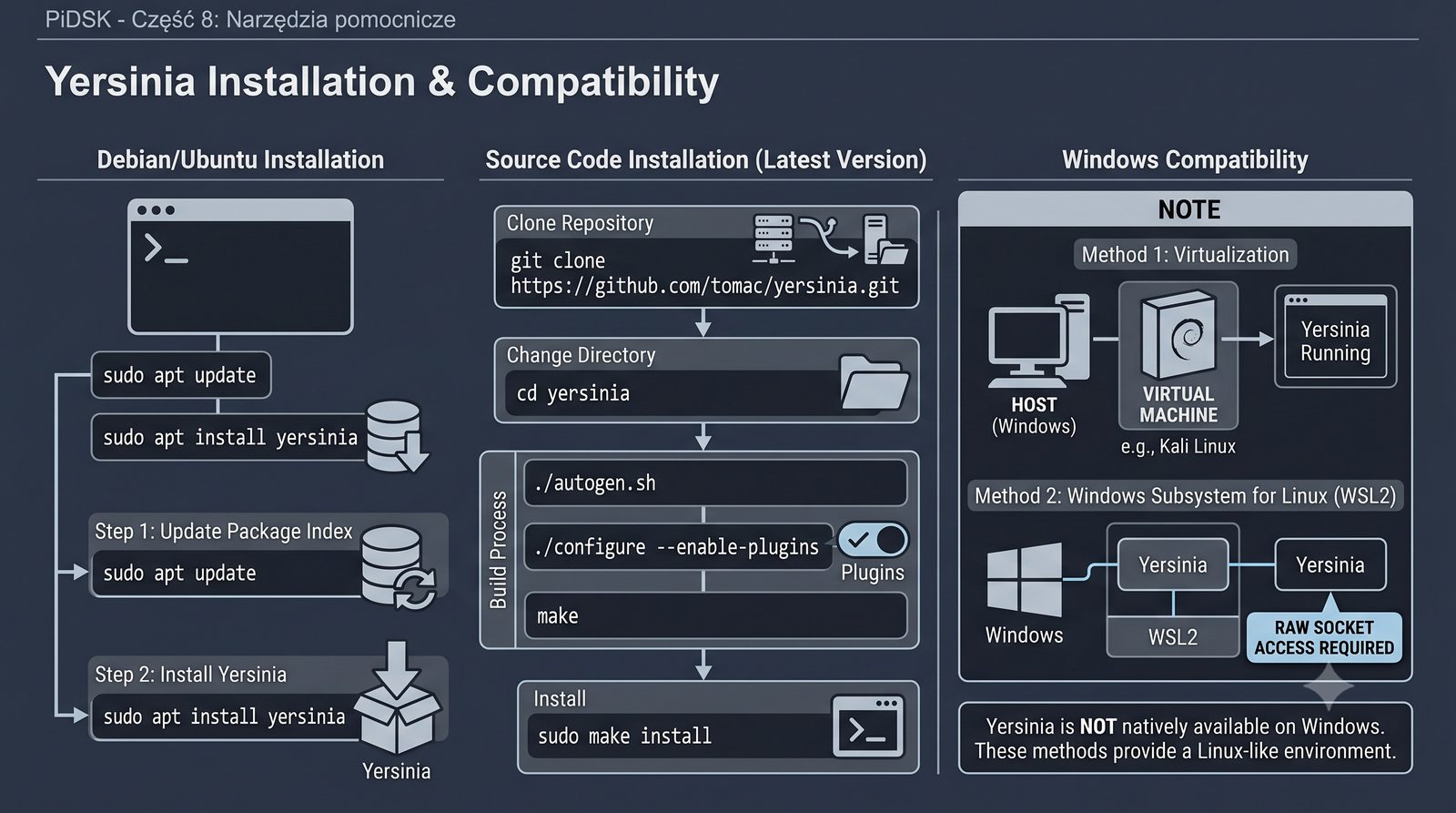
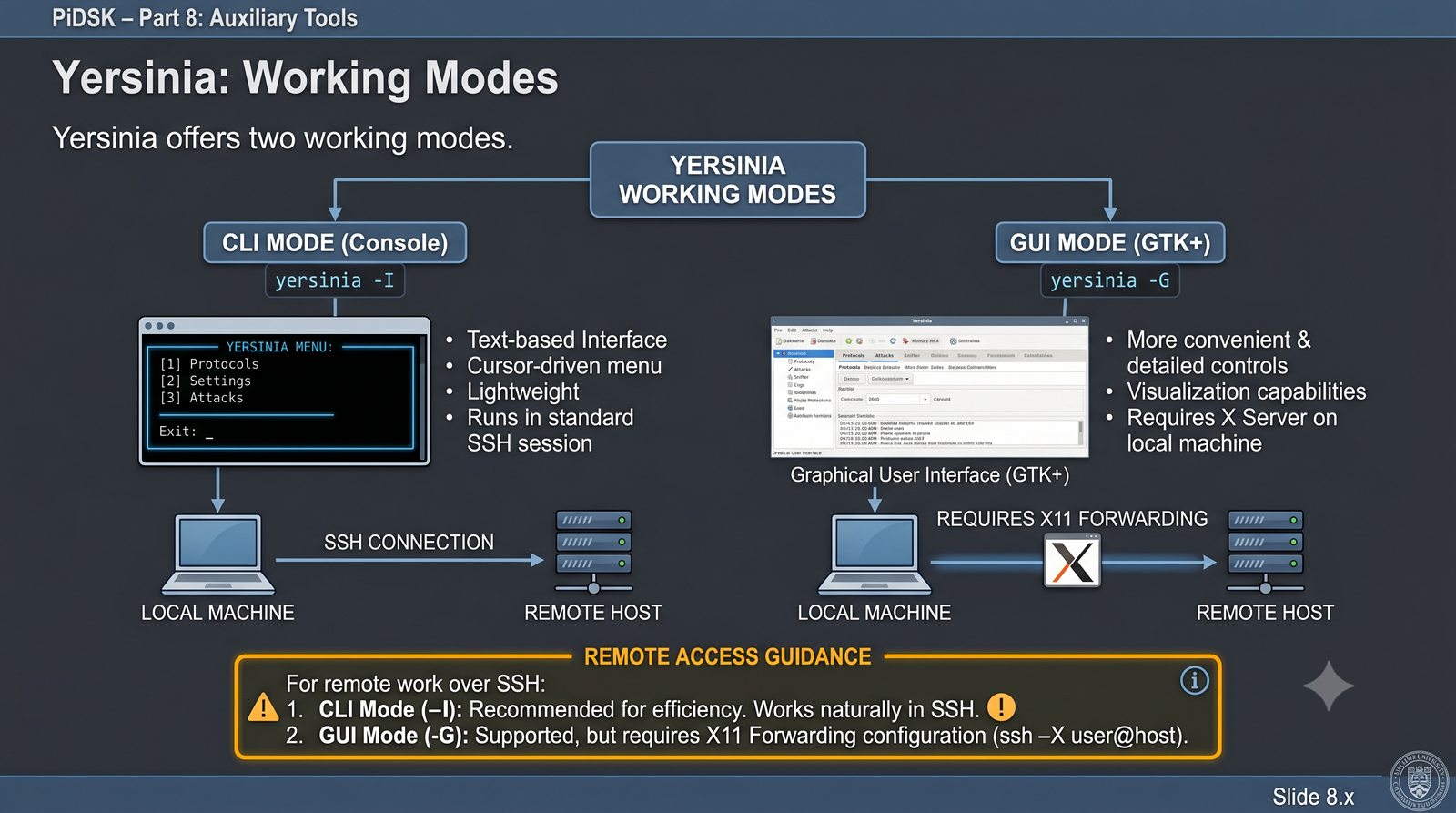
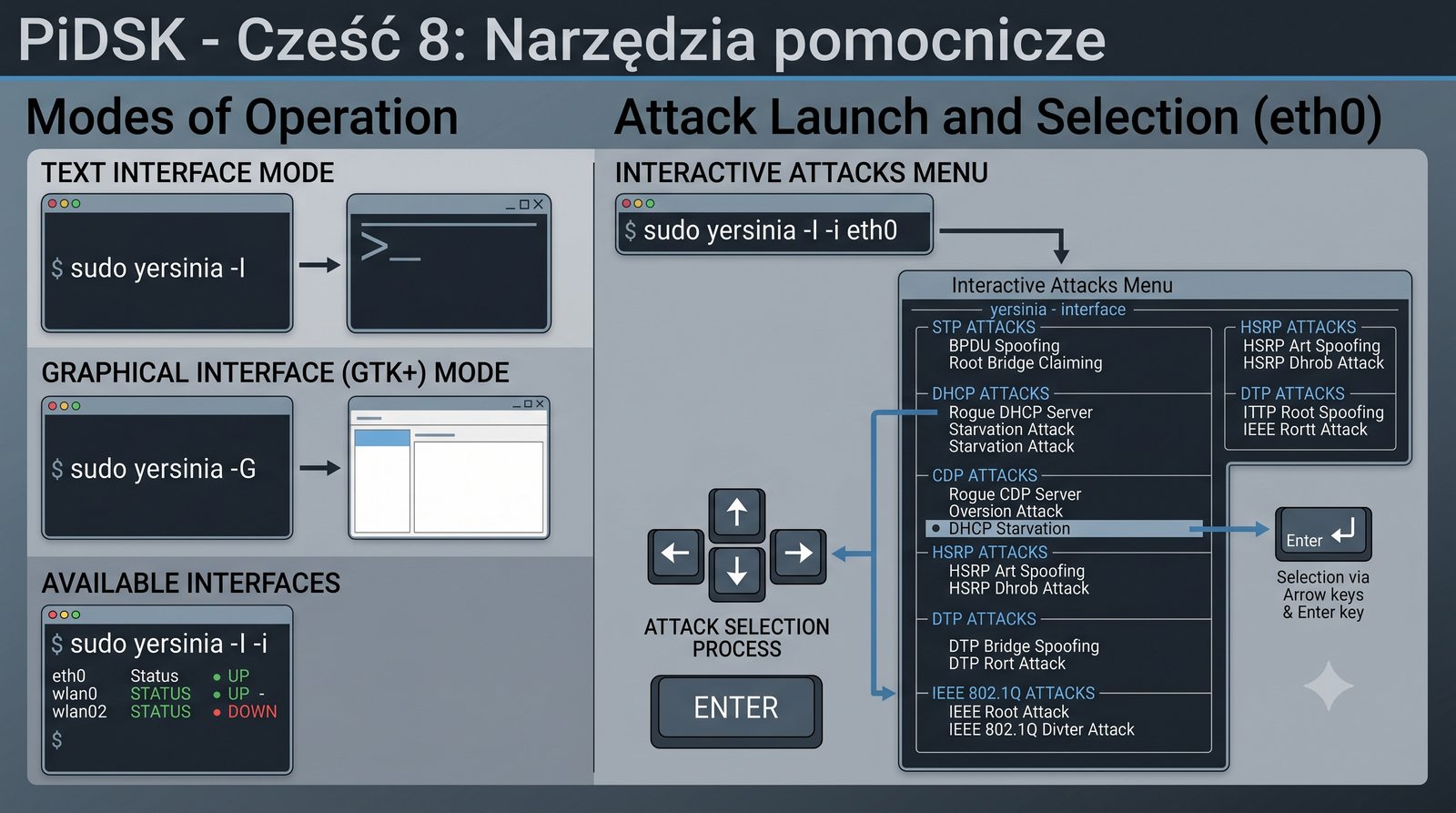
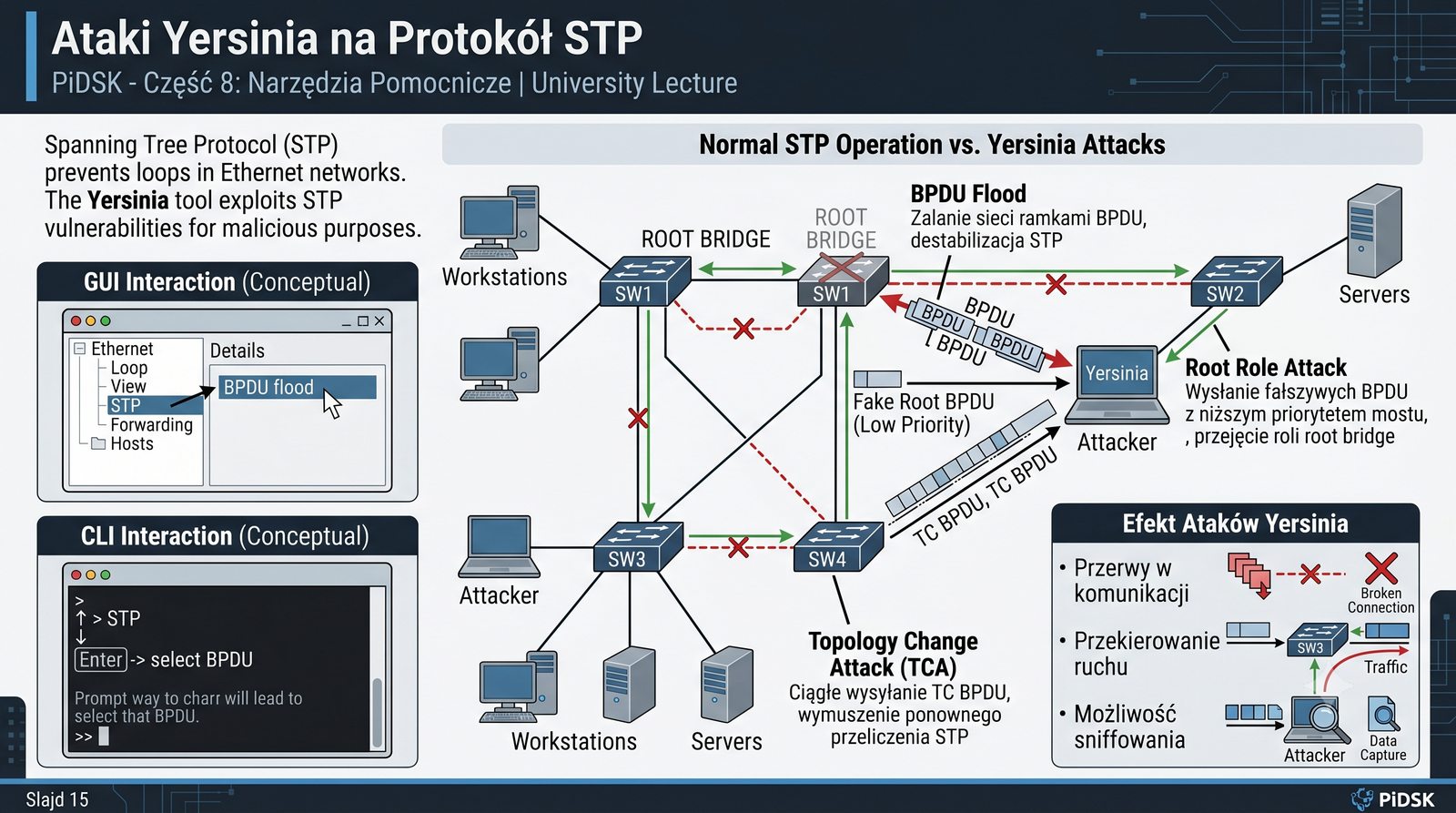
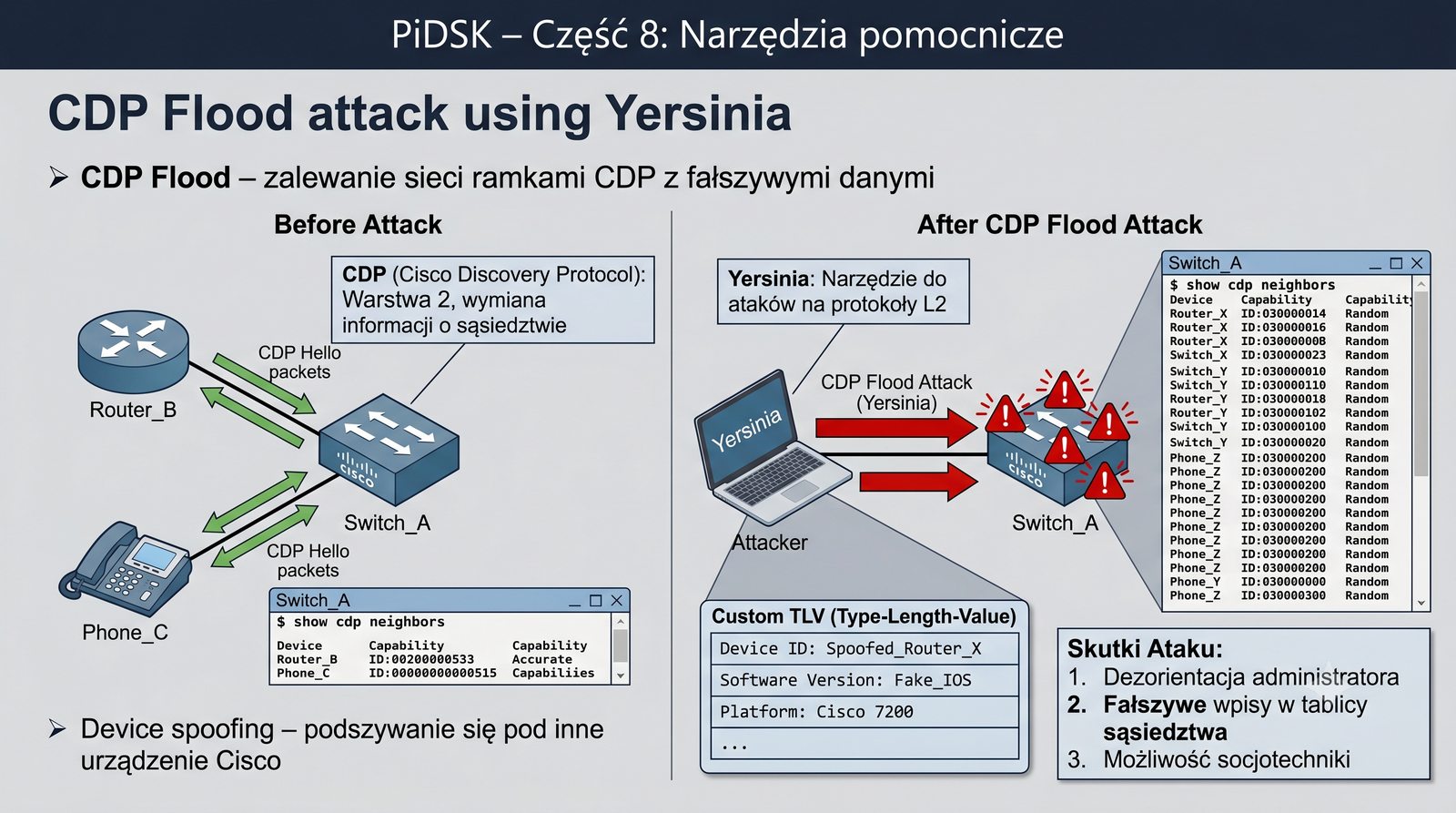
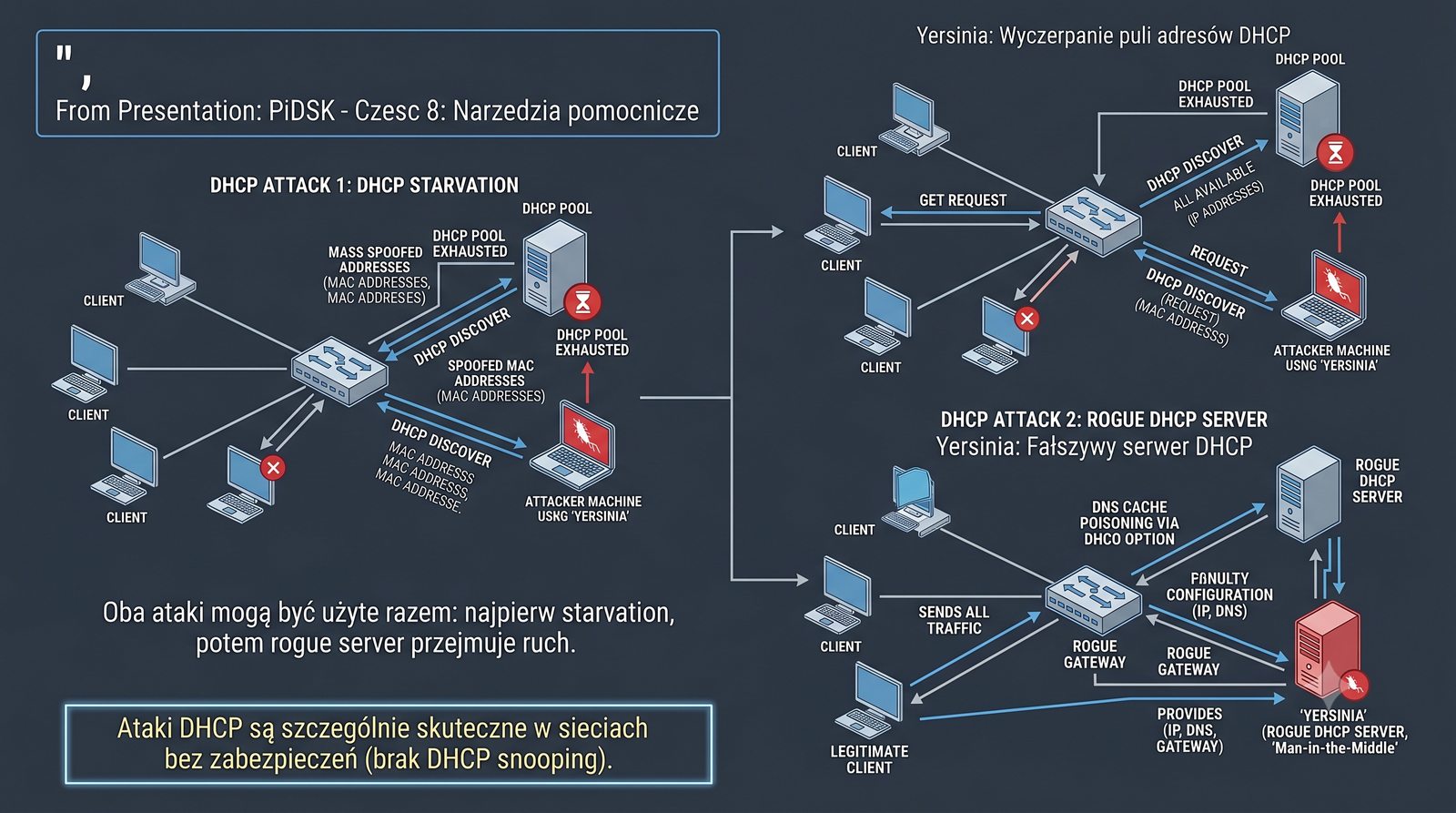
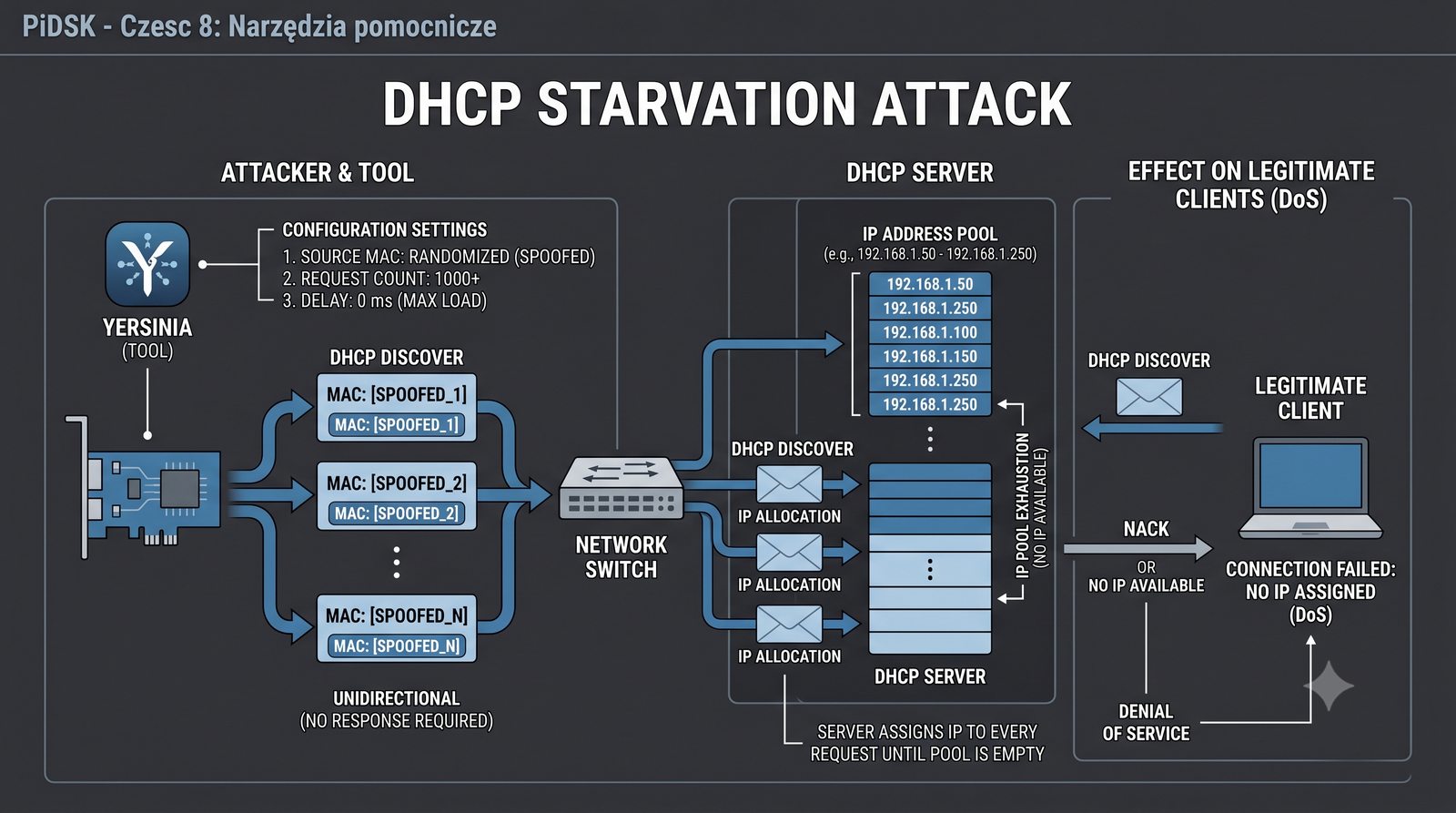
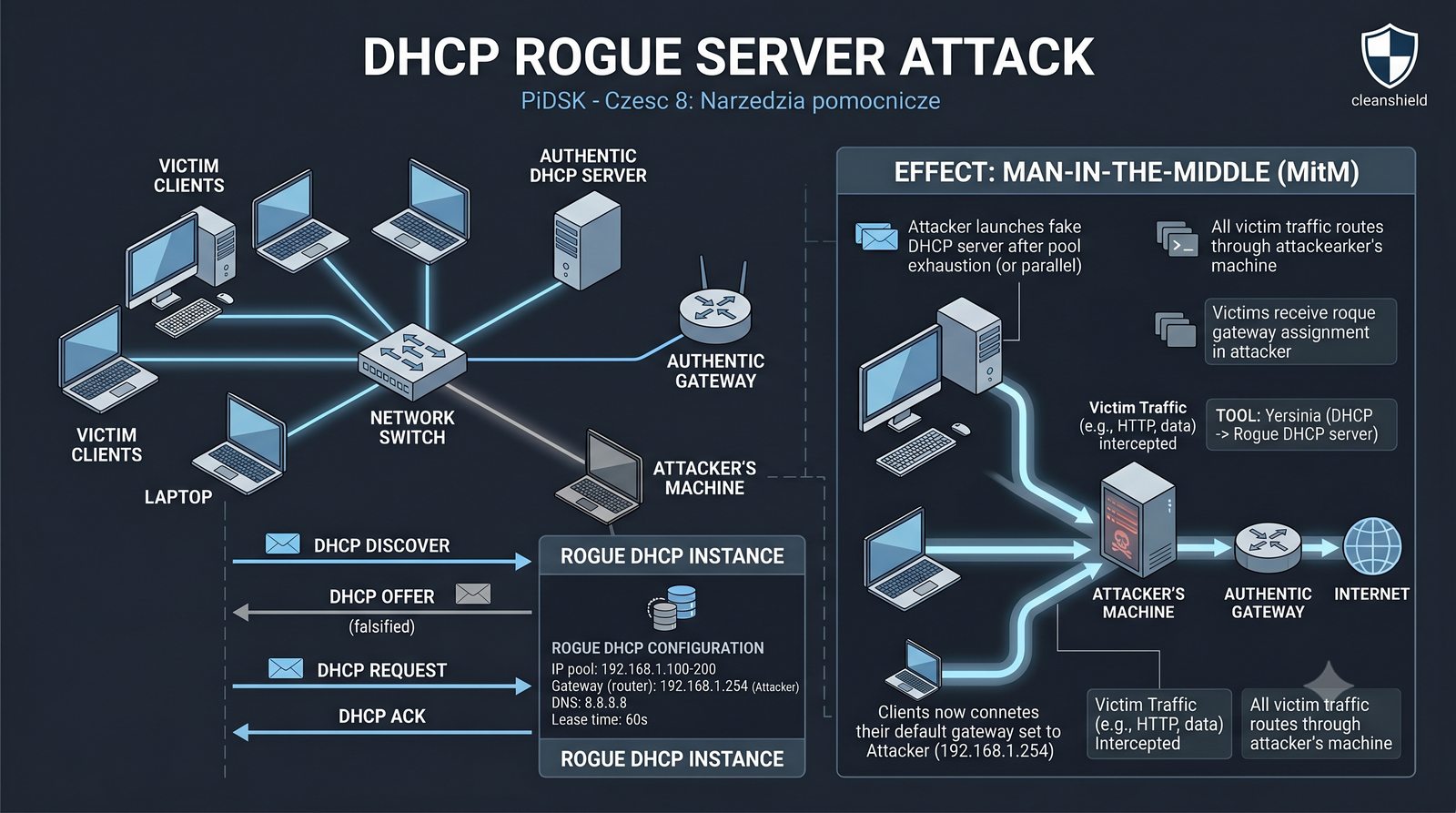
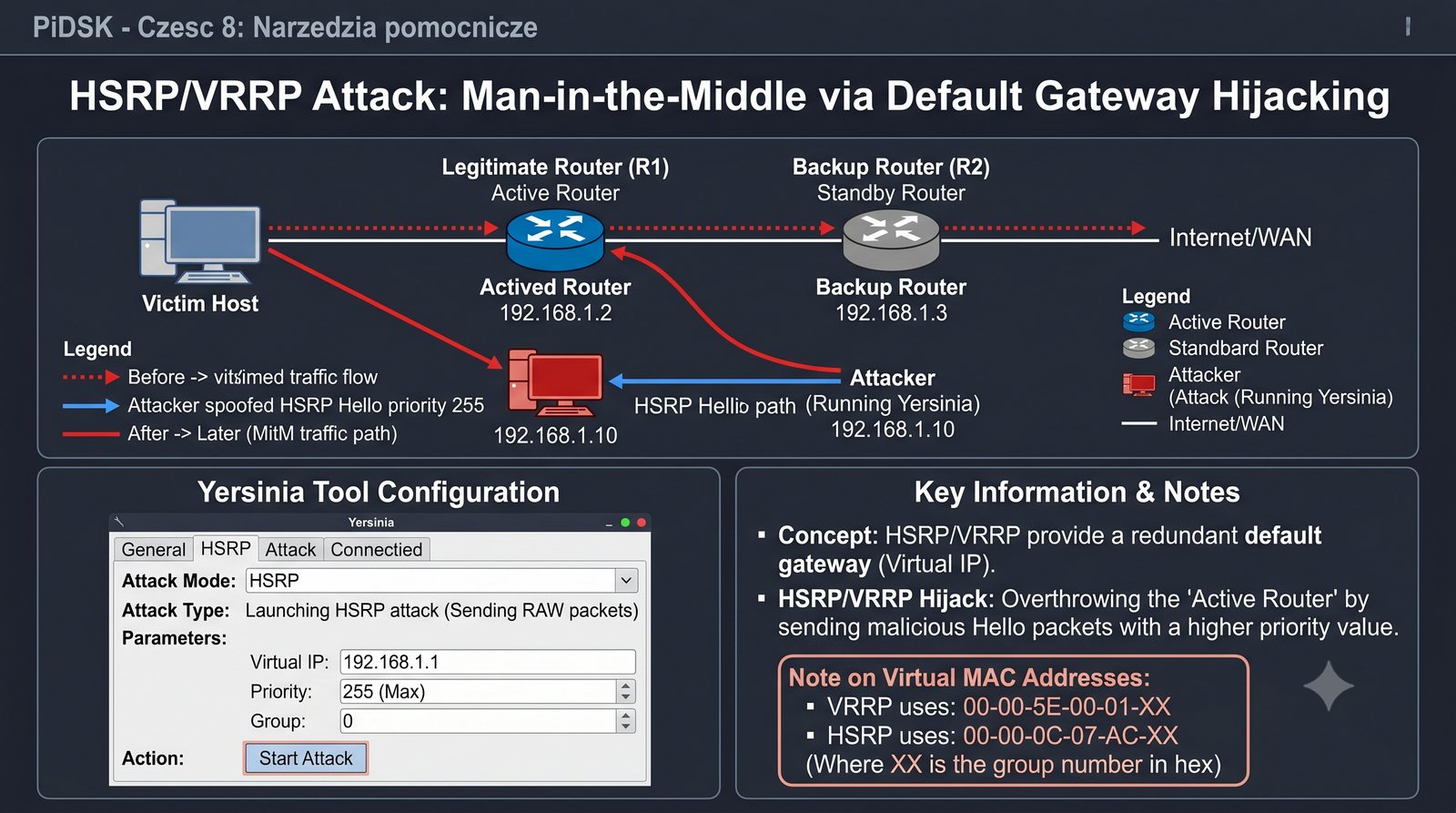
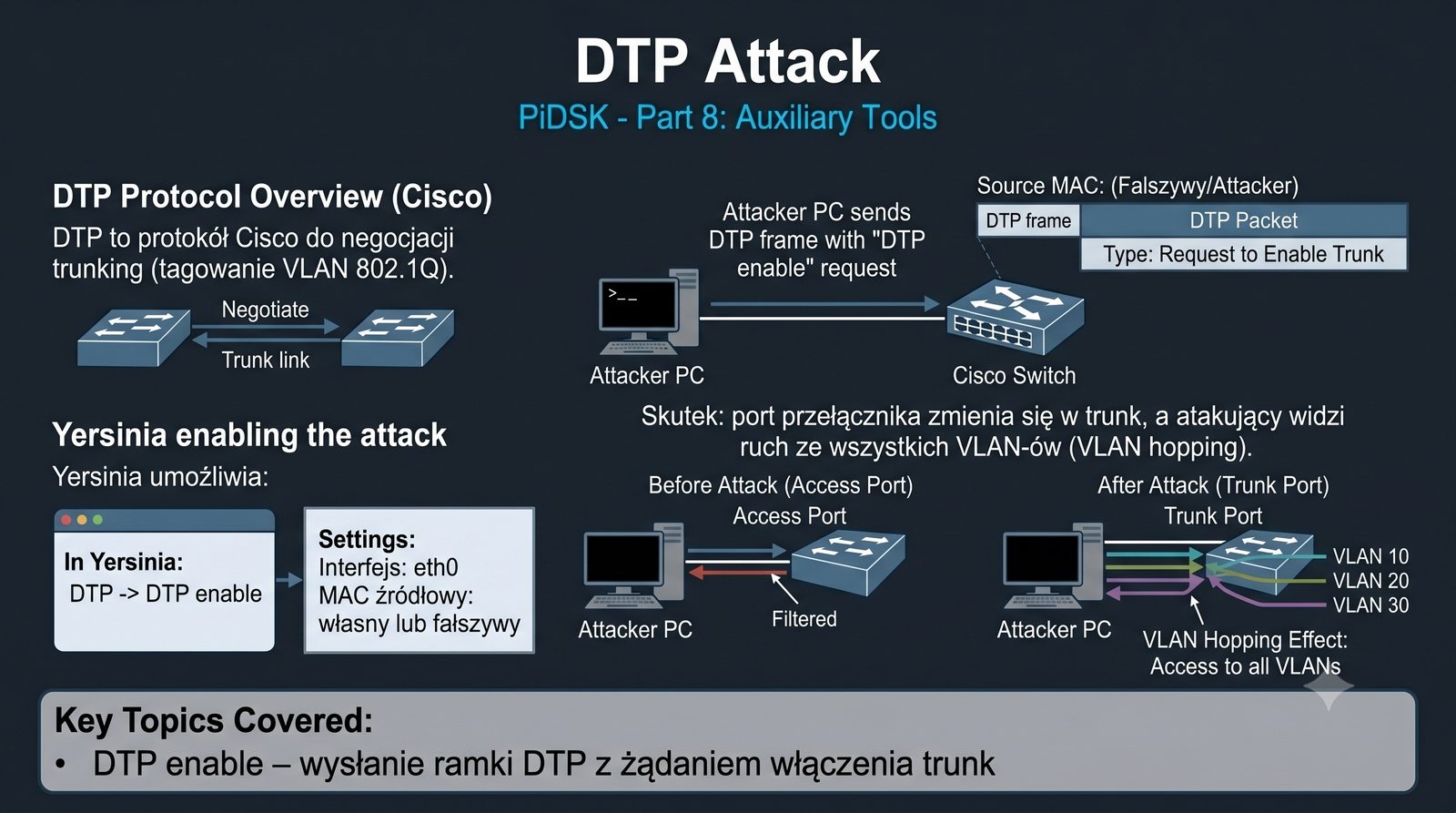
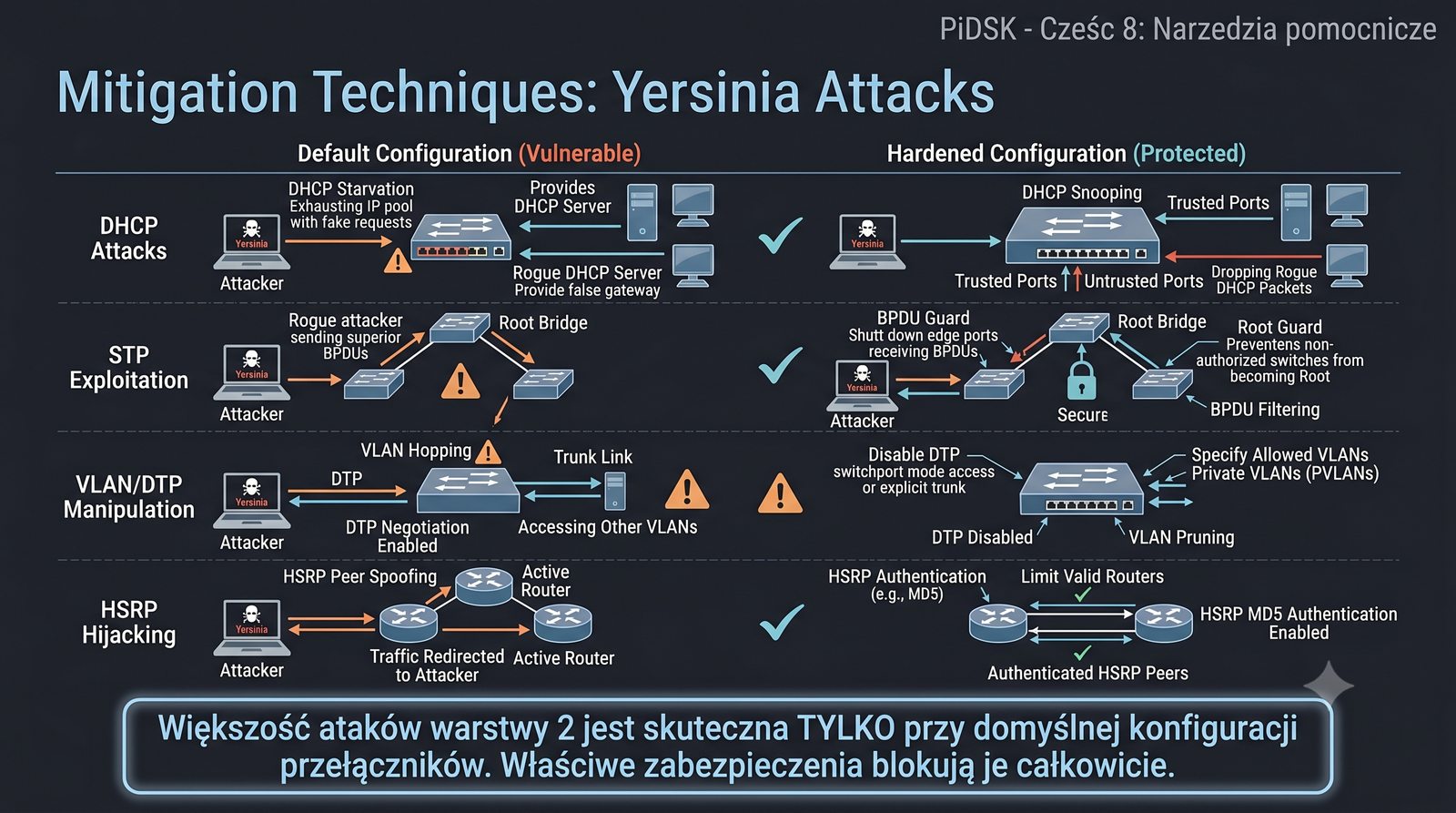
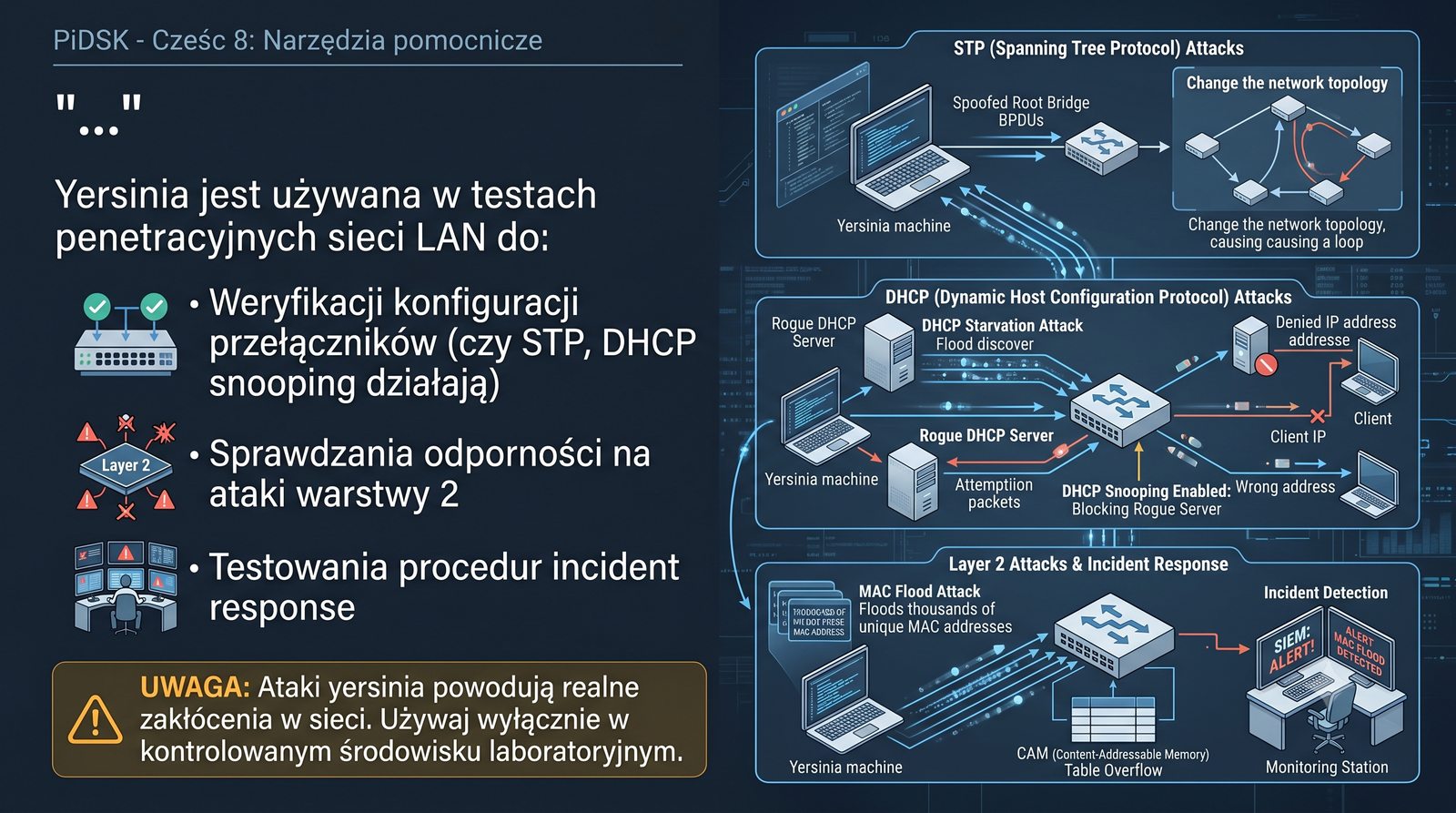
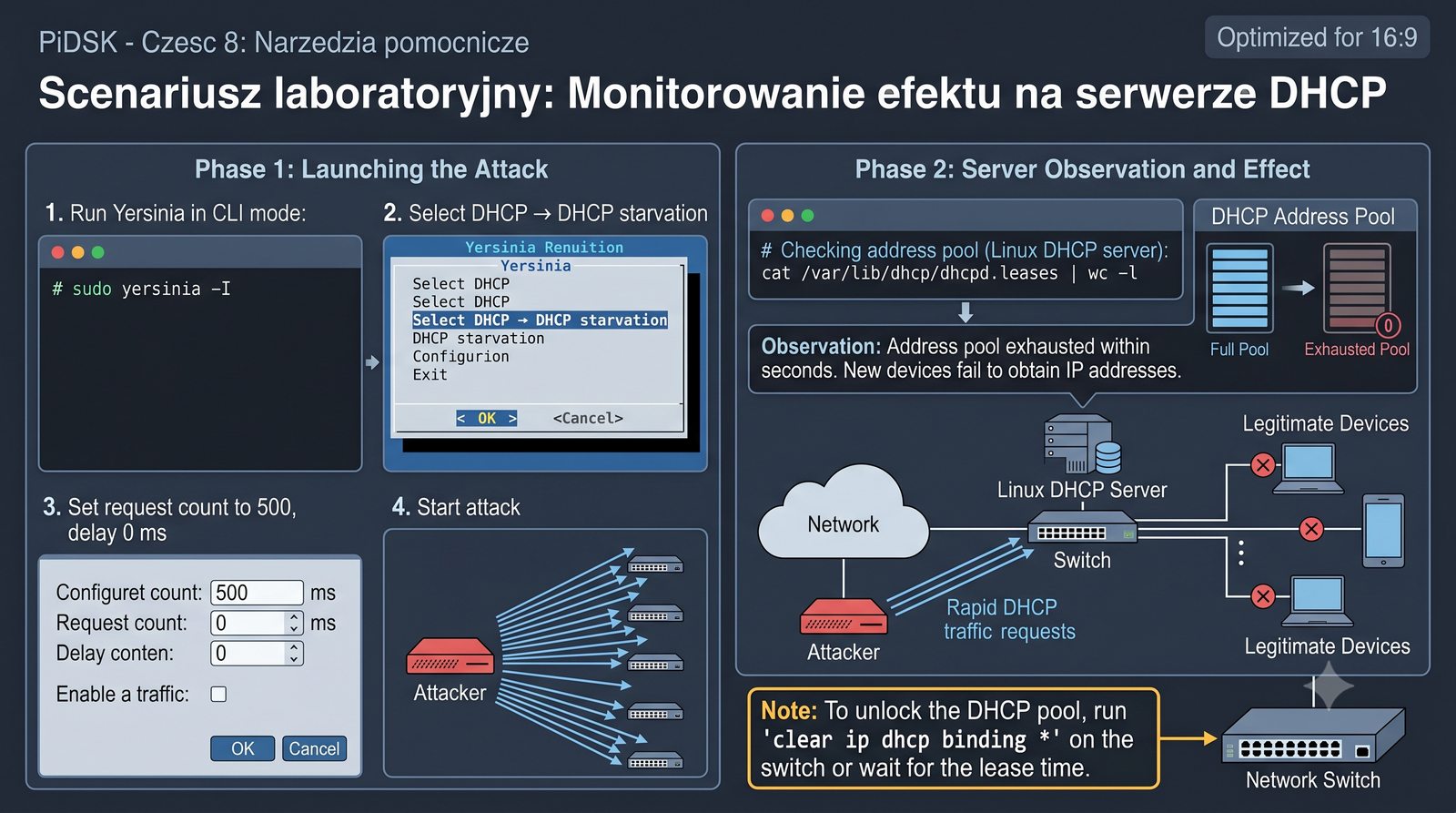
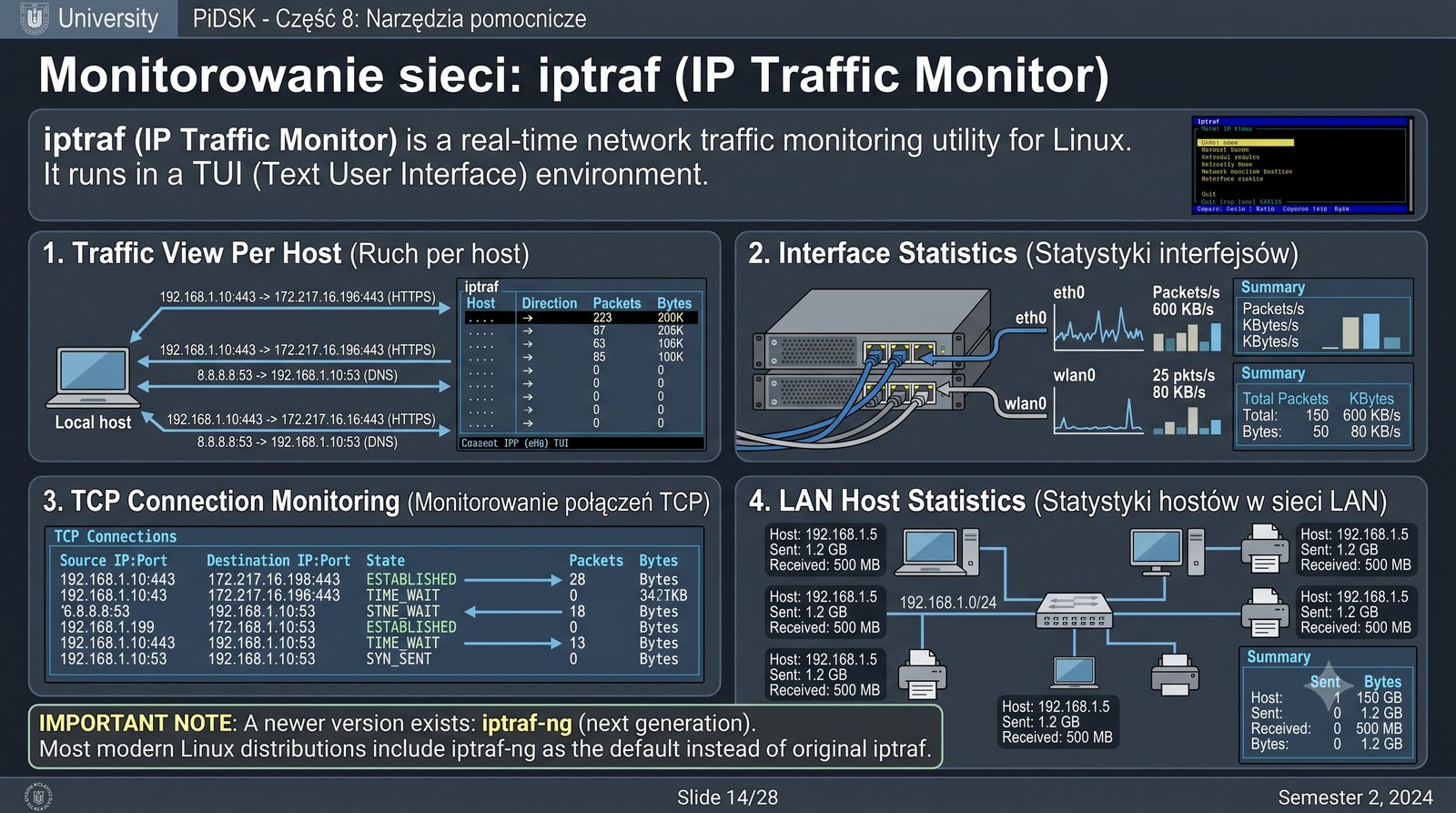
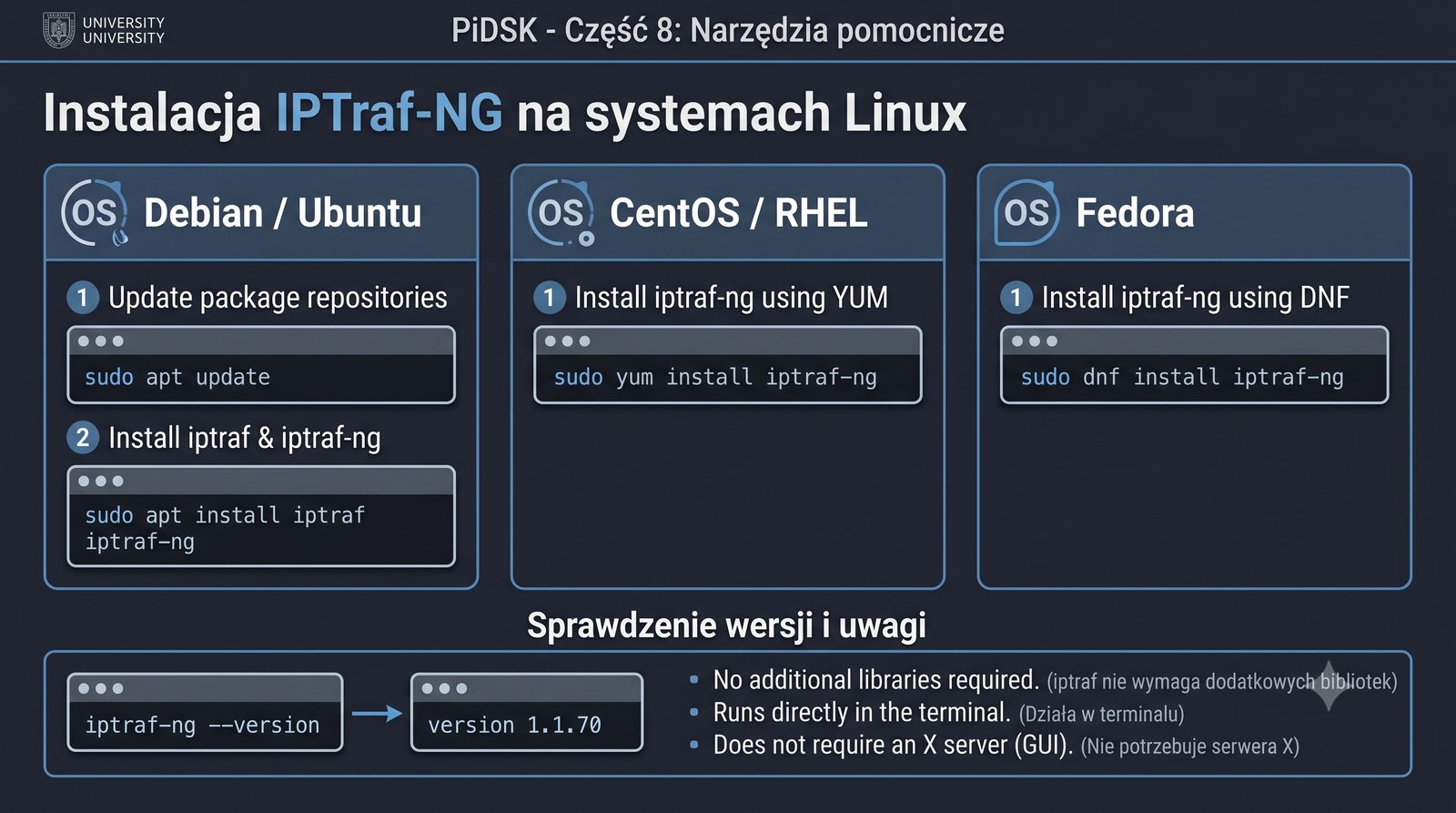
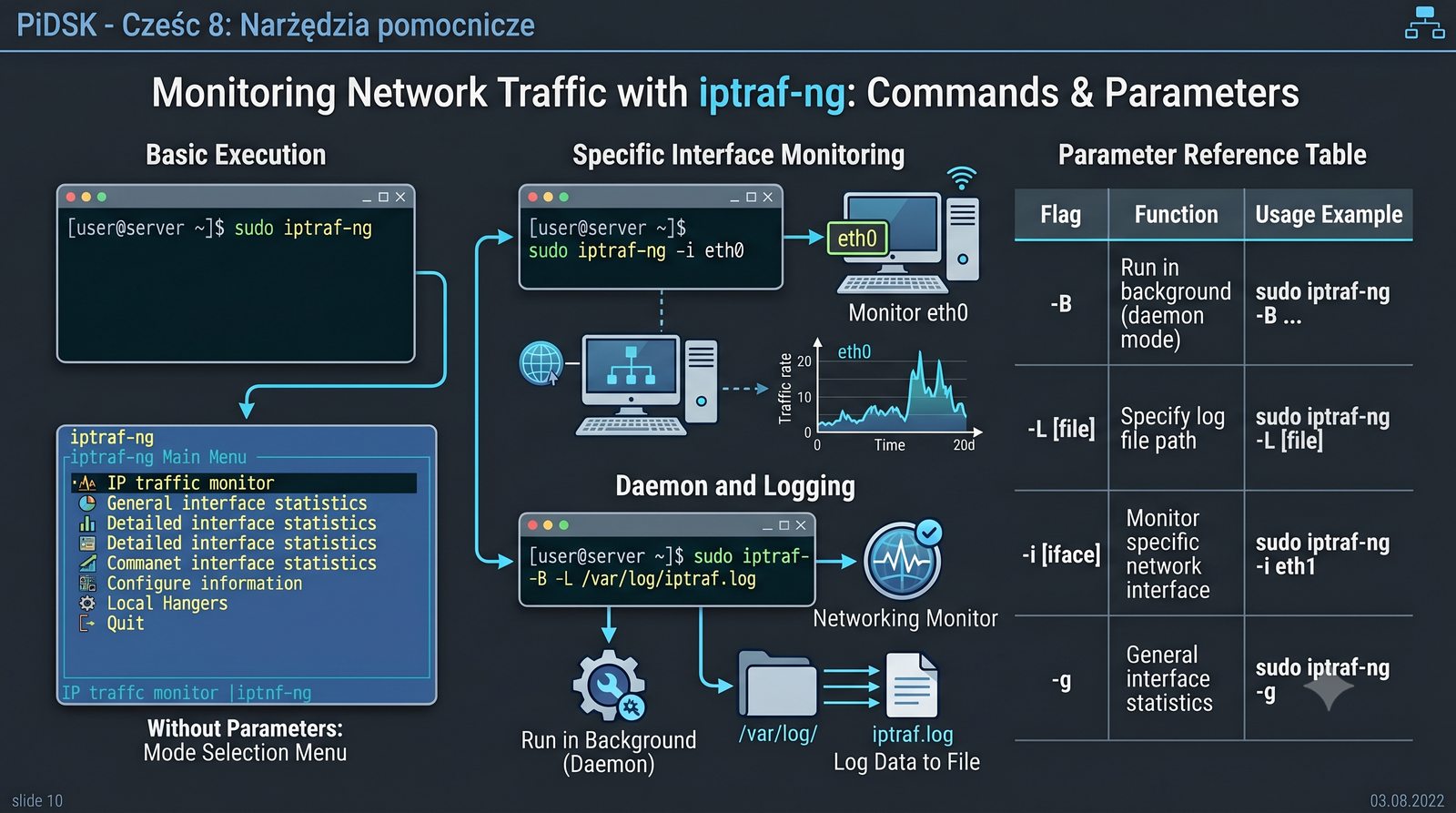
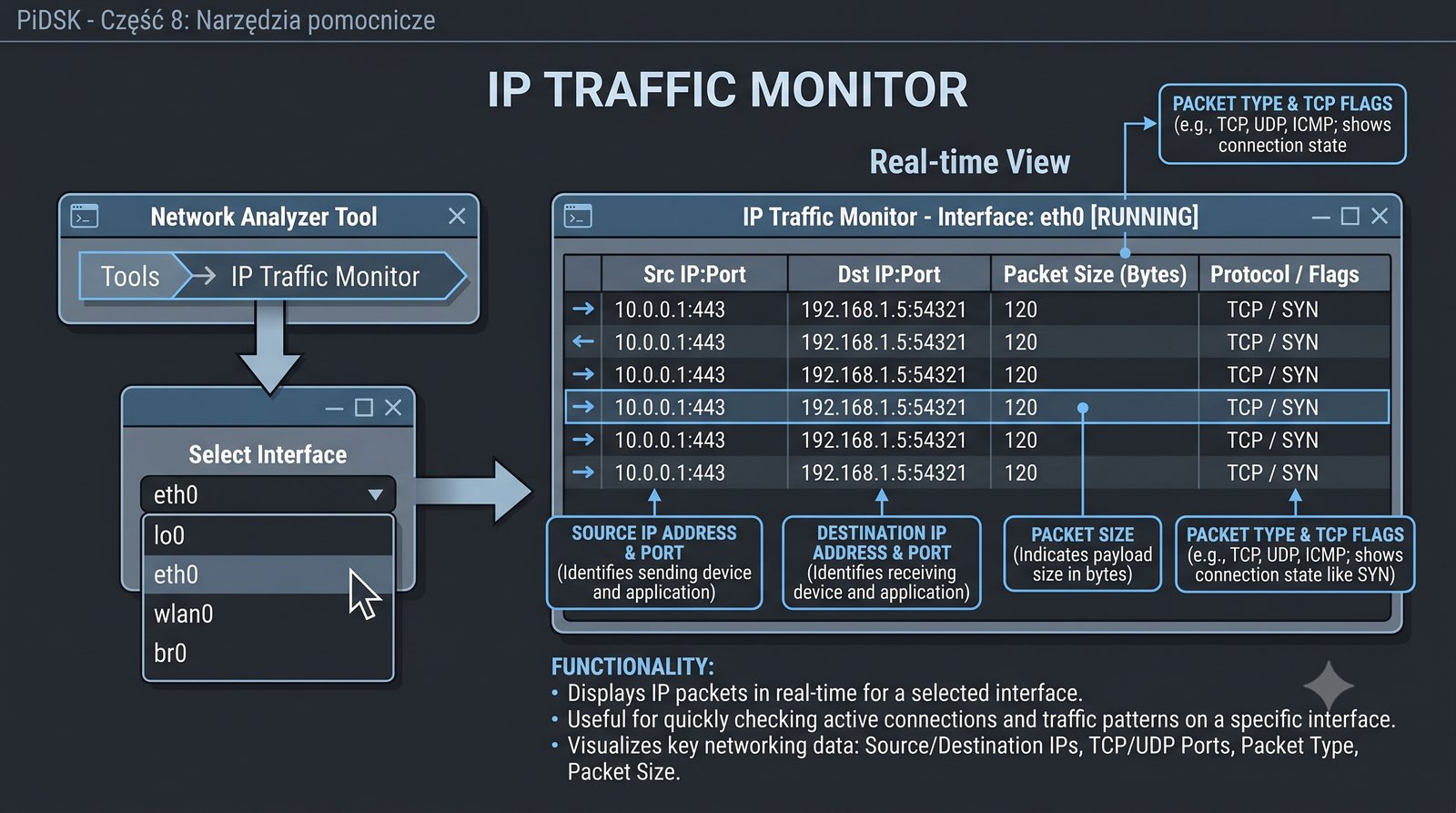
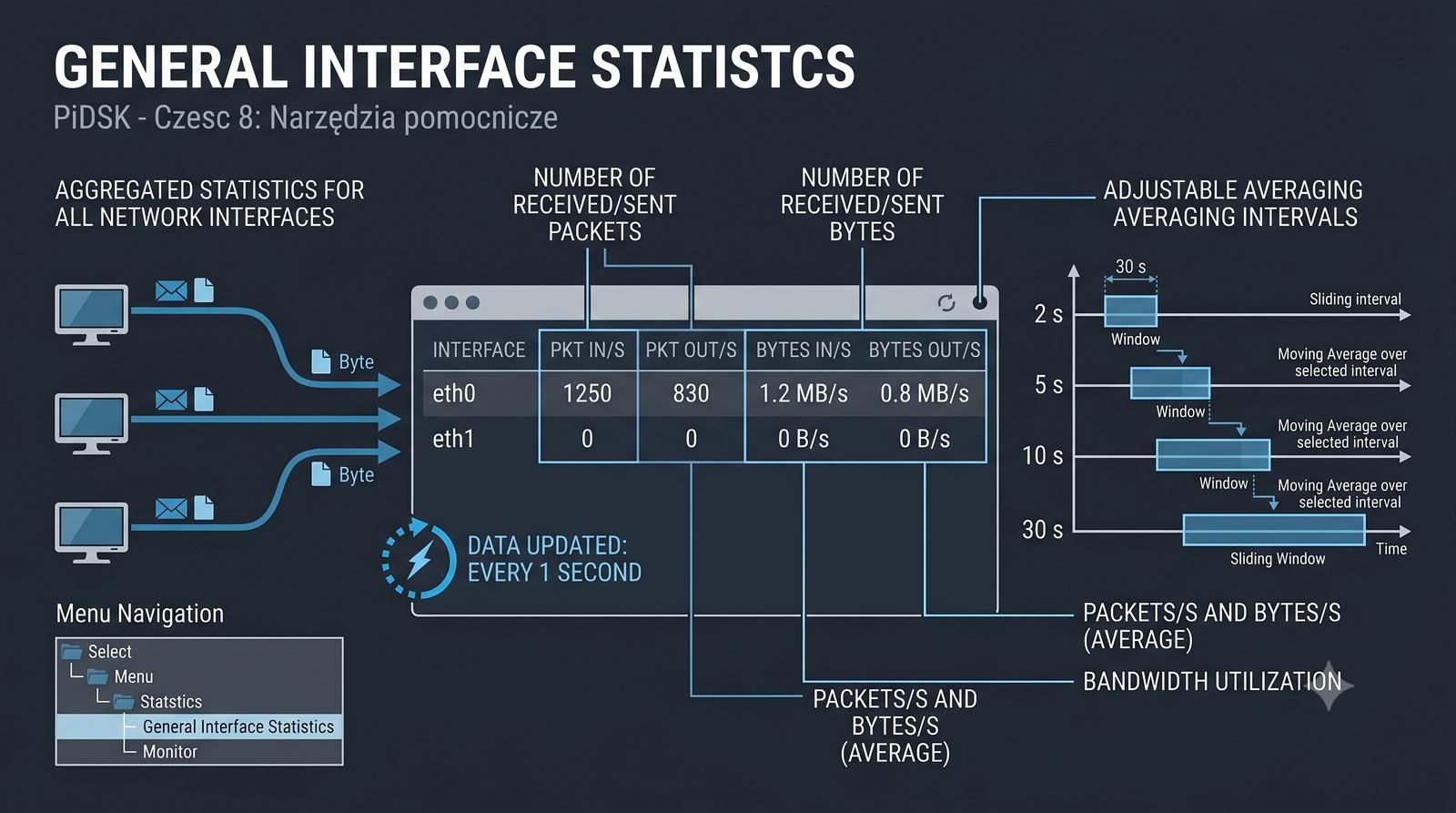
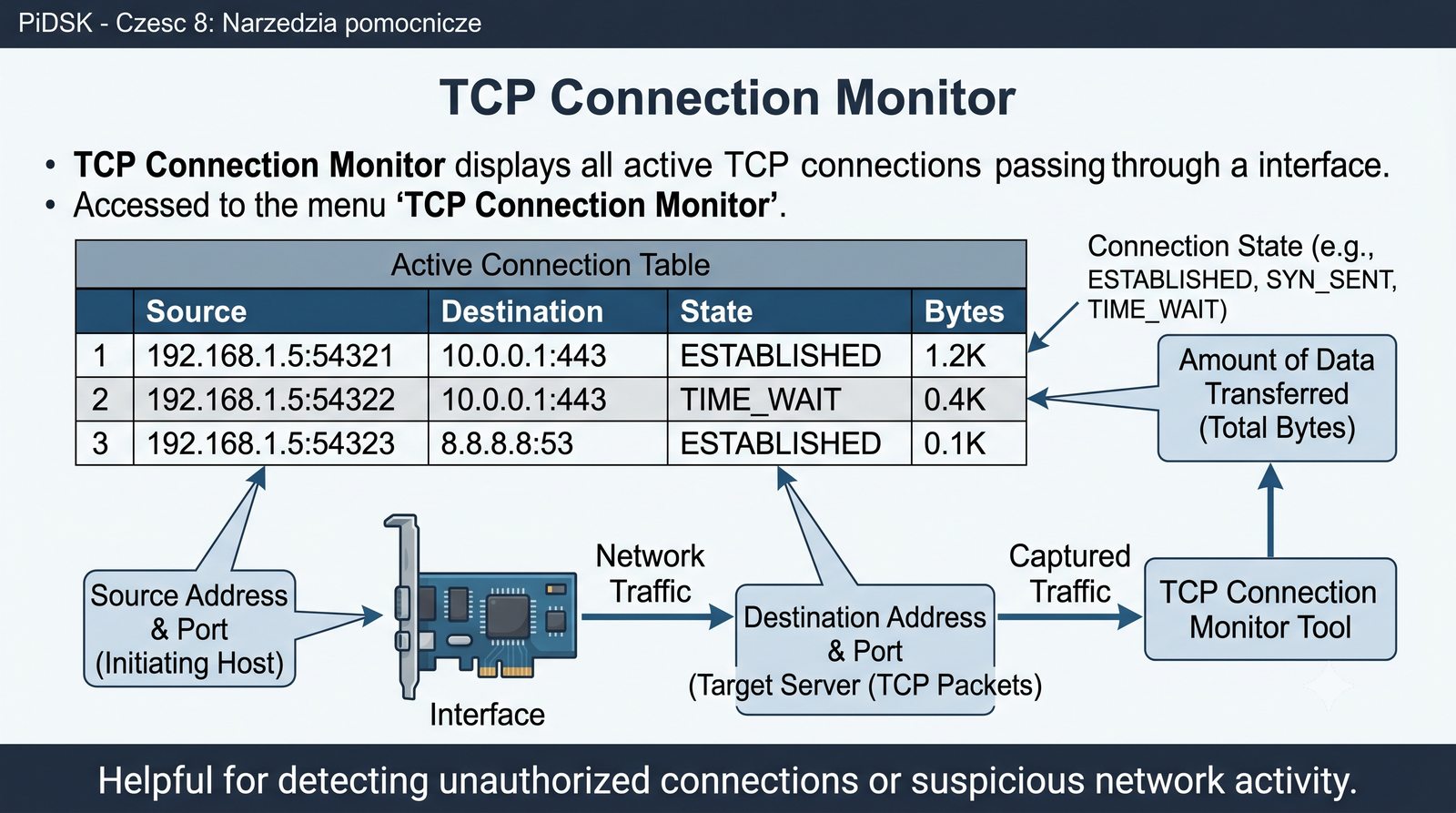
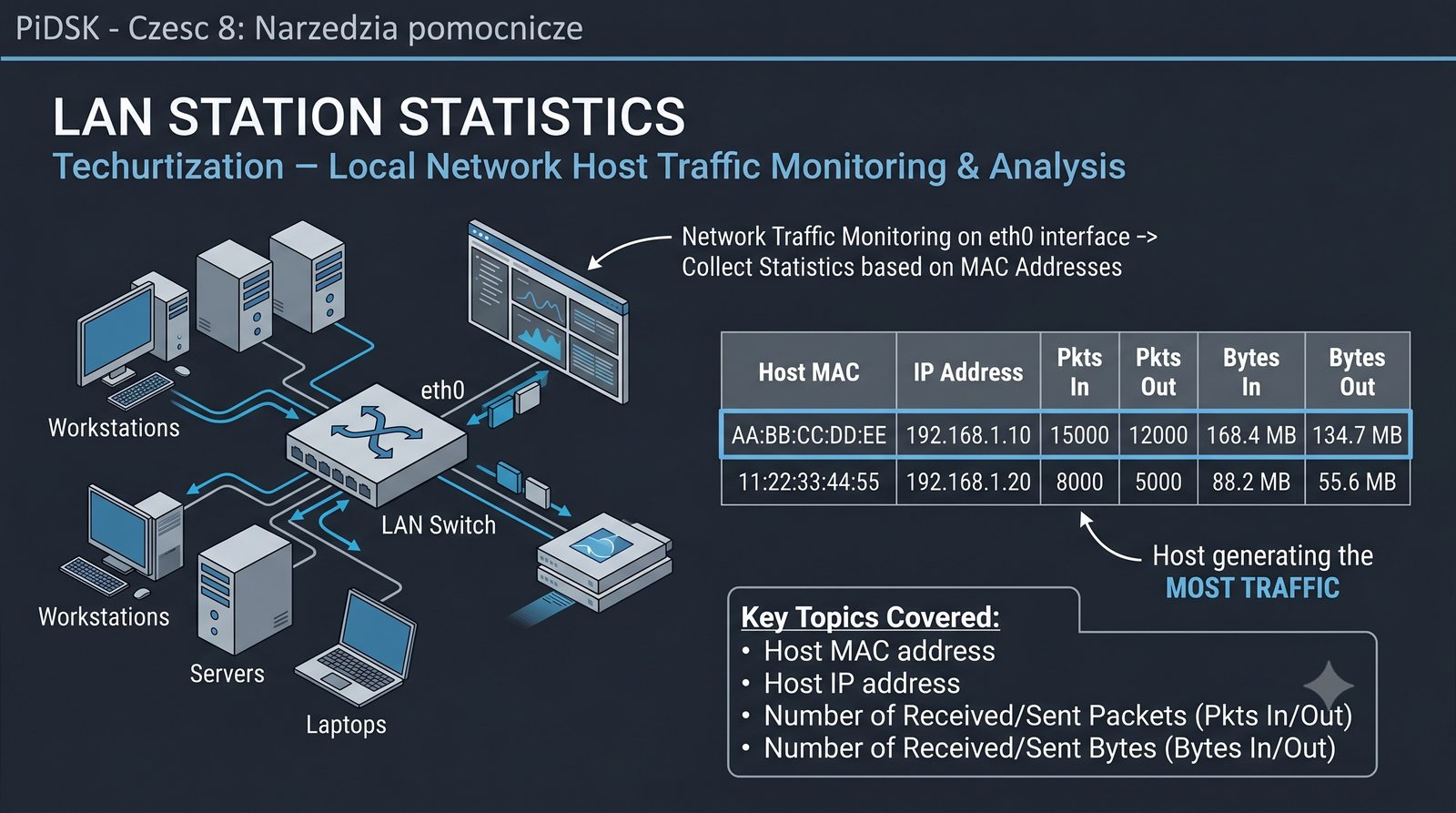
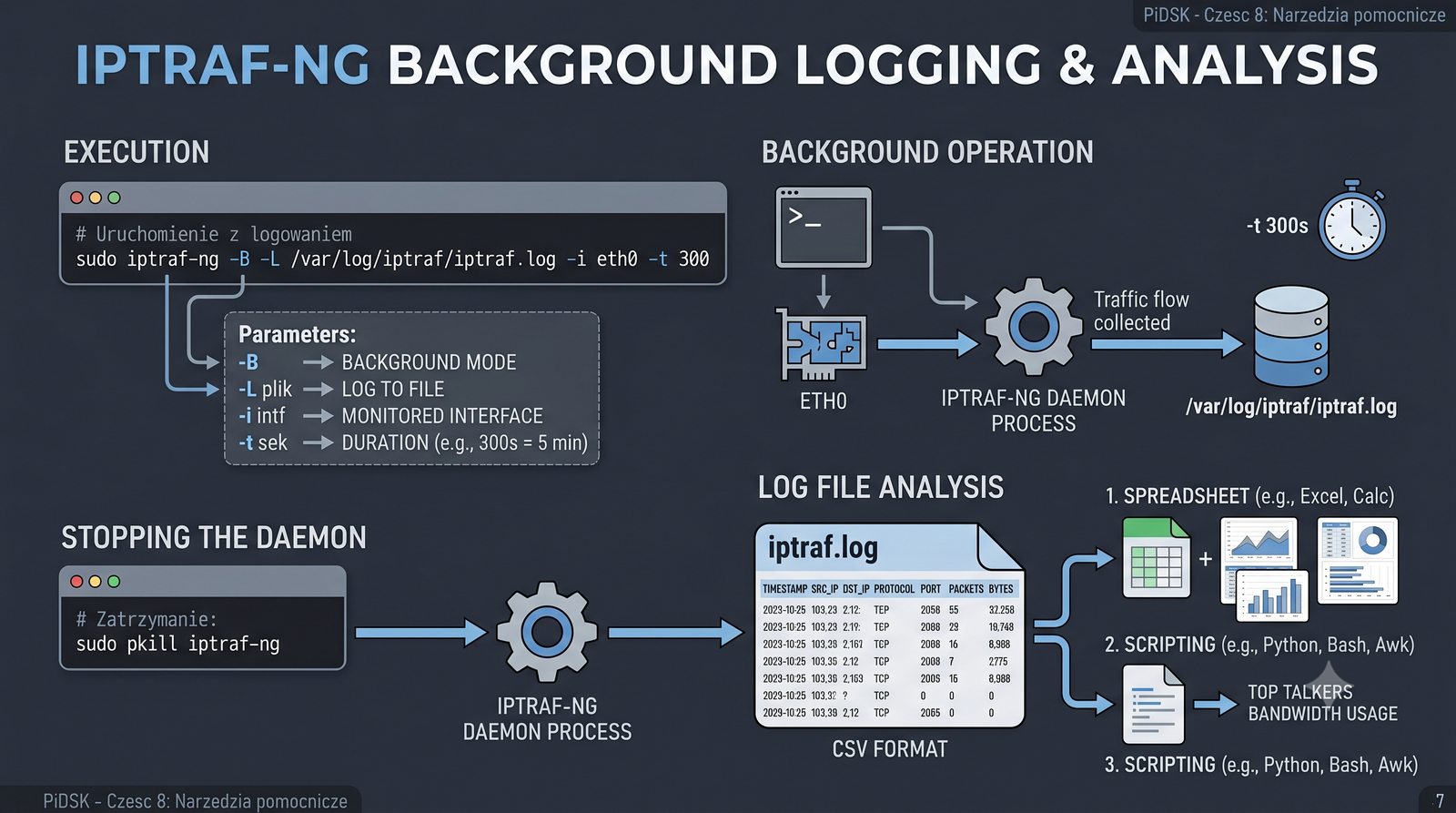
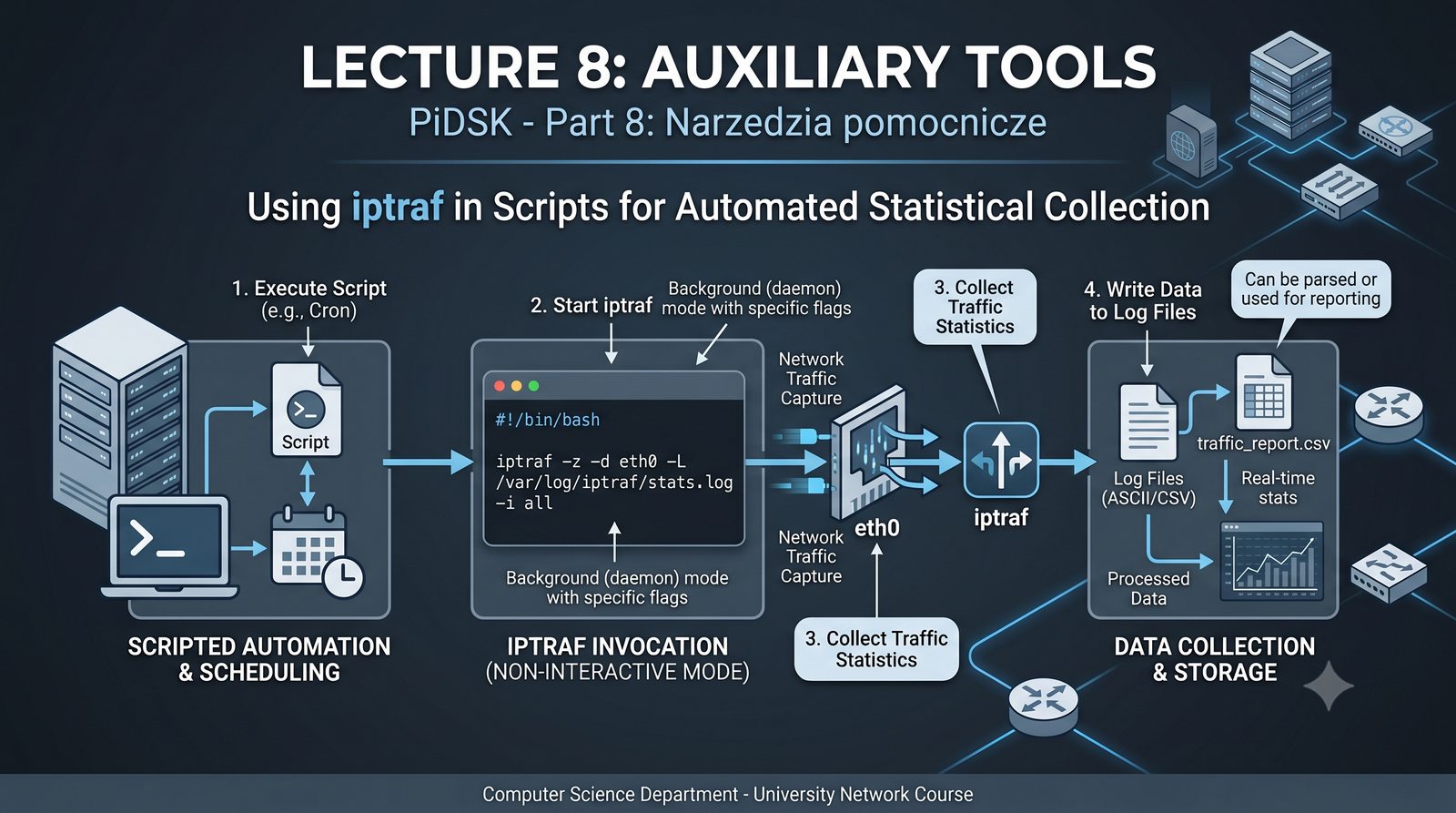
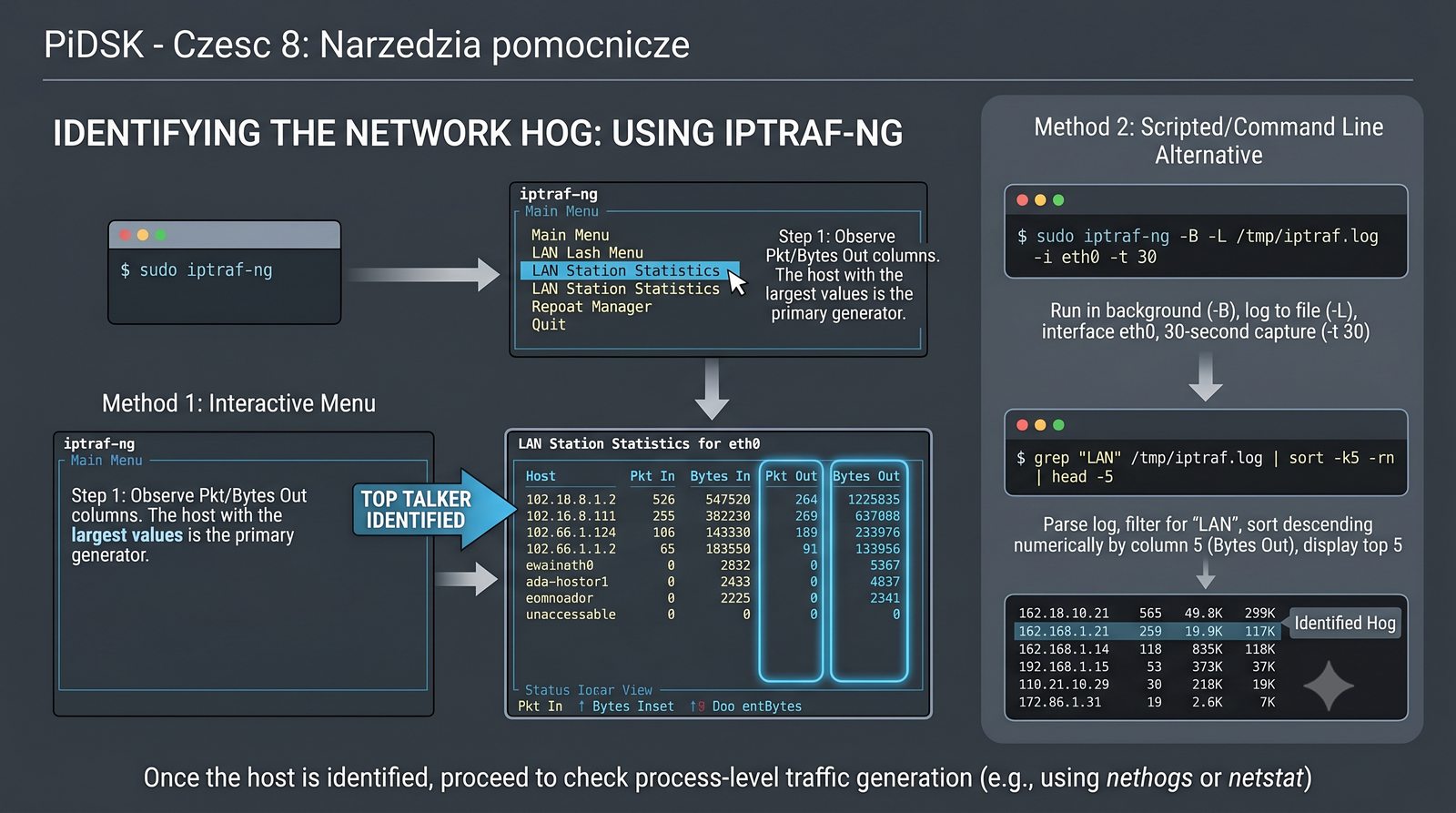
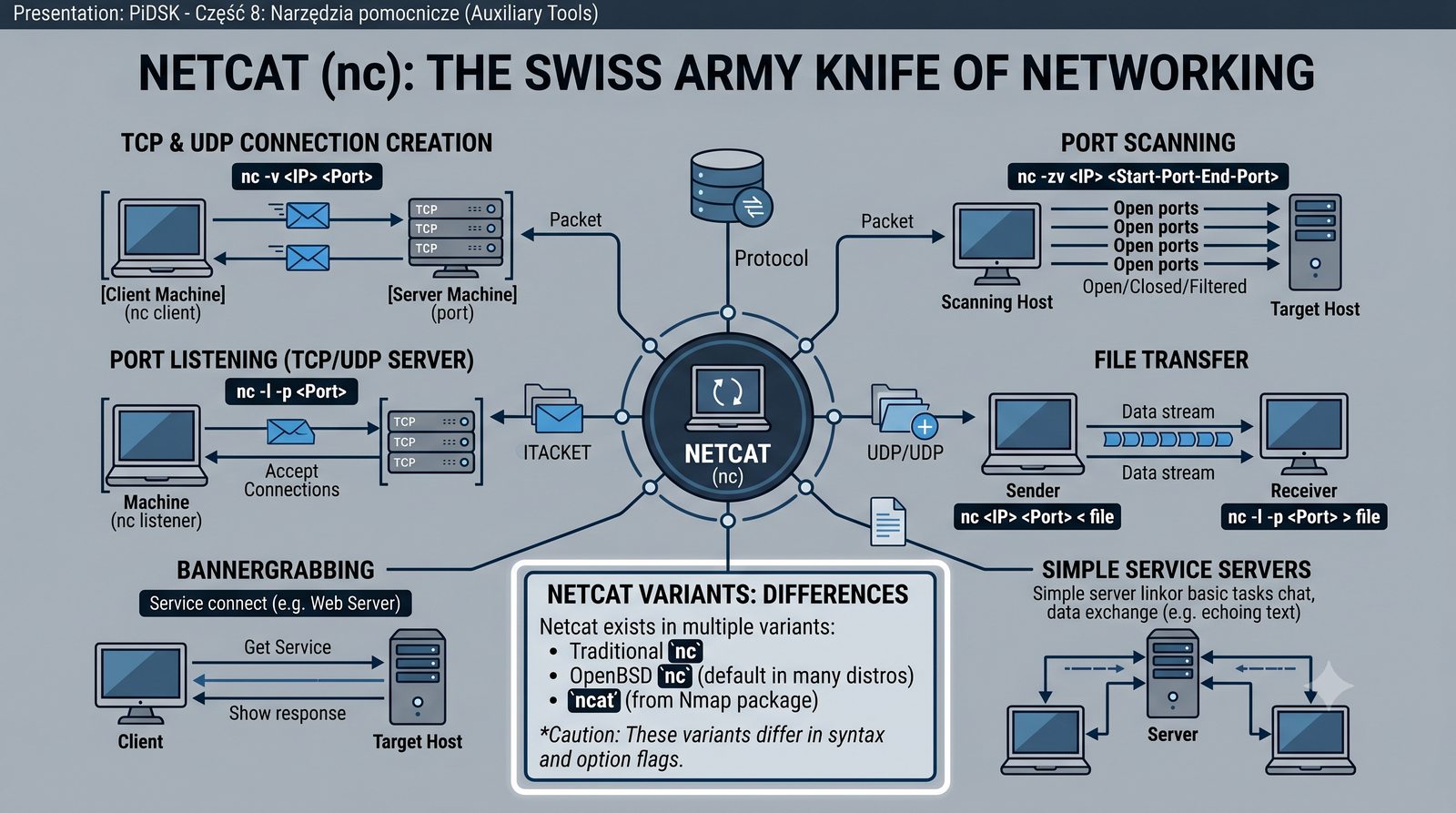
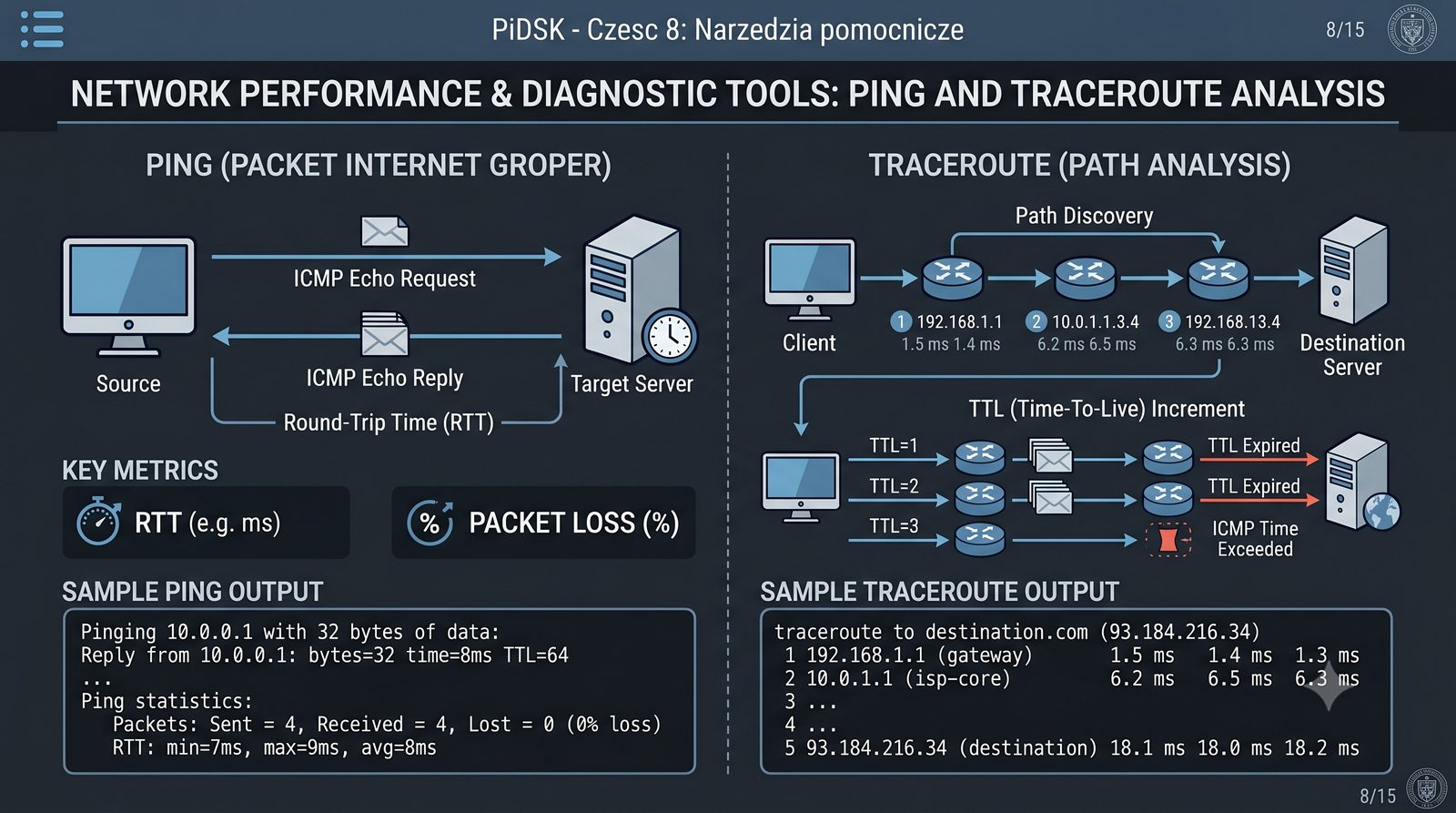
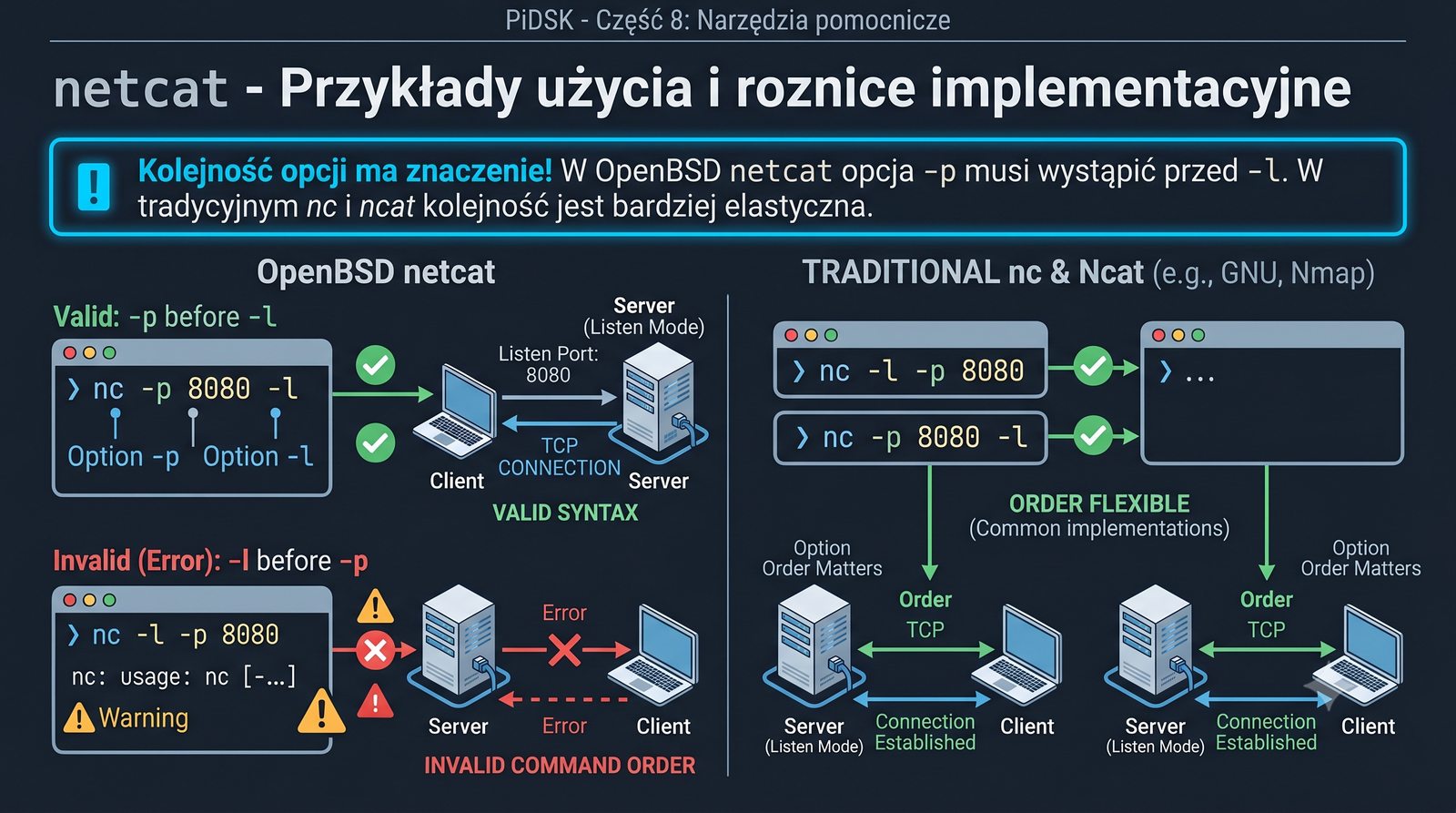
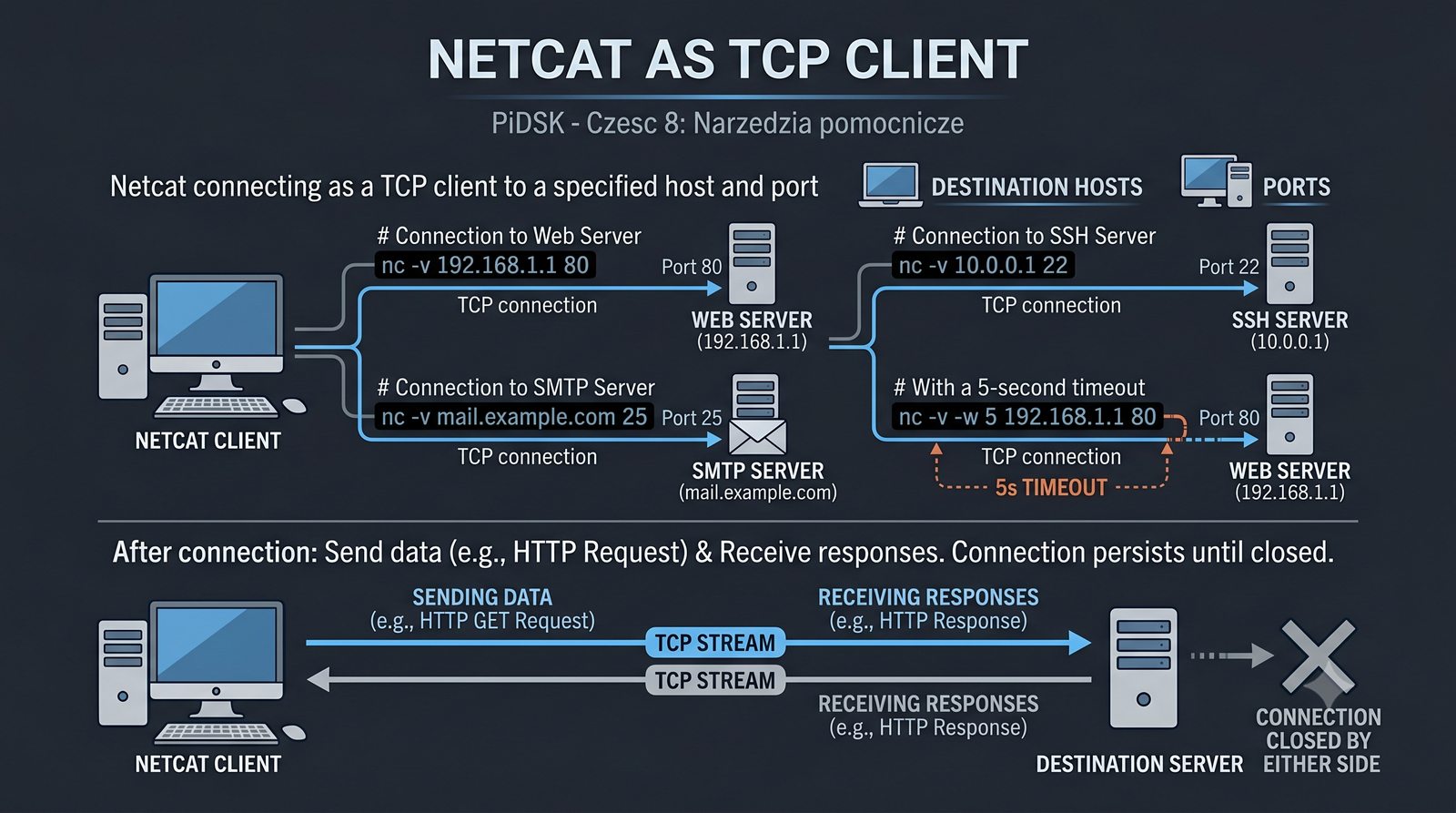
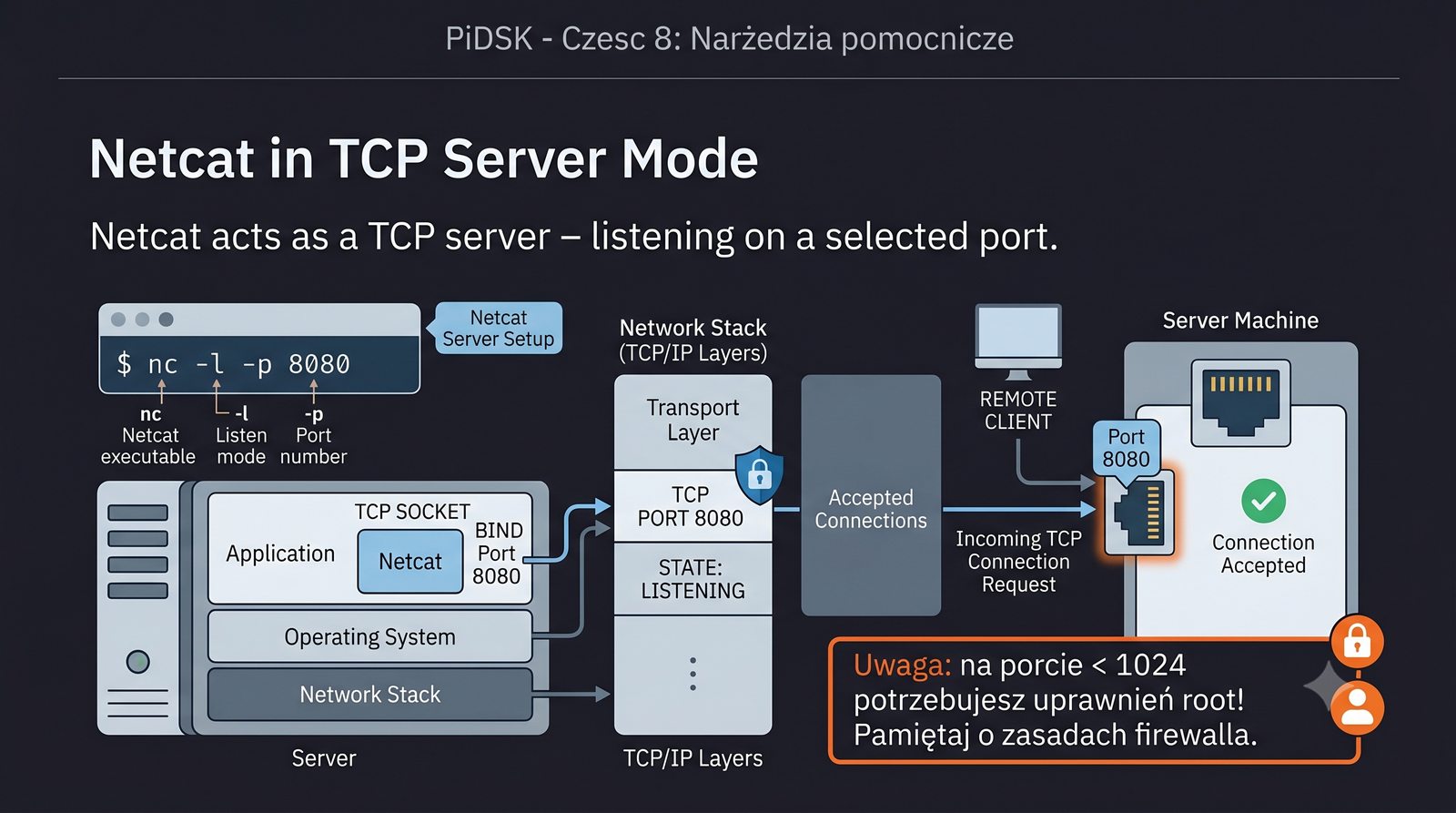
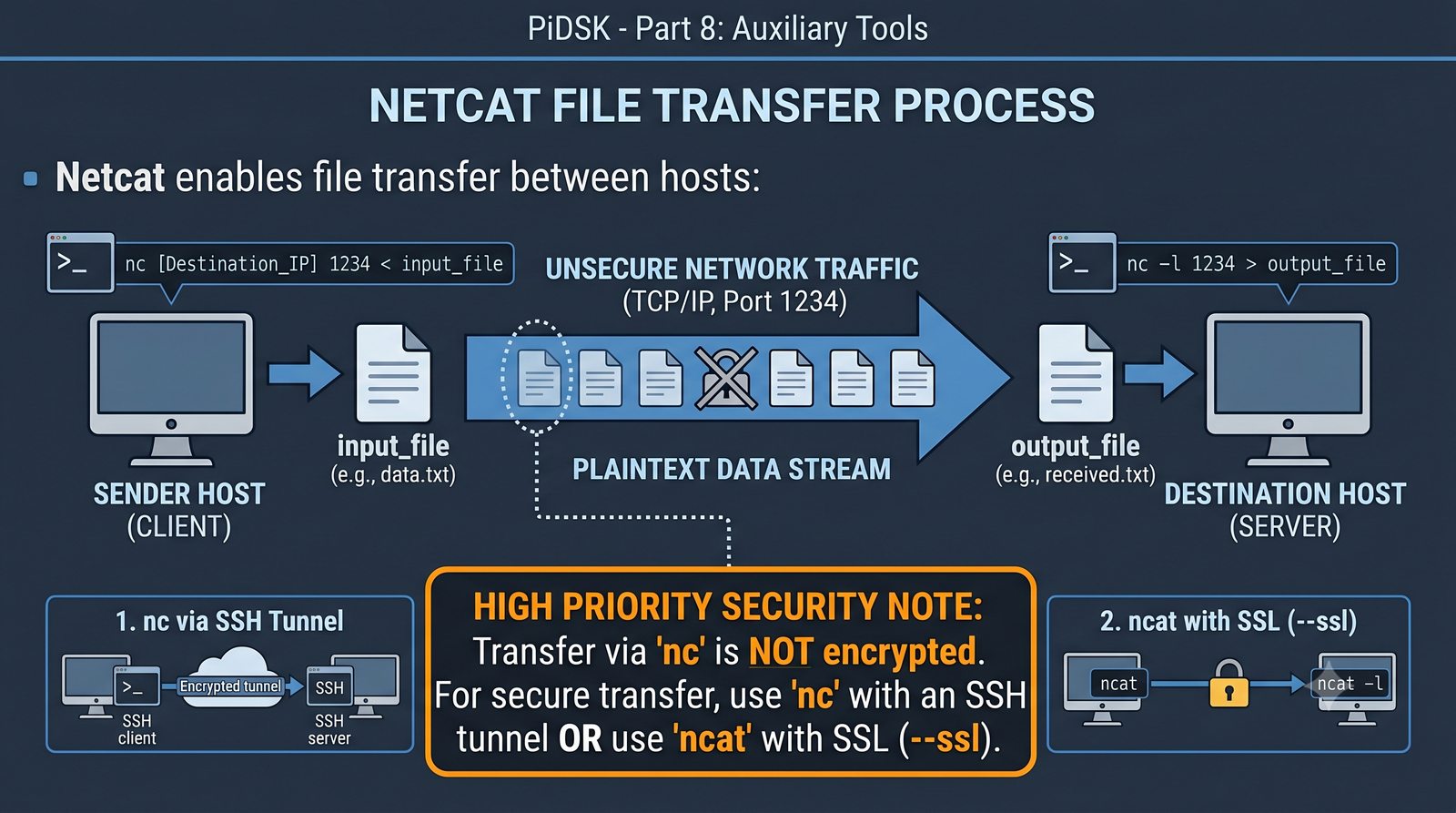
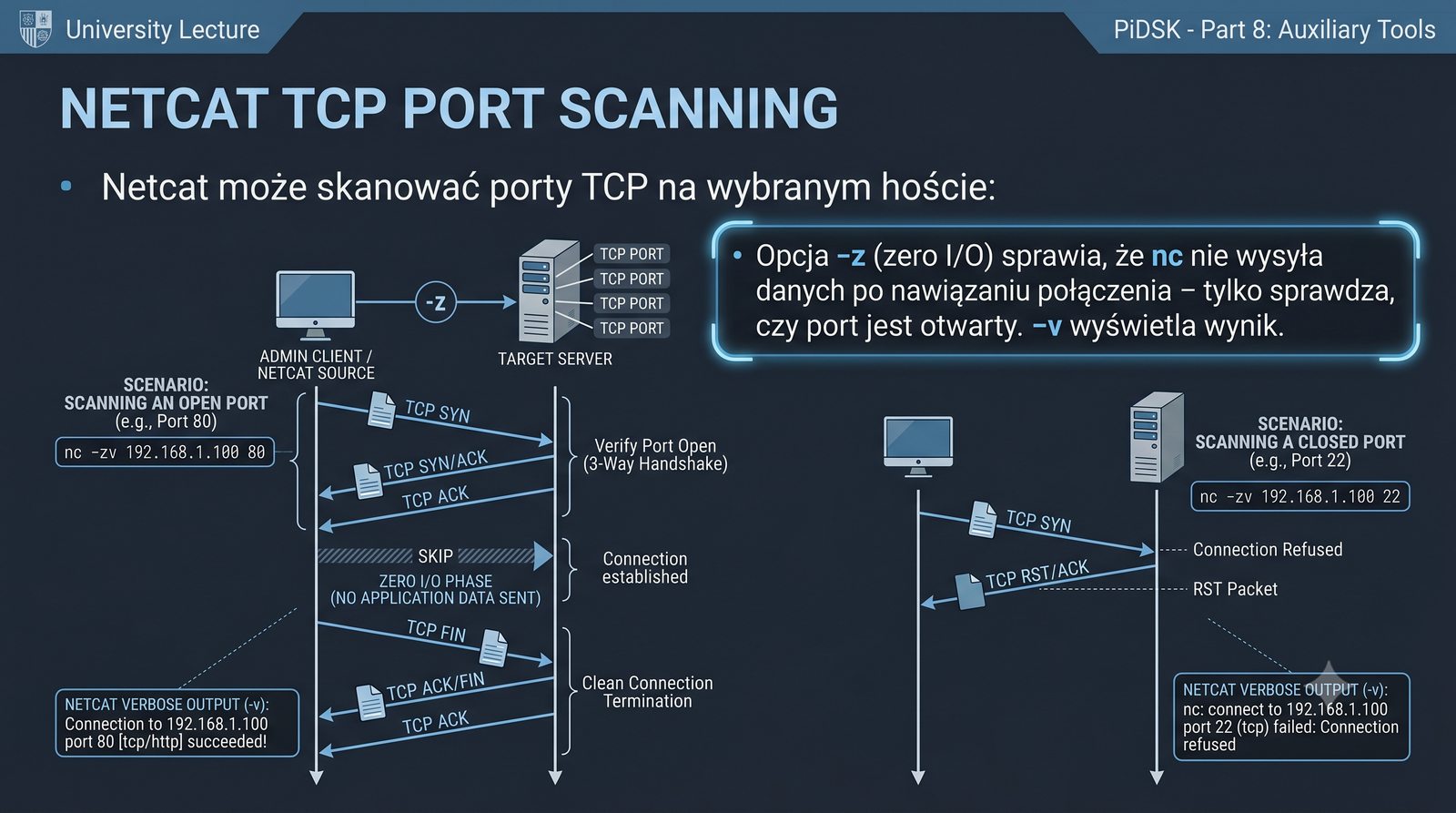
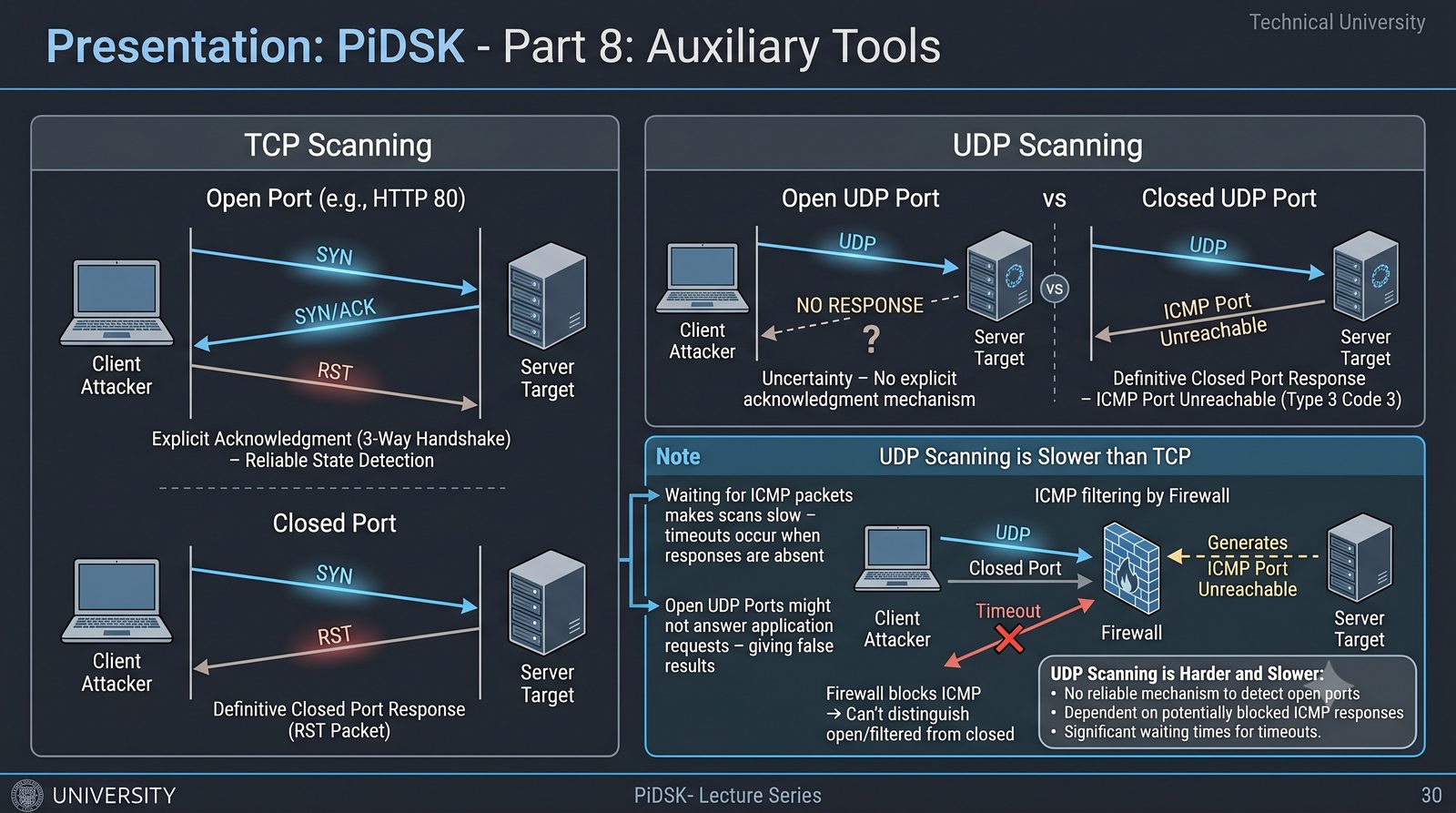
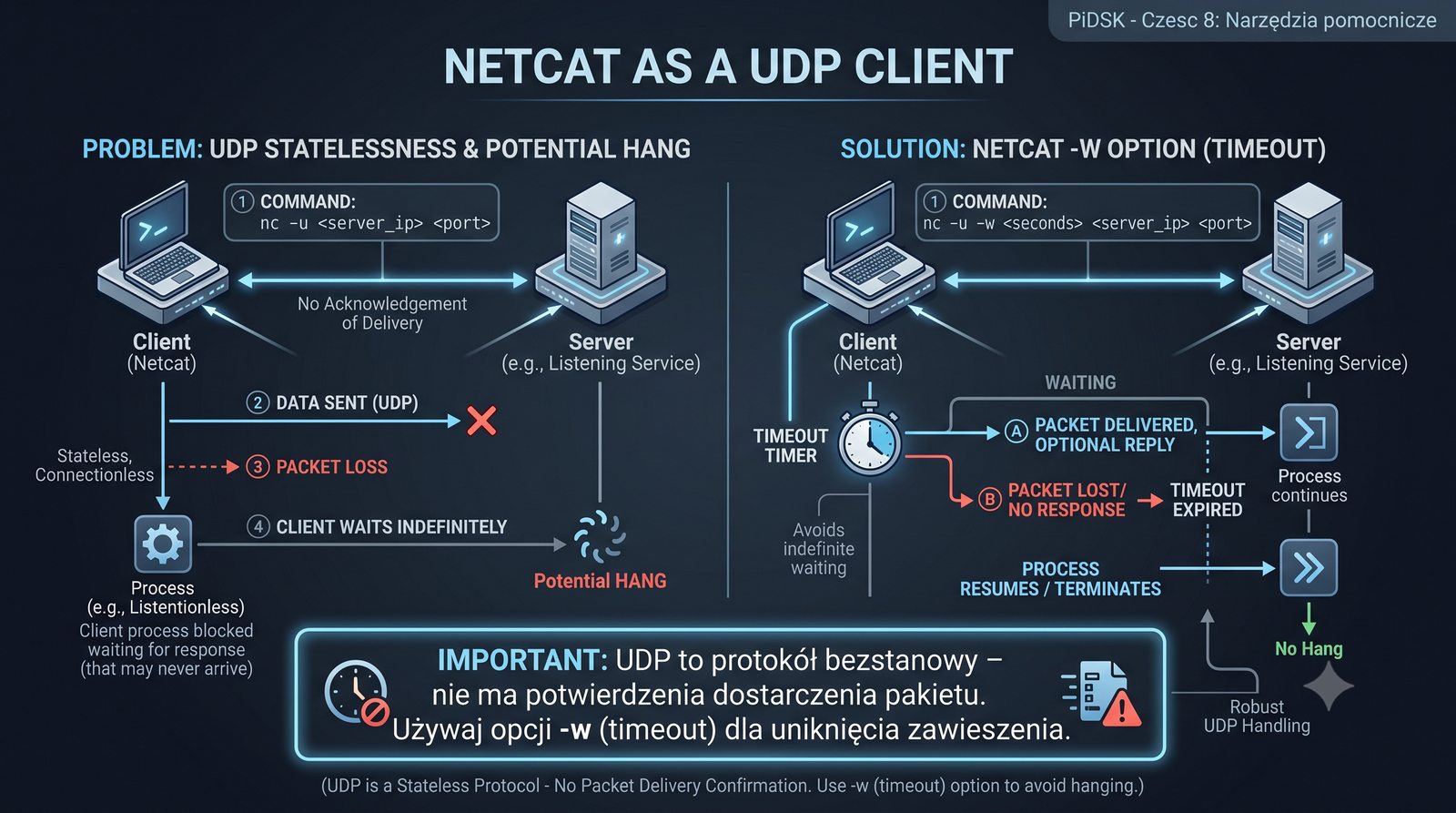
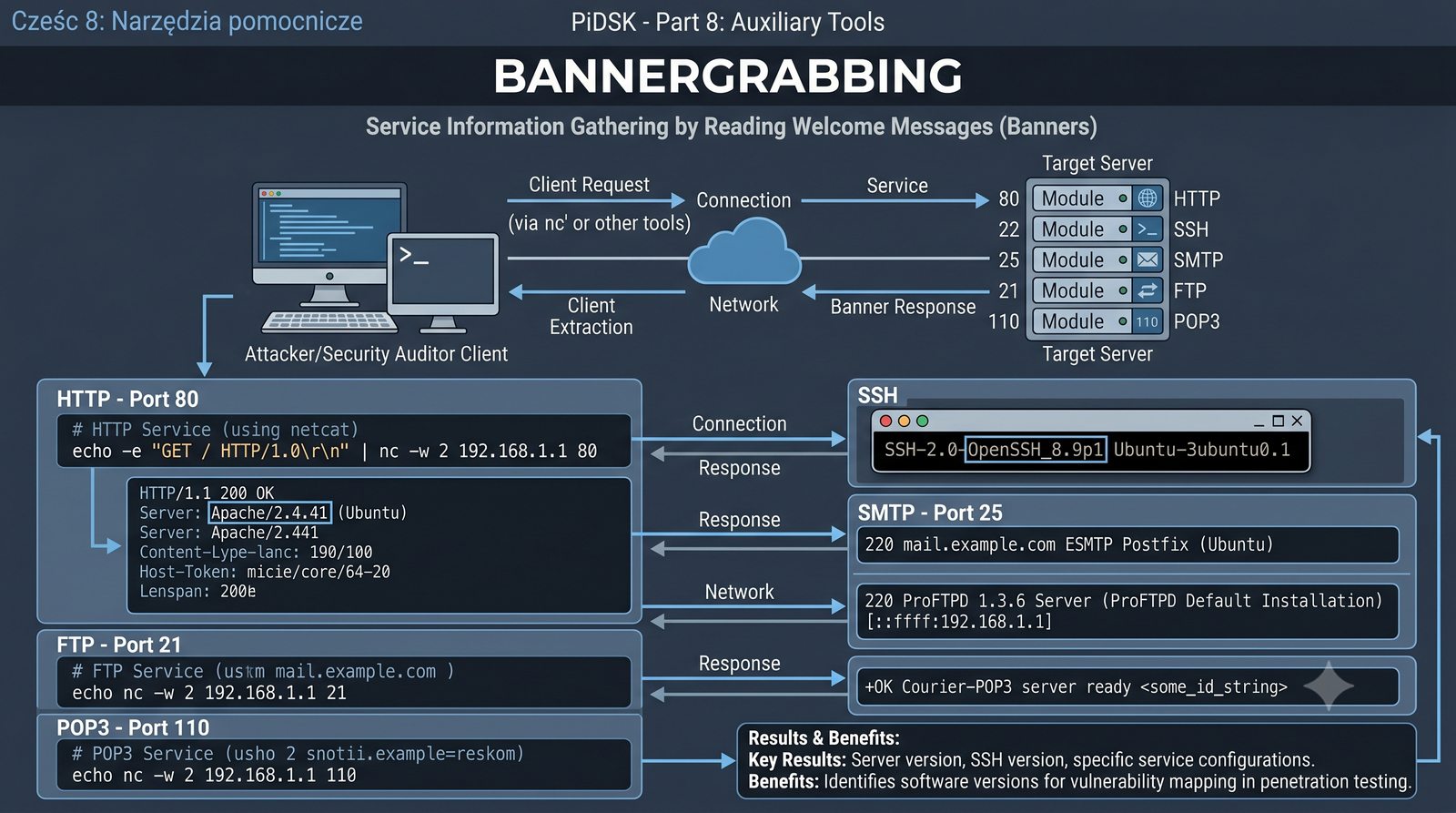
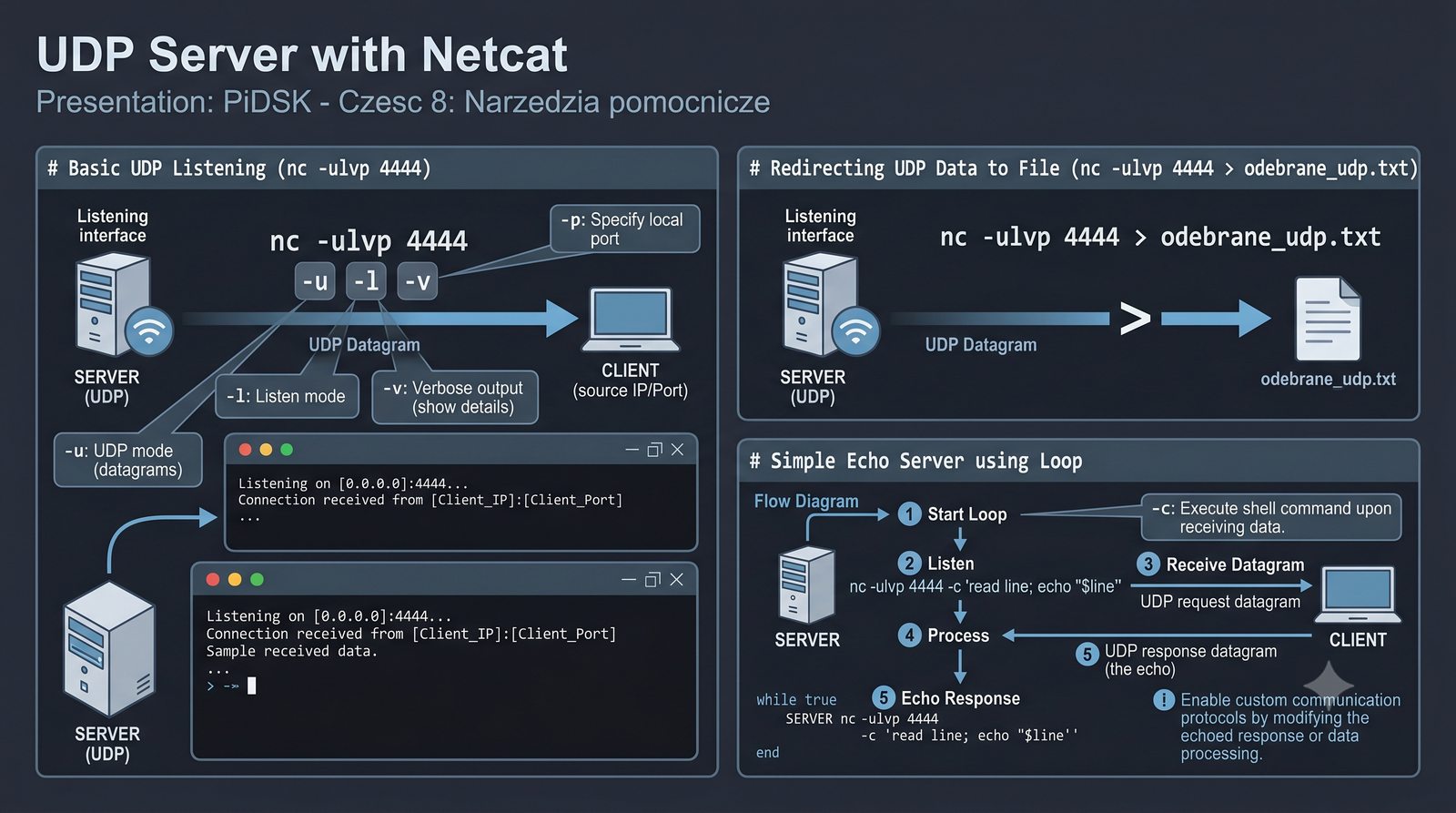
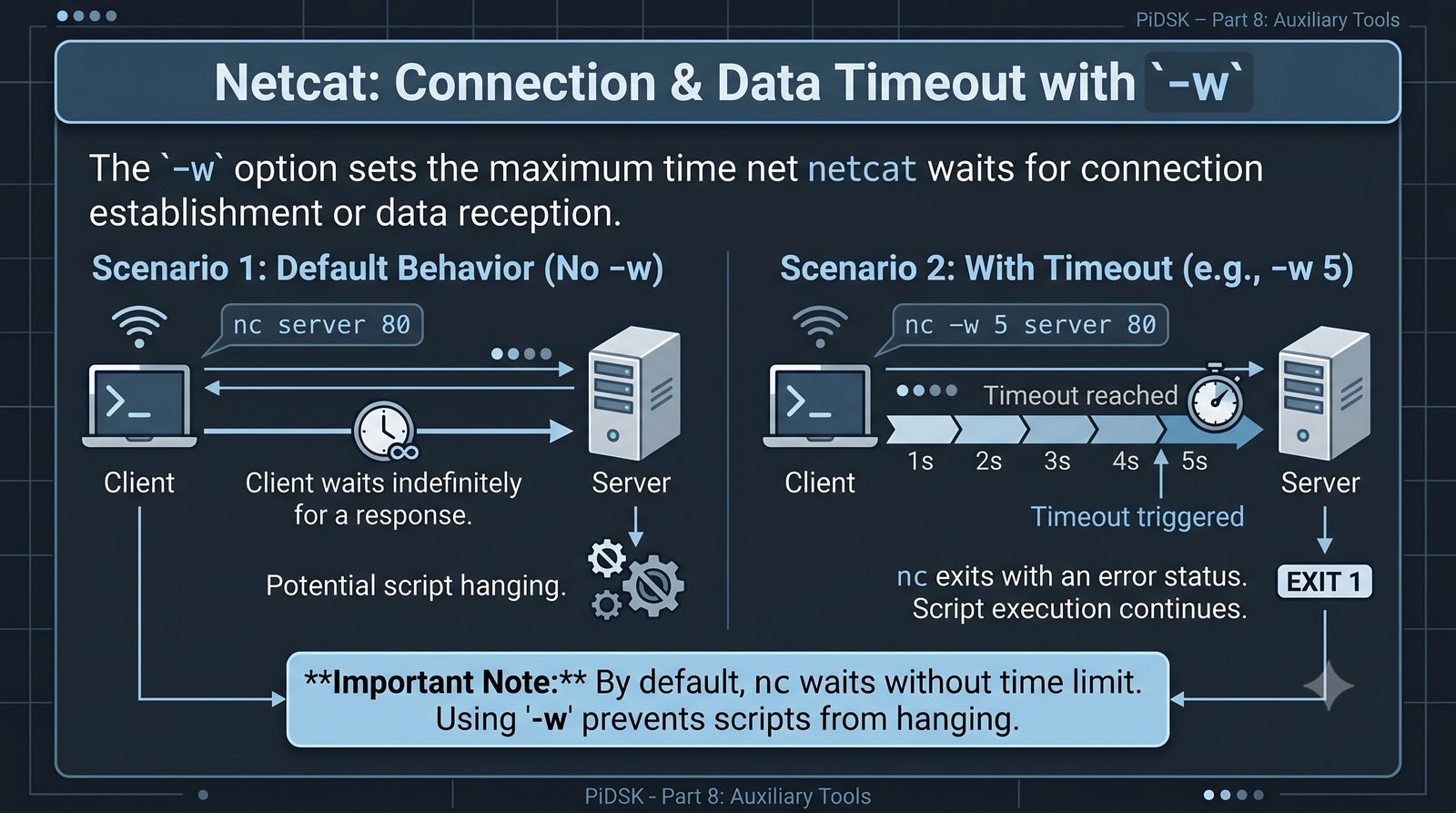
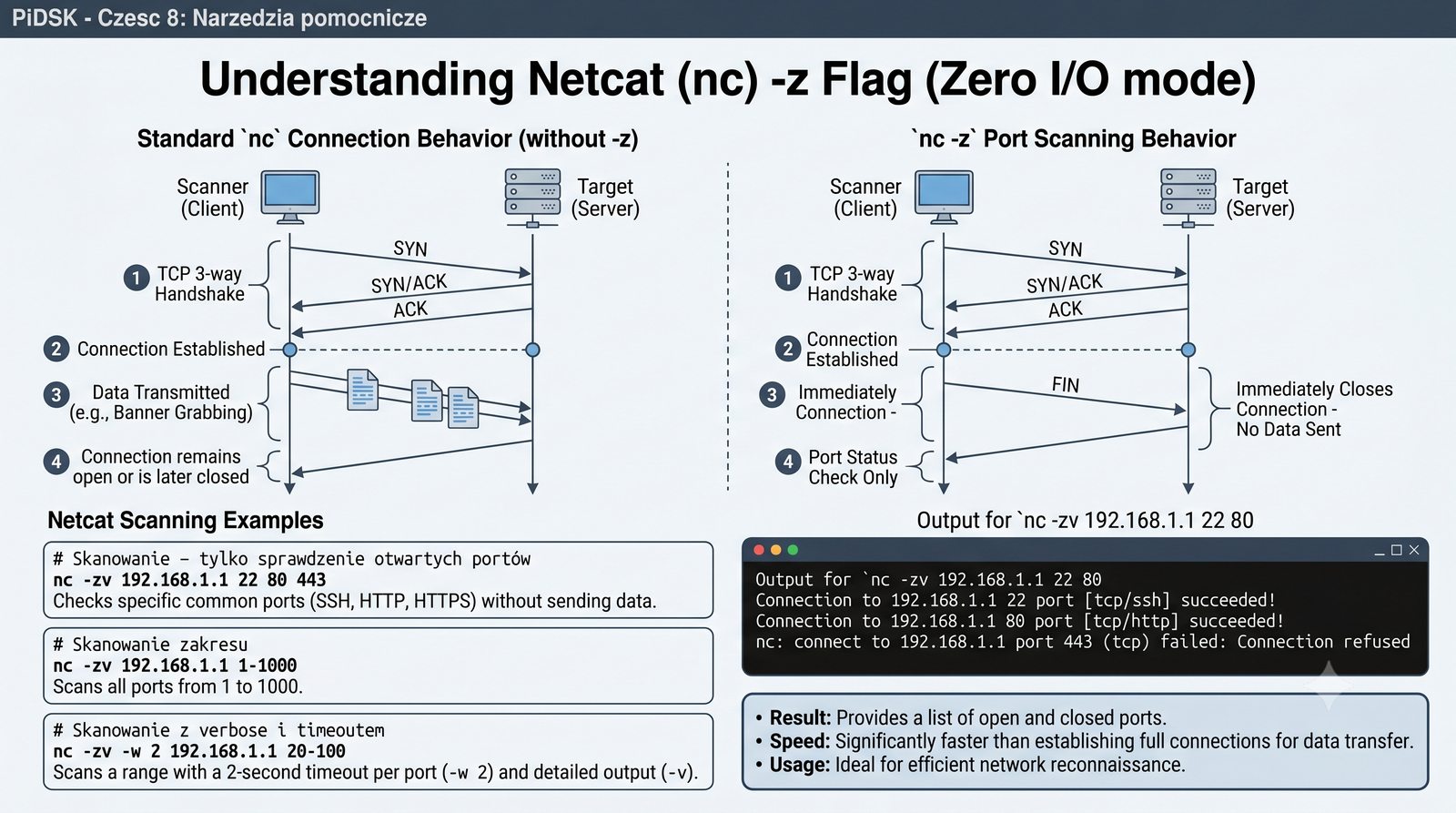
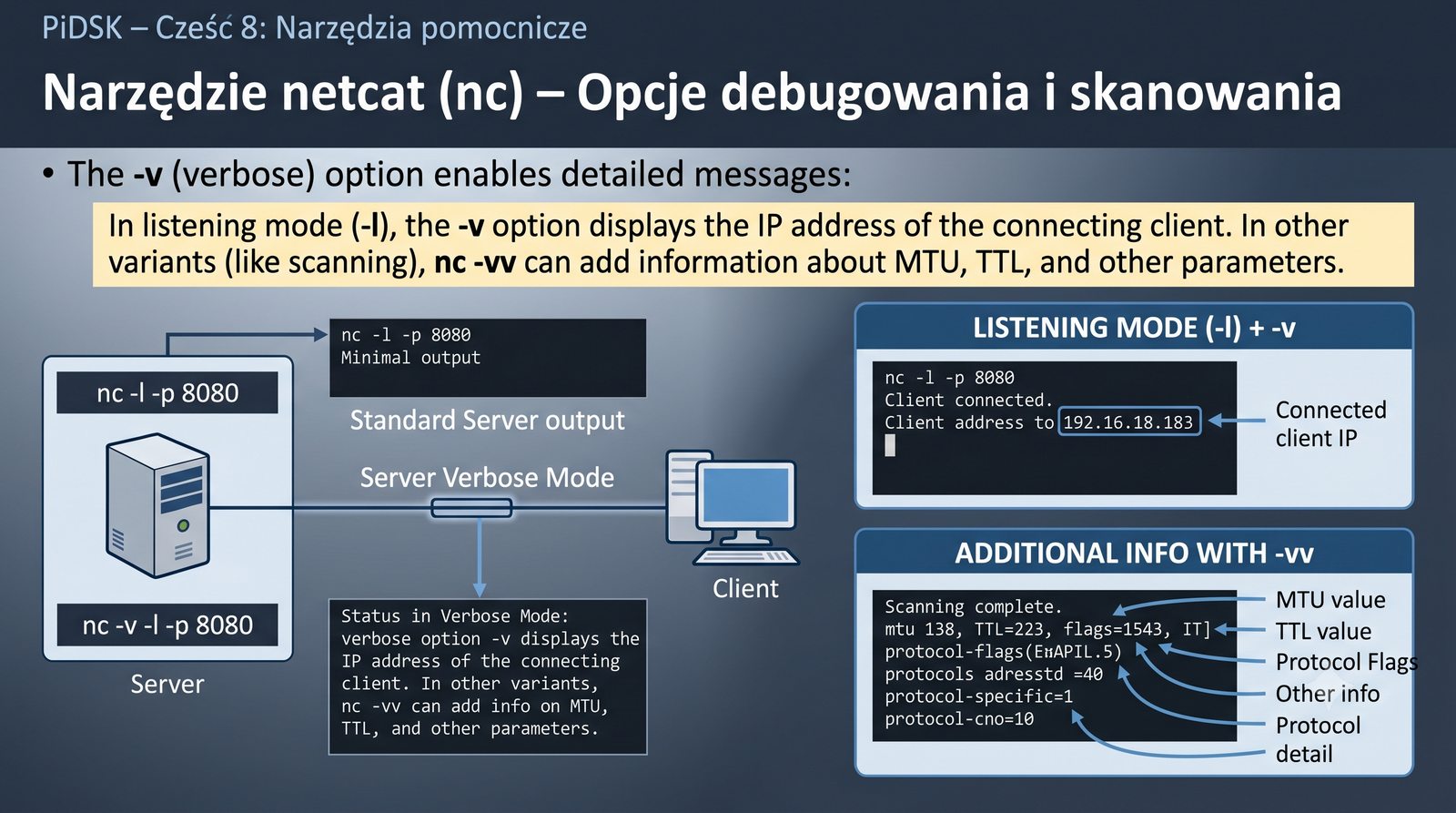
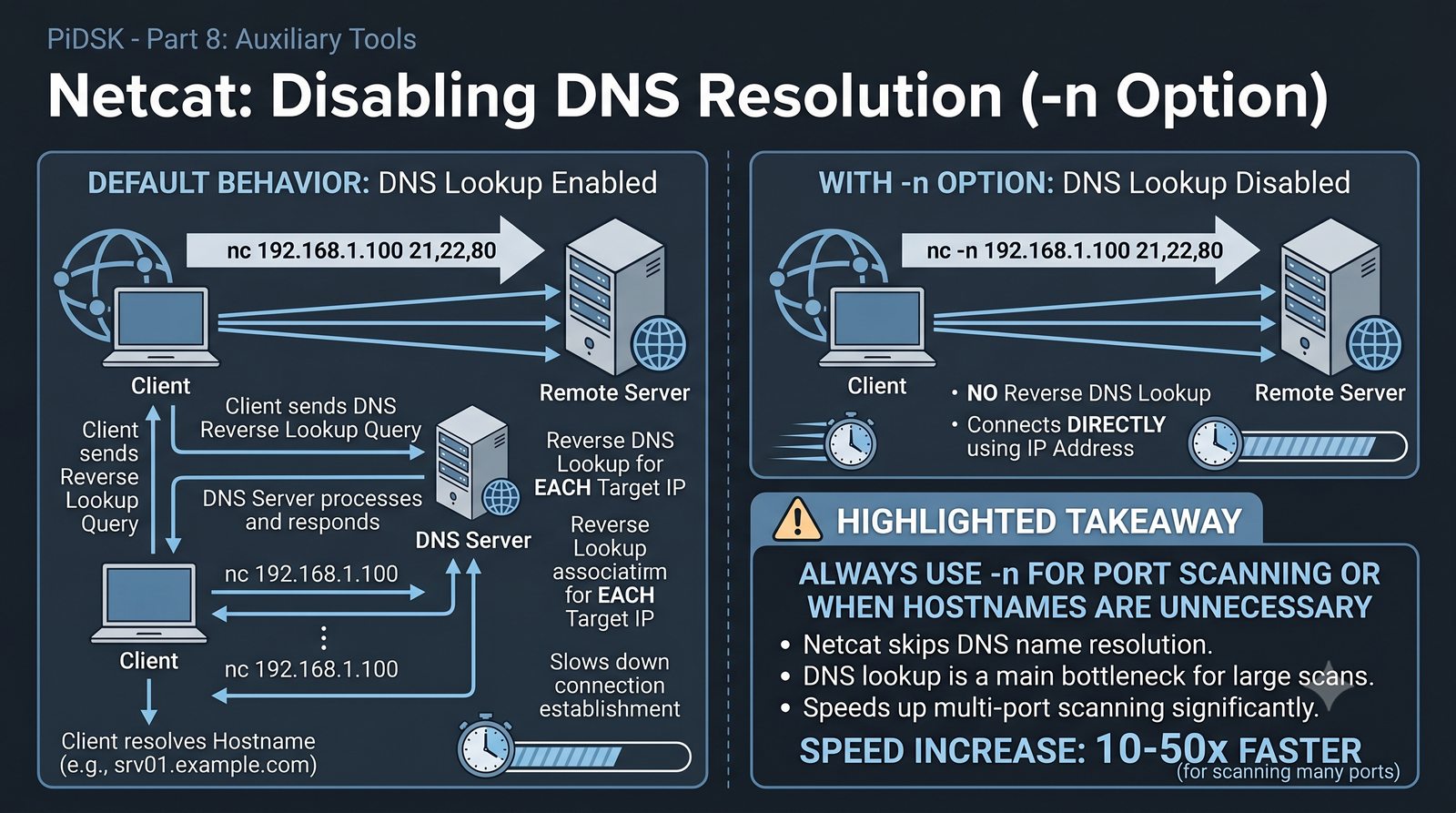
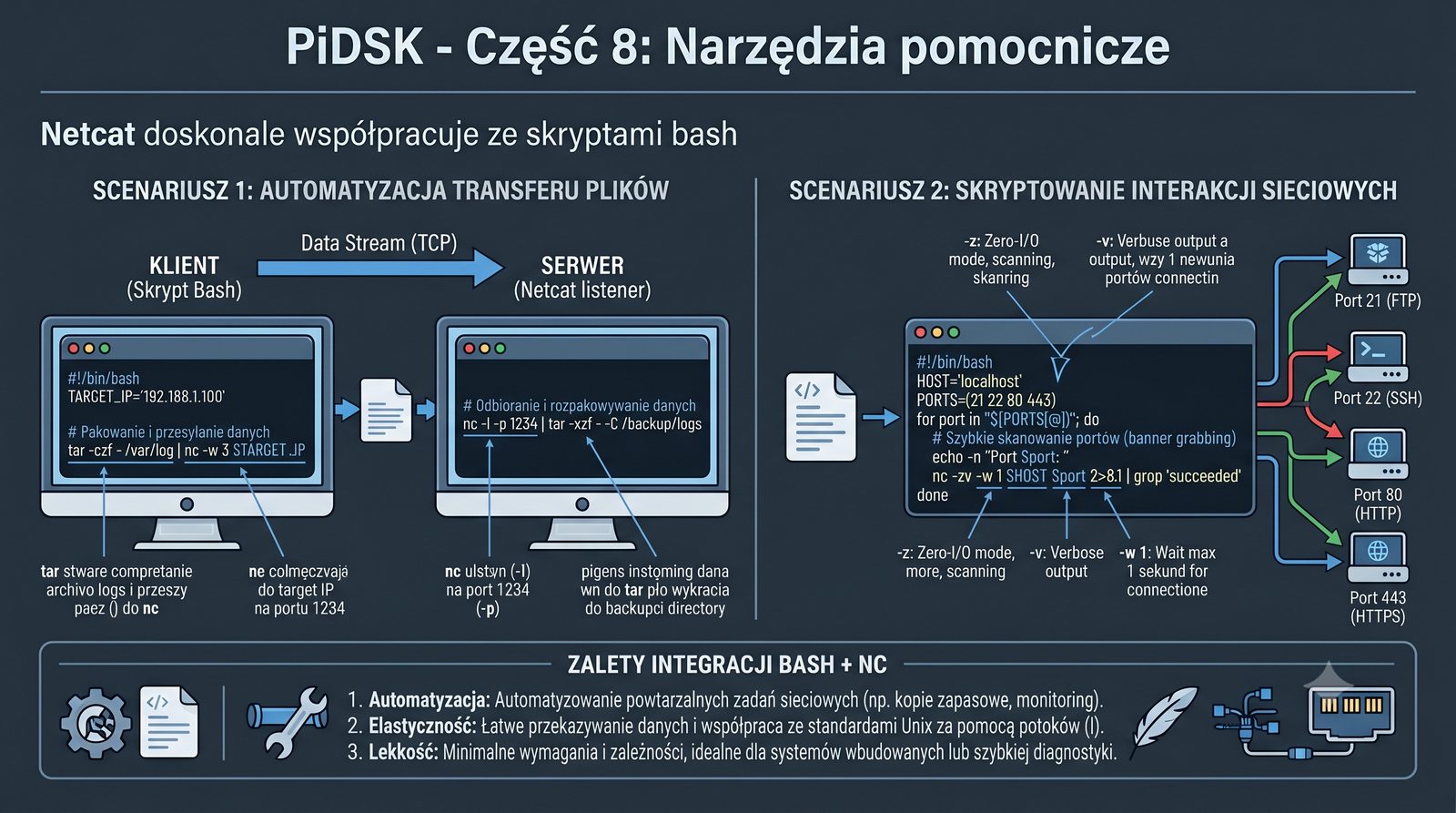
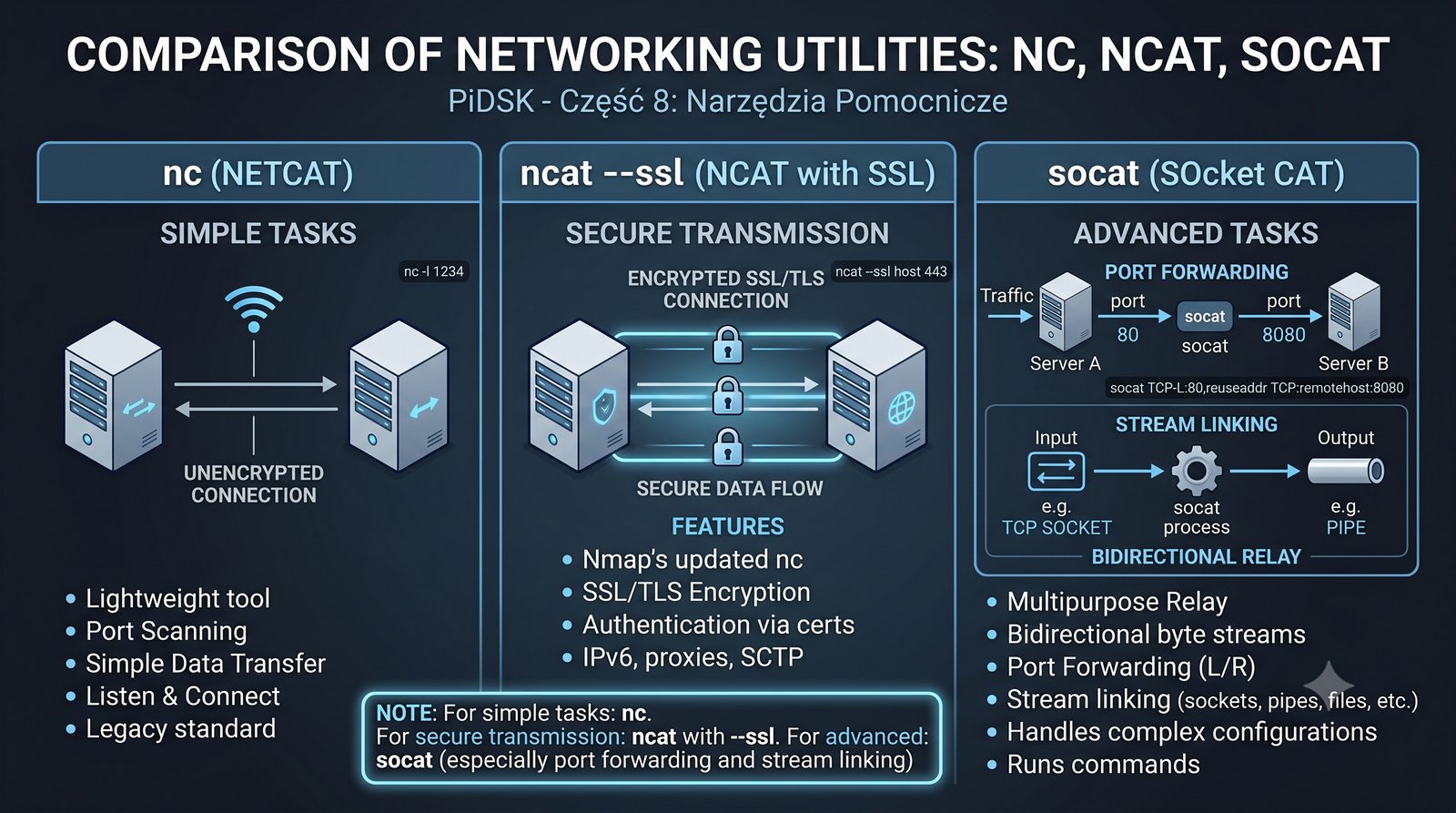
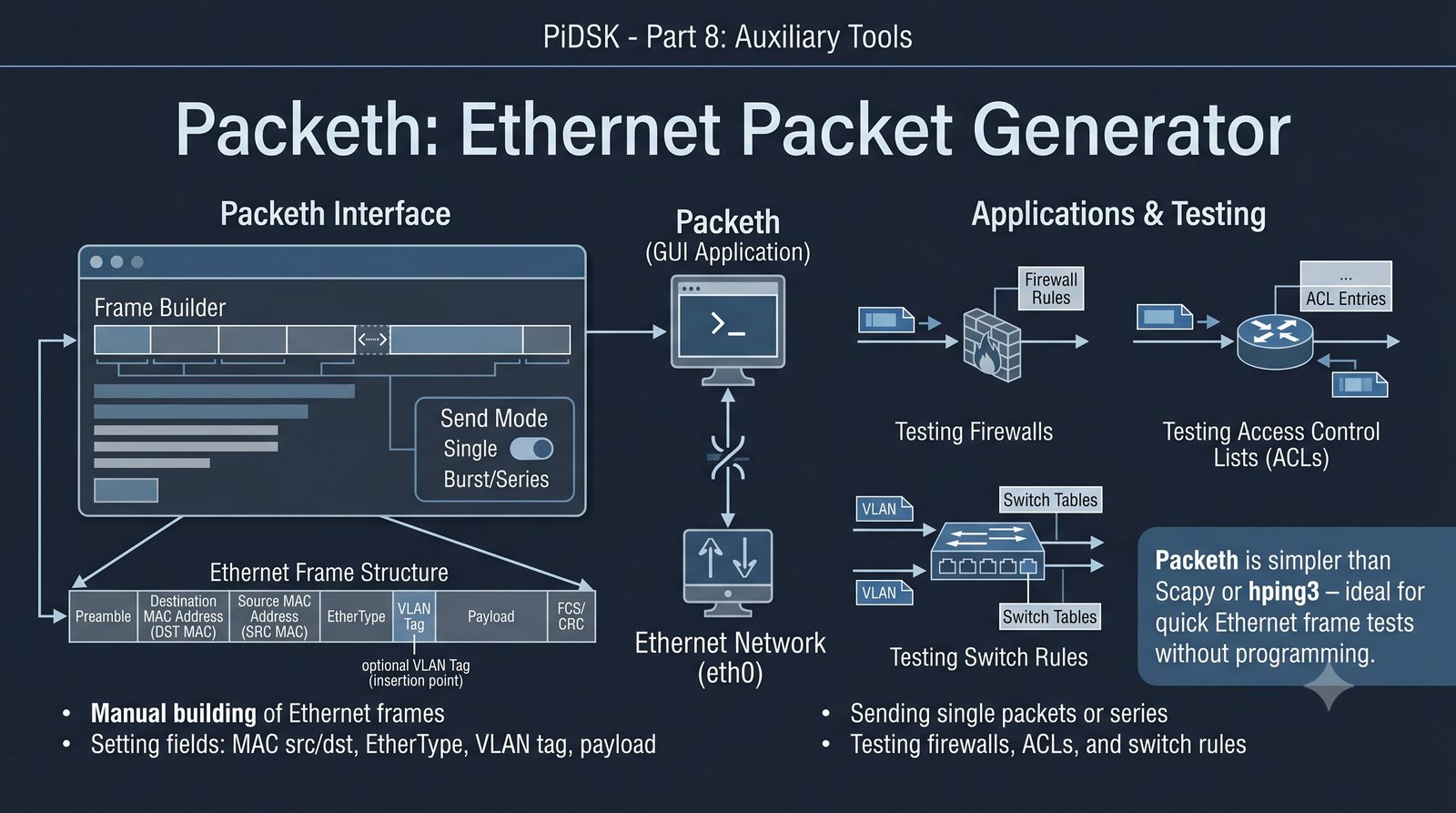
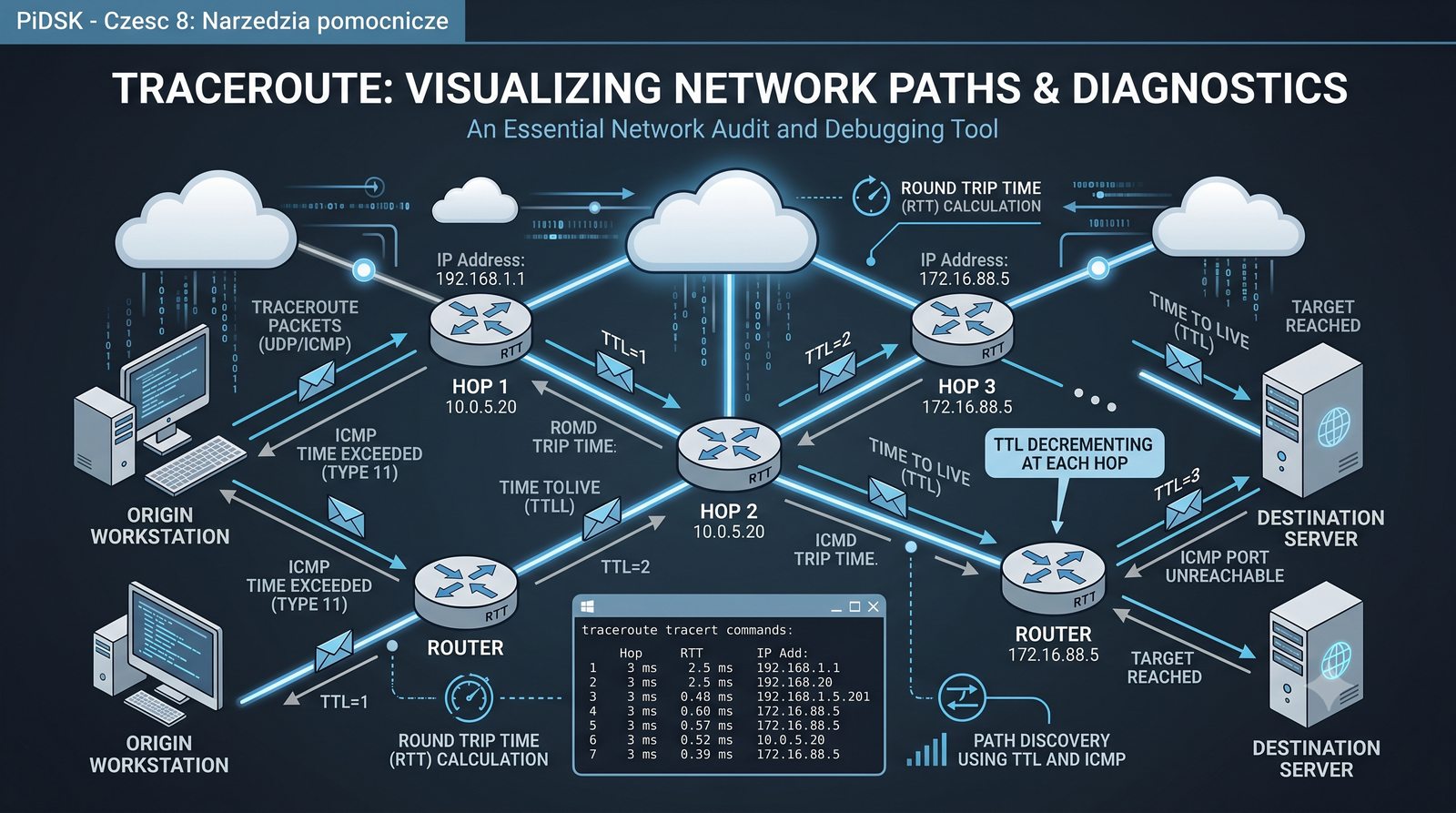
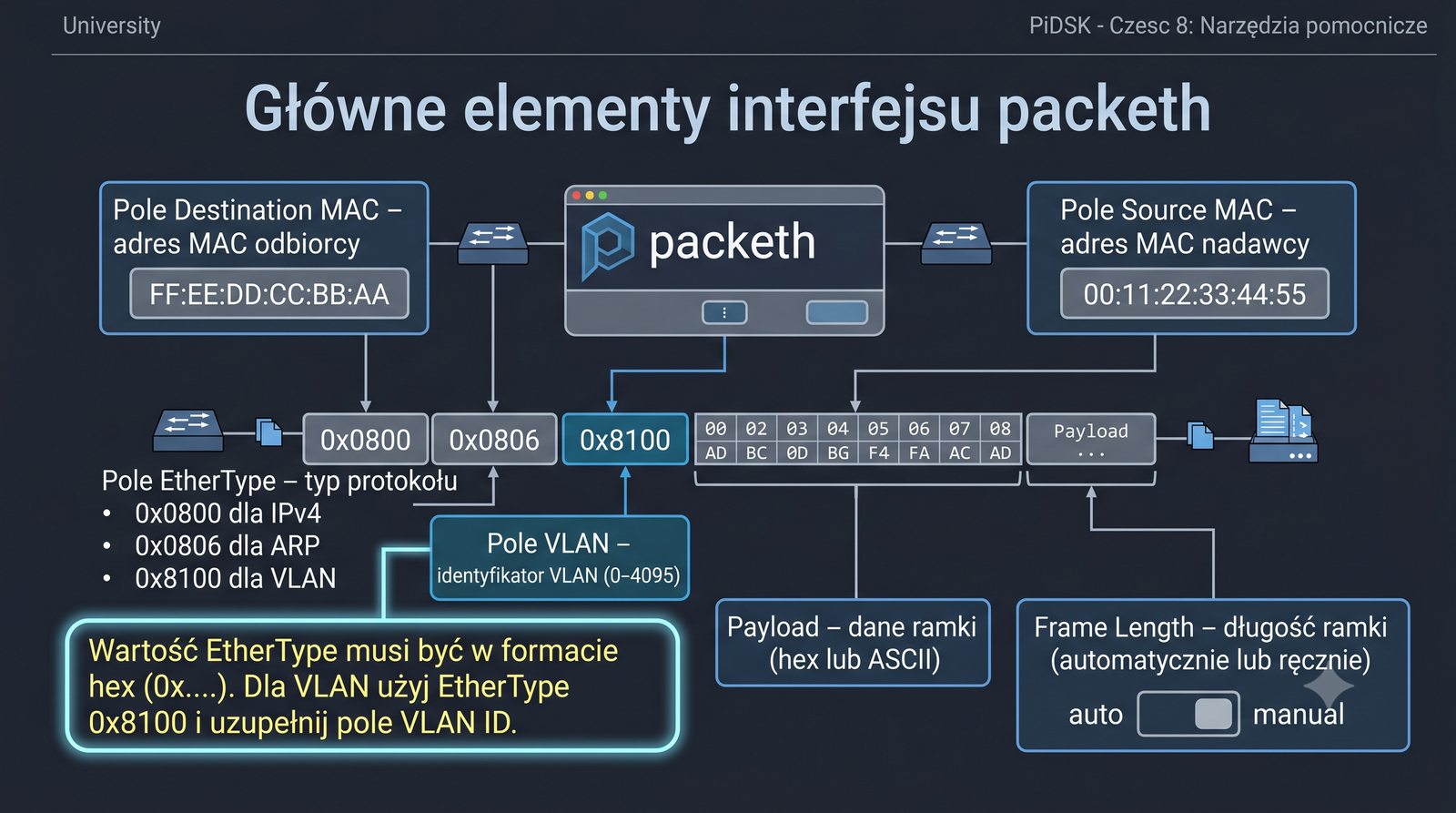
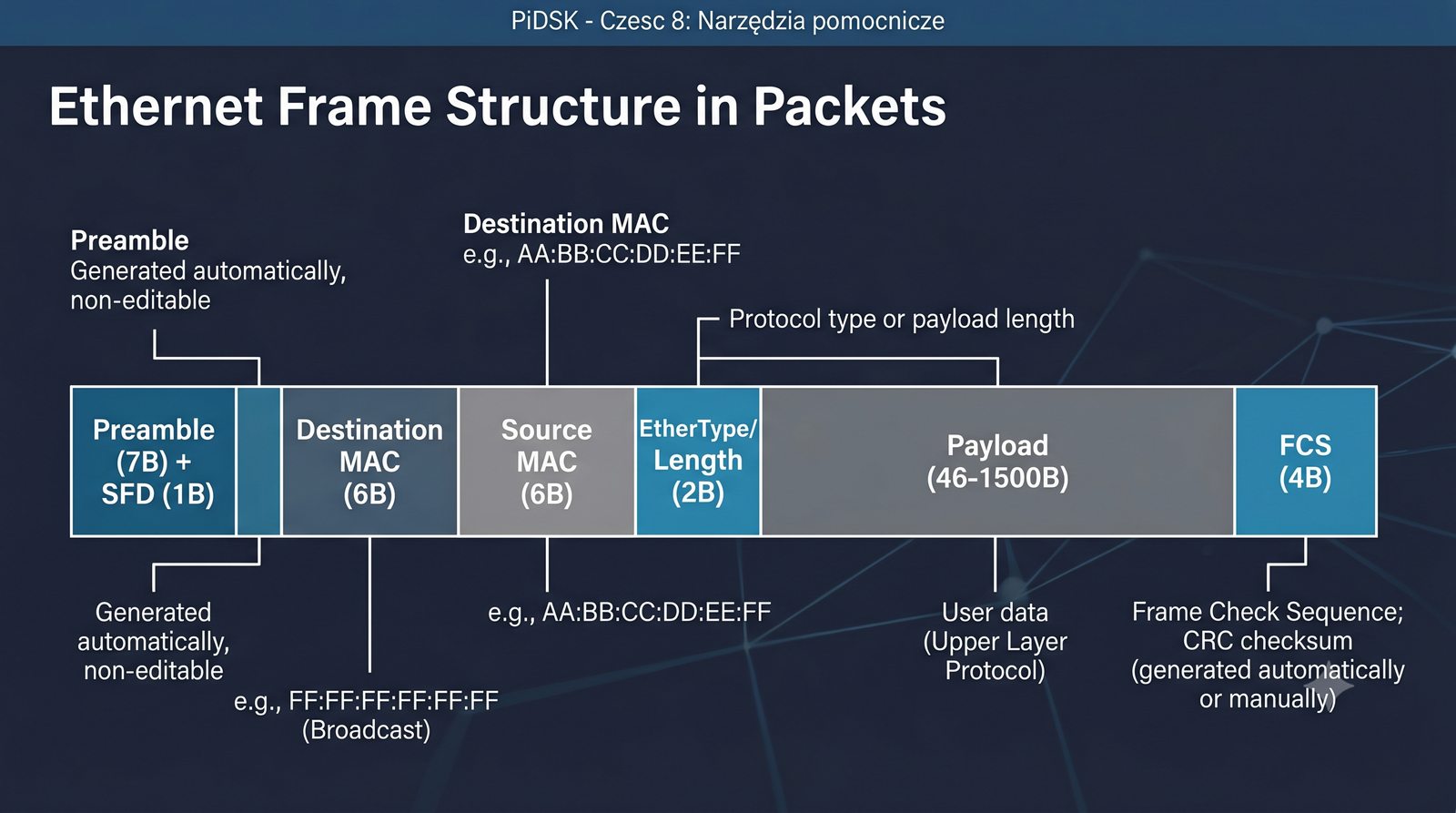
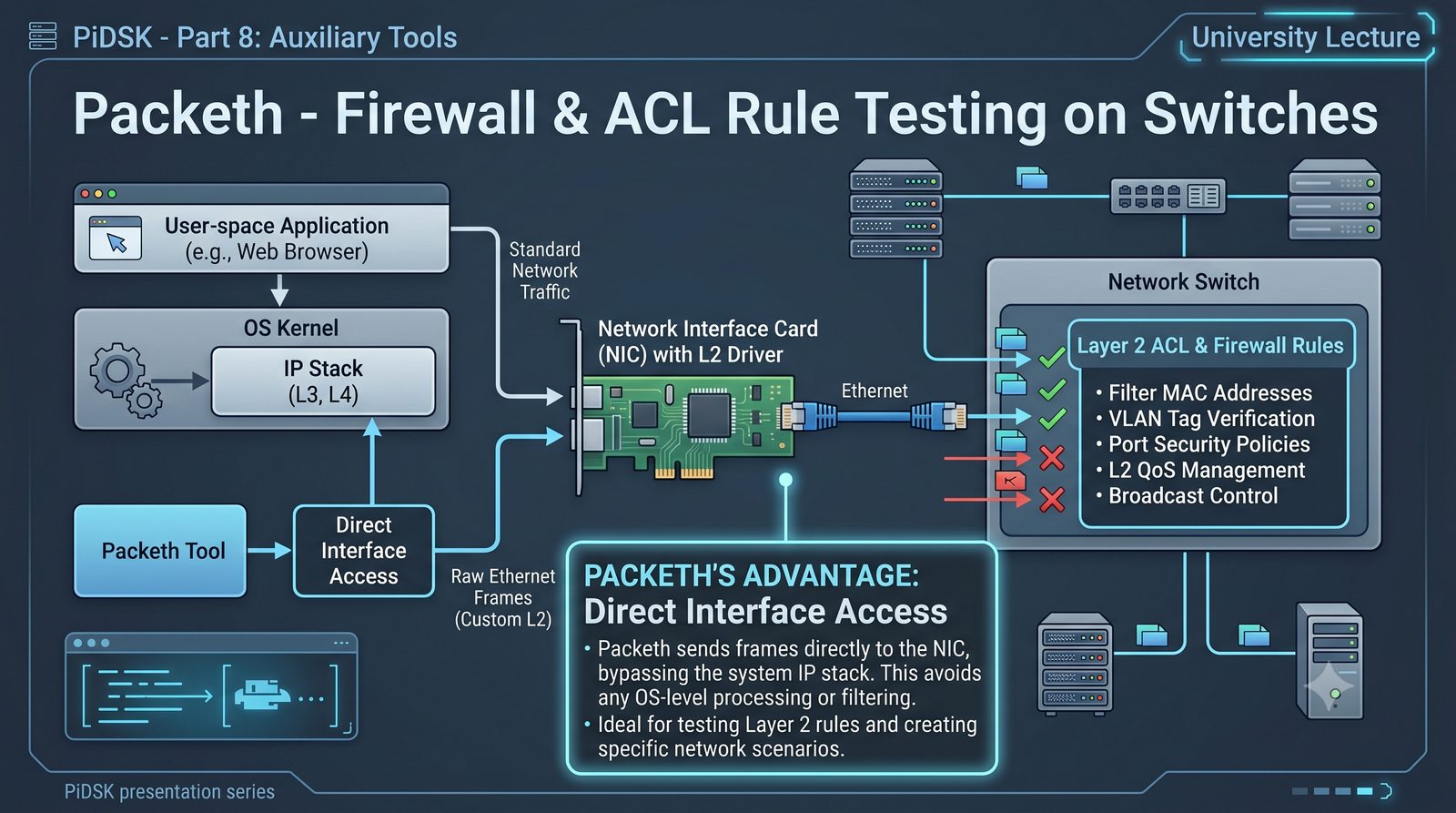
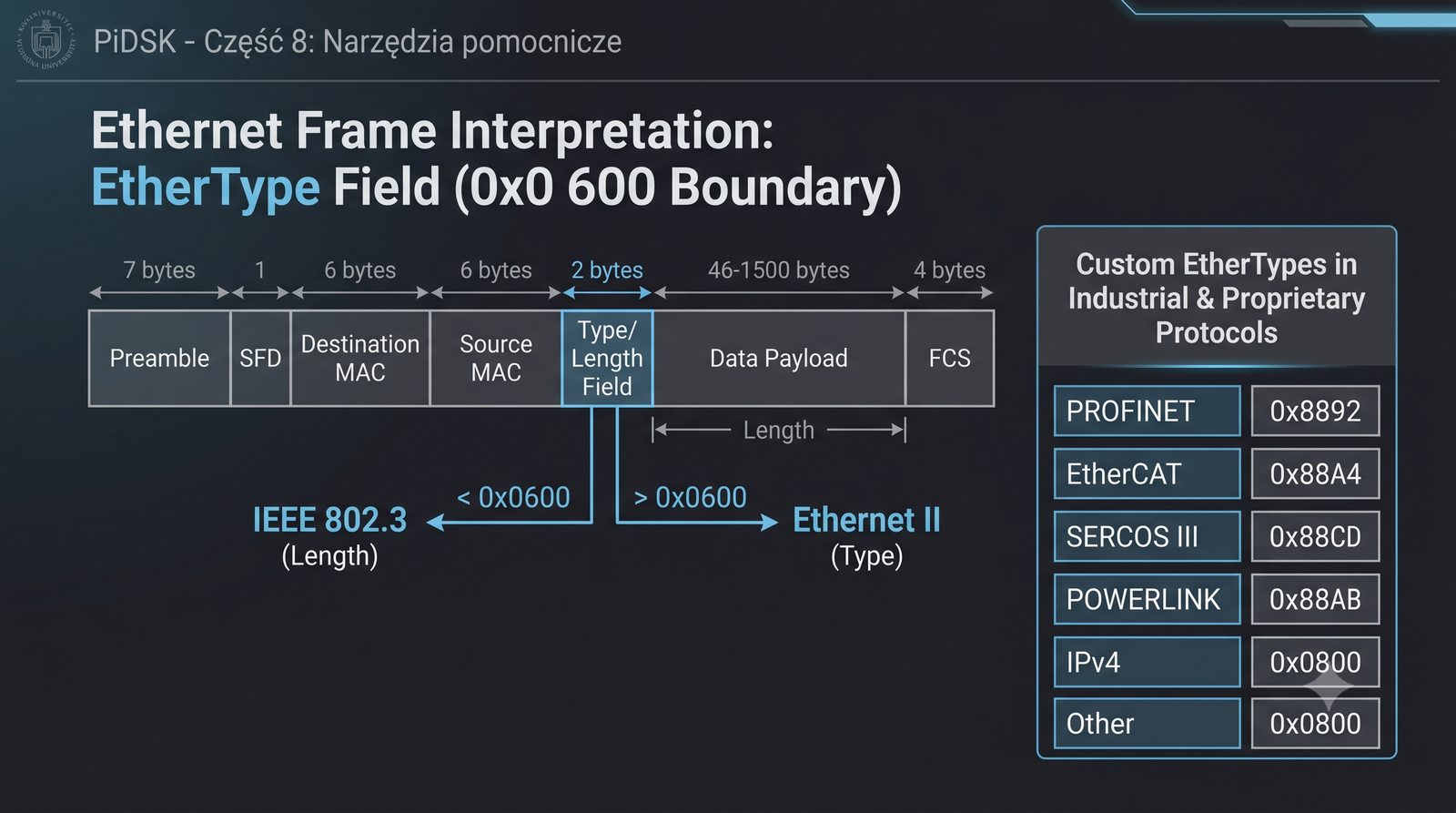
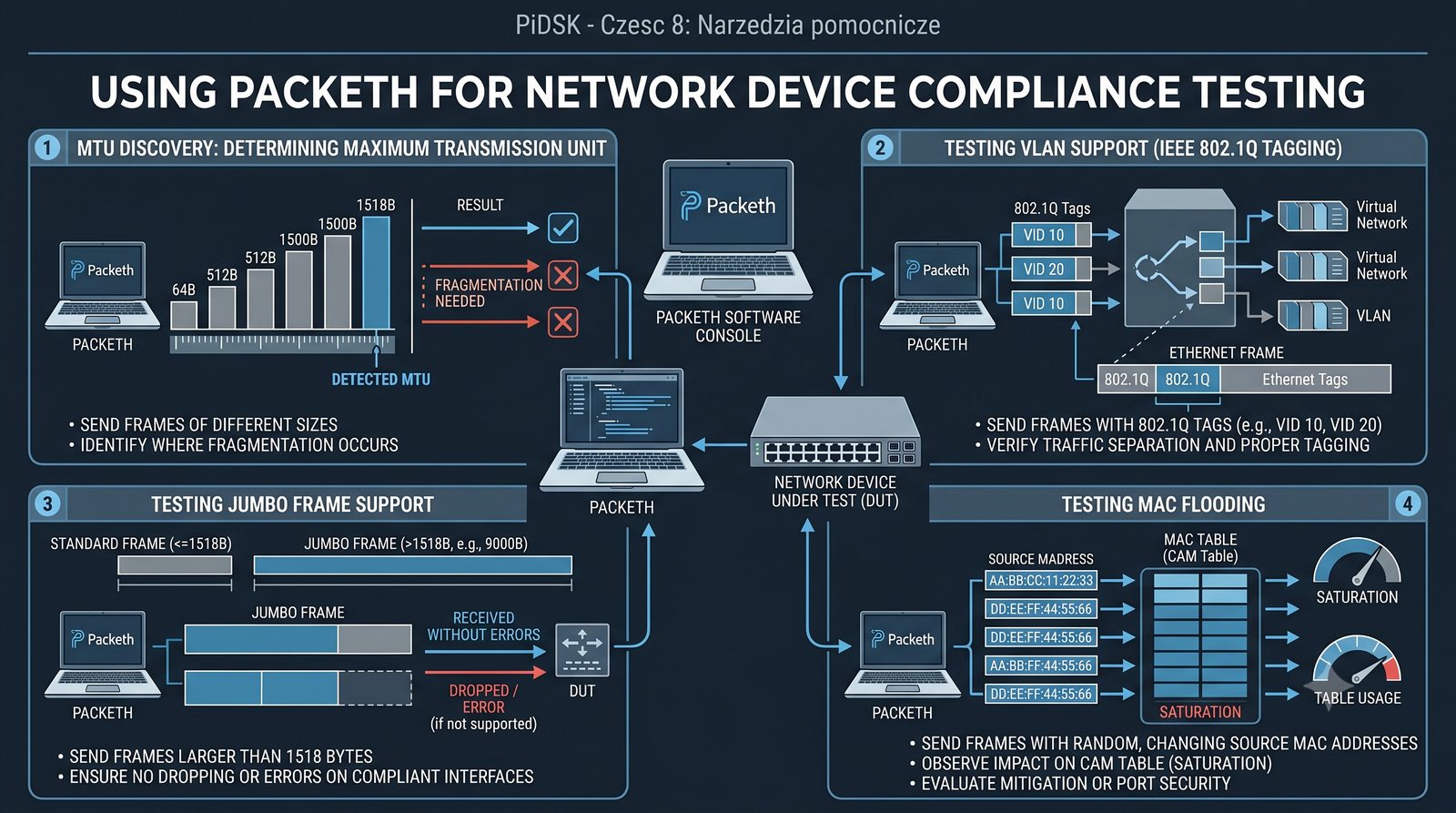
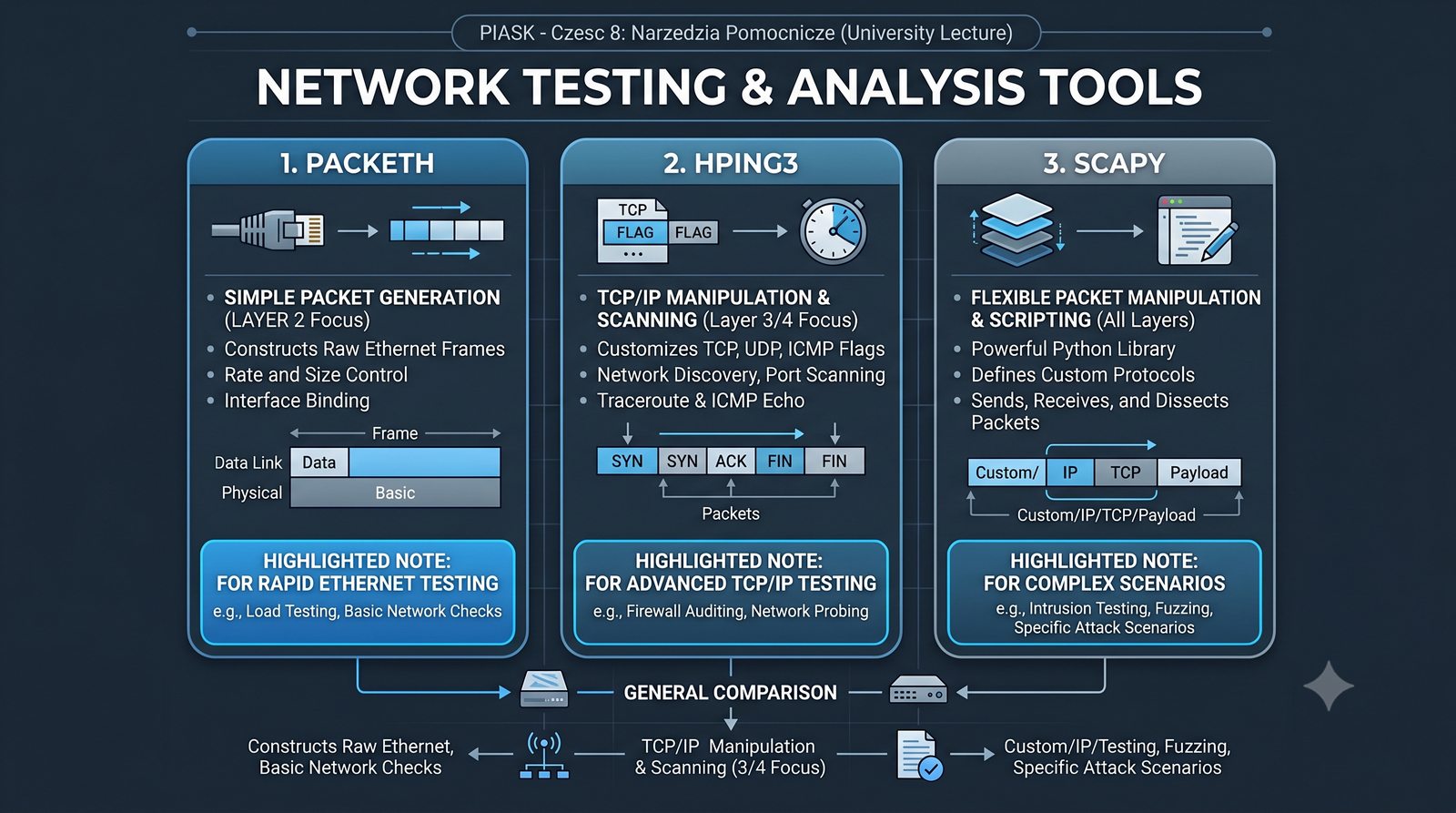
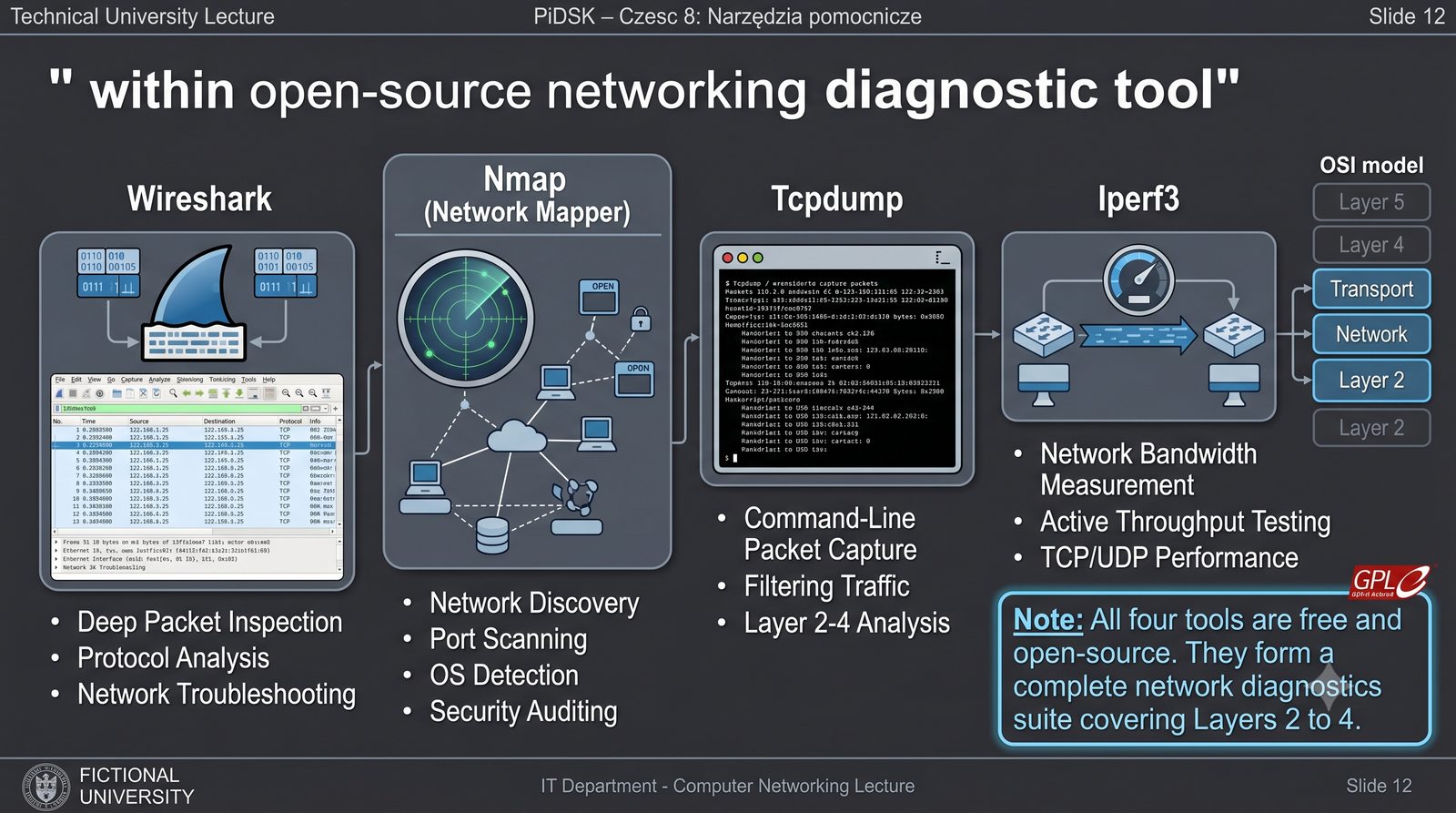
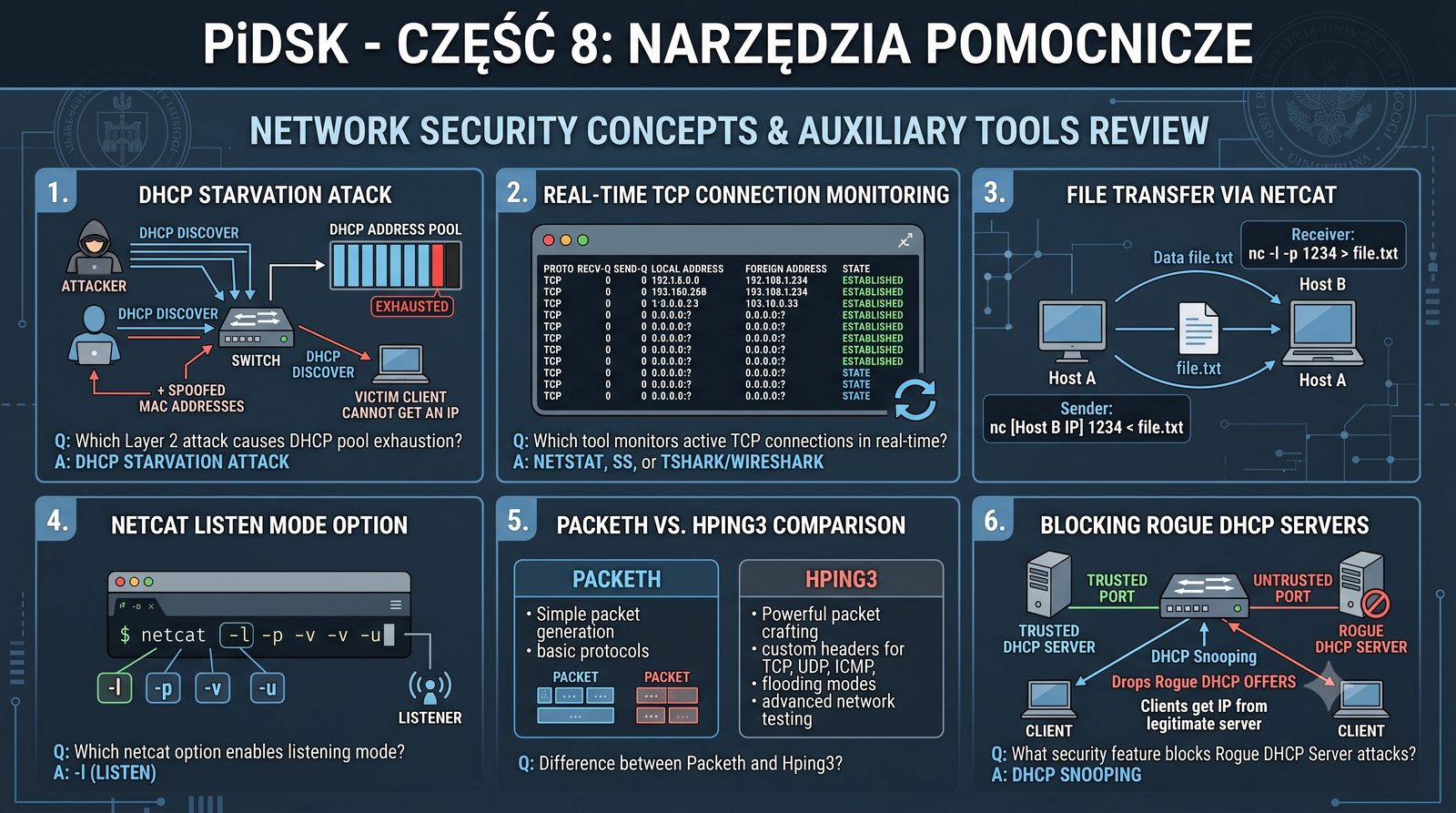
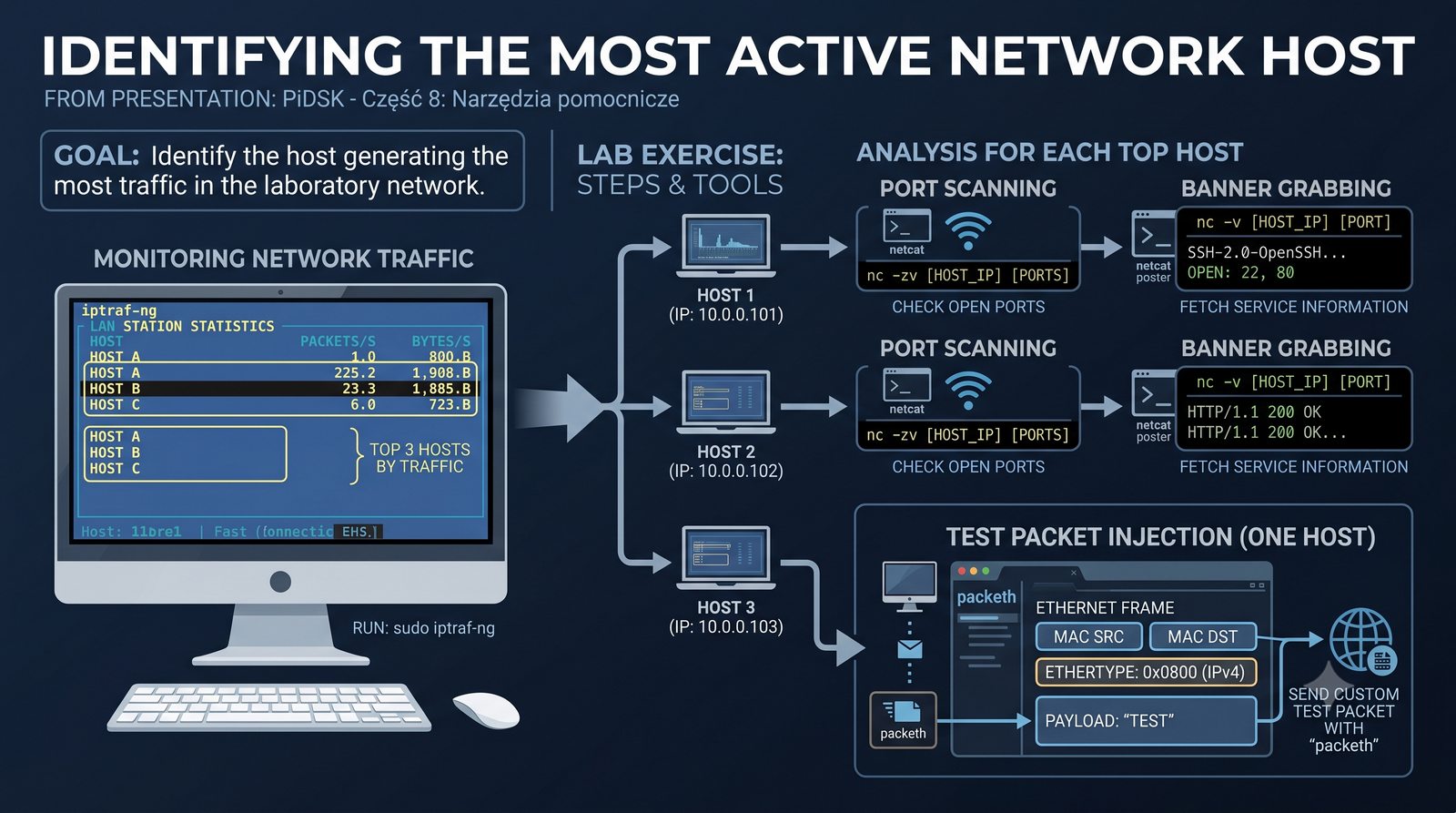
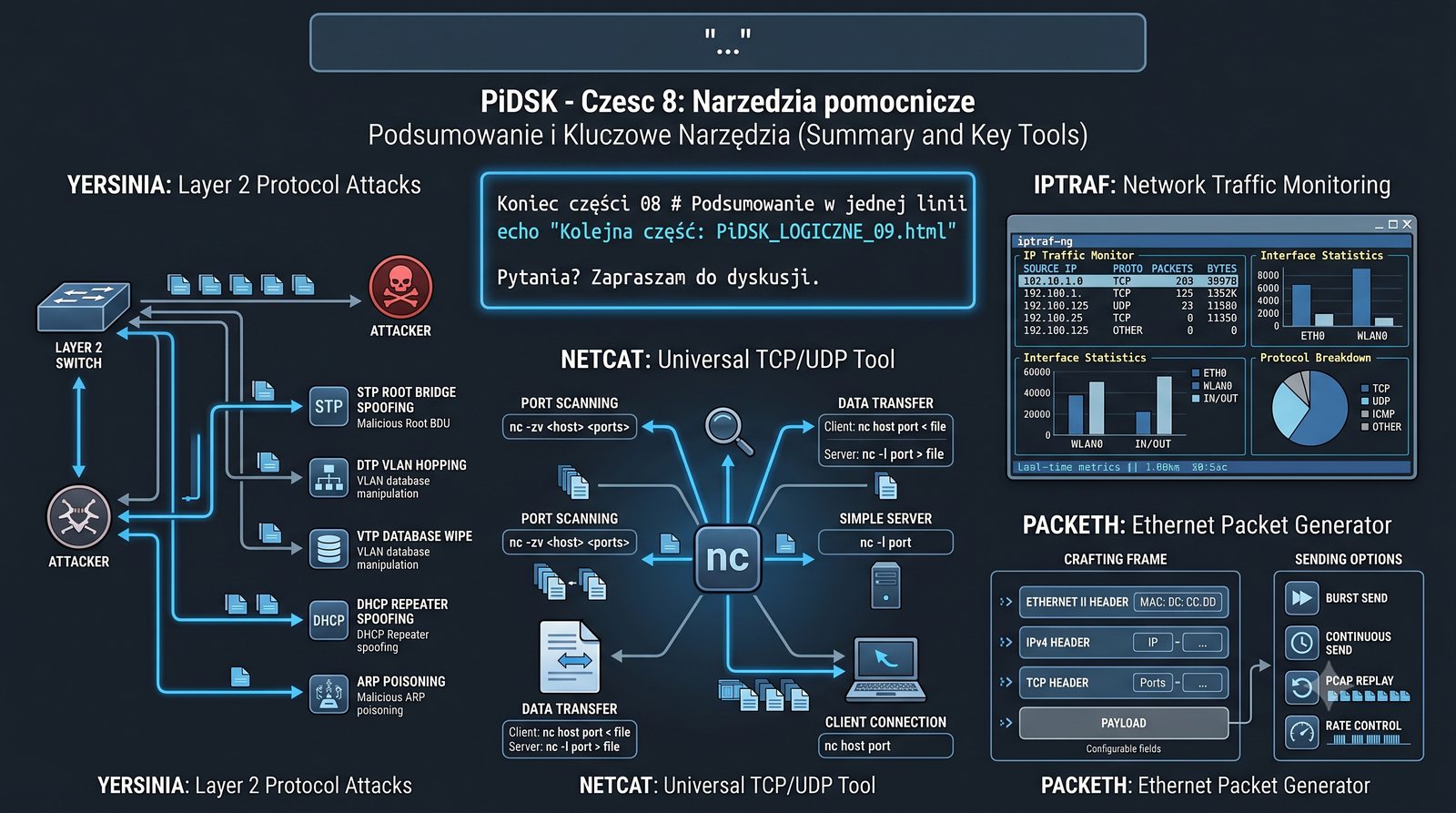
Prezentacja przedstawia cztery pomocnicze narzędzia sieciowe: Yersinia do ataków warstwy 2 (STP, CDP, DHCP, HSRP), Iptraf do monitorowania ruchu w czasie rzeczywistym, Netcat do transmisji danych przez TCP/UDP oraz Packeth do generowania ramek Ethernet. Każde z narzędzi zostało omówione pod kątem instalacji, składni i praktycznych zastosowań w diagnostyce sieci. Prezentacja zawiera również laboratoria krok po kroku oraz porównanie omawianych narzędzi.